多线程,Mutex,及OpenMP编程
1、什么是多线程?
多线程(英语:multithreading),是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率。
1)单进程单线程:一个人在一个桌子上吃菜。
2)单进程多线程:多个人在同一个桌子上一起吃菜。
3)多进程单线程:多个人每个人在自己的桌子上吃菜。
多线程的问题是多个人同时吃一道菜的时候容易发生争抢,例如两个人同时夹一个菜,一个人刚伸出筷子,结果伸到的时候已经被夹走菜了。。。此时就必须等一个人夹一口之后,在还给另外一个人夹菜,也就是说资源共享就会发生冲突争抢。
2、Mutex(互斥锁)
A mutex is a lockable object that is designed to signal when critical sections of code need exclusive access(独占访问), preventing other threads with the same protection from executing concurrently and access the same memory locations.
多线程共用同一段代码。没锁的话,我就锁上了这段代码,然后用完,我就解锁,这样别人就可以用这段代码了。为了保证数据的一致性,mutex一般用于为一段代码加锁,以保证这段代码的原子性(atomic)操作,即:要么不执行这段代码,要么将这段代码全部执行完毕。有点顺序的意思。
一个最为简单的OpenMP代码如下所示:(OpenMP运行时需要在“配置属性”--“C/C++”--"语言"中选择支持OpenMP即可,头文件加上#include
#include
#include
using namespace std;
int main()
{
clock_t t1, t2;
t1 = clock();
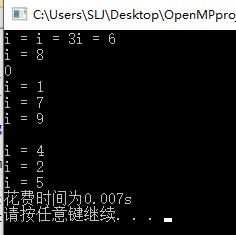
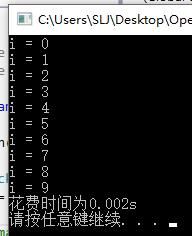
#pragma omp parallel for
for (int i = 0; i < 10; i++)
{
cout << "i = " << i << endl;
}
t2 = clock();
cout << "花费时间为" << double(t2 - t1) / CLOCKS_PER_SEC << "s" << endl;
system("pause");
}
#pragma omp parallel for
for (int i = 0; i < 100000; i++)
{
sum = sum + a[i % 10];
}
cout << "sum= " << sum << endl; int a[10] = {1,2,3,4,5,6,7,8,9,10};
int sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < 100000; i++)
{
sum = sum + a[i % 10];
} int max = 0;
int a[10] = { 11,2,33,4,113,20,321,250,689,16 };
#pragma omp parallel for
for (int i = 0; i < 10; i++)
{
int temp = a[i];
#pragma omp critical
{
if (temp > max)
max = temp;
}
}
cout << "max: " << max << endl; int sum = 0;
int a[10] = { 1,2,3,4,5,6,7,8,9,10 };
#pragma omp parallel for
for (int i = 0; i < 10; i++)
{
#pragma omp critical
{
sum = sum + a[i];
}
}
cout << "sum = " << sum << endl;