Mybatis的基础使用
1、概述及相关jar包
(1)Mybatis持久层框架,它使开发者只需要关注SQL语句本身
(2)ORM思想(Object Relation Mapping),对象关系映射。简单说,就是把数据库表和实体类对应起来操作数据库表
<!-- mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.4</version>
</dependency>
<!-- mysql连接 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.20</version>
</dependency>
<!-- log4j日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
2、基本文件配置
mybatis配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 引入外部配置文件 -->
<!-- 如果是url属性,则要写:file:///属性文件的完整路径 -->
<properties resource="db.properties"/>
<typeAliases>
<!-- 配置resultType别名的两种方式 -->
<!-- 第一种 -->
<!--<typeAlias type="com.xcm.entity.User" alias="User"/>-->
<!-- 第二种:推荐,直接给所有的实体类配置别名,别名默认为实体类的名称(不区分大小写) -->
<package name="com.xcm.entity"/>
</typeAliases>
<!-- 配置 mybatis 的环境 -->
<environments default="mysql">
<!-- 配置 mysql 的环境 -->
<environment id="mysql">
<!-- 配置事务的类型 -->
<transactionManager type="JDBC"></transactionManager>
<!-- 配置连接数据库的信息:用的是数据源(连接池) -->
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<!-- 告知 mybatis 映射配置的位置 -->
<mappers>
<!-- 三种指定mapping文件的方式 -->
<!-- 第一种 -->
<!--<mapper resource="com/xcm/mapper/UserMapper.xml"/>-->
<!-- 第二种 -->
<!--<mapper class="com.xcm.mapper.UserMapper"/>-->
<!-- 第三种:推荐,直接将所有的配置文件进行映射 -->
<package name="com.xcm.mapper"/>
</mappers>
</configuration>
数据库配置文件
driver = com.mysql.cj.jdbc.Driver
url = jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf8&userSSL=false&serverTimezone=GMT%2B8
username = root
password =
mapper文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.UserMapper">
<!--查询所有-->
<select id="findAll" resultType="User">
select * from user
</select>
<!--查询单个-->
<select id="selectById" parameterType="Long" resultType="User">
select * from user where id = #{id}
</select>
<!-- 根据用户名模糊查询 -->
<select id="selectUserLikeName" parameterType="String" resultType="User">
select * from user where username like '%${value}%'
</select>
<!-- 根据用户名查询 -->
<select id="selectUserByName" parameterType="User" resultType="User">
select * from user where username = '${user.username}'
</select>
</mapper>
Mapper 配置文件事项:
①Mybatis的映射配置文件位置必须和dao接口的包结构相同
②映射配置的mapper标签和namespace属性的取值必须是到接口全限定类名
③配置文件的操作配置(select)id属性取值必须是到接口的方法名
注意:不管采用的是xml配置方式还是注解方式,mybatis都是支持写dao实现类的,但是只在开发中越简便越好,不写实现类
测试代码
@Test
public void testFindALl() throws IOException {
// 1.读取配置文件
InputStream is = Resources.getResourceAsStream("mybatis-config.xml");
// 2.创建SqlSessionFactory的构建者对象
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
// 3.使用构建者创建 SqlSessionFactory 对象
SqlSessionFactory factory = builder.build(is);
// 4.使用 SqlSessionFactory 创建 SqlSession 对象
SqlSession session = factory.openSession();
// 5.使用SqlSession创建mapper接口的代理对象
UserMapper userMapper = session.getMapper(UserMapper.class);
// 6.使用代理对象执行查询所有方法
List<User> users = userMapper.findAll();
for (User user : users){
System.out.println(user.getUsername());
}
// 7.释放资源
session.close();
is.close();
}
3、#{} 与 ${} 的区别
| #{} | ${} | |
|---|---|---|
| 用法 | #{}:为参数占位符?,即sql预编译 | ${}为字符串替换, 即字符串拼接 |
| 参数类型 | POJO或者简单类 | POJO或者简单类型 |
| 参数名称 | 如果parameterType传输单个简单类型,名称可以是value或者其他 | 如果parameterType传输单个简单类型,参数名称只能是value,即 ${value} |
${value} 源码分析
@Override
public String handleToken(String content) {
Object parameter = context.getBindings().get("_parameter");
if (parameter == null) {
context.getBindings().put("value", null);
} else if (SimpleTypeRegistry.isSimpleType(parameter.getClass())) {
context.getBindings().put("value", parameter);
}
Object value = OgnlCache.getValue(content, context.getBindings());
String srtValue = value == null ? "" : String.valueOf(value); // issue #274 return "" instead of "null"
checkInjection(srtValue);
return srtValue;
}
由源码可以看出,如果由 parameterType 传输单个简单类型值,${} 括号中只能是 value。参数如果是 POJO 类型,在 Mapper 接口中用 @Param 指定参数名称,然后在 ${} 写 ognl 表达式,如(user.username)。
4、处理POJO属性与数据库字段不一致的的情况
第一种:直接改sql语句
select id as userId, name as userName, birthday as userBirthday from user
第二种:使用 resultMap
XML配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.User2Mapper">
<resultMap id="userMap" type="User2">
<id property="userId" column="id"/>
<result property="userBirthday" column="birthday"/>
</resultMap>
<!--查询所有-->
<select id="findAll" resultMap="userMap">
select * from user
</select>
</mapper>
5、VO对象作为查询条件
VO类
@Data
public class UserVo {
private User2 user;
}
mapper 接口与 XML 配置
public interface User2Mapper {
User2 selectUserByVo(UserVo vo);
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.User2Mapper">
<resultMap id="userMap" type="User2">
<id property="userId" column="id"/>
<result property="userBirthday" column="birthday"/>
</resultMap>
<!-- Vo -->
<select id="selectUserByVo" parameterType="UserVo" resultMap="userMap">
<!-- #{user.userId} 是一个 ognl 表达式 -->
select * from user where id = #{user.userId}
</select>
</mapper>
ognl 表达式:
它是 apache 提供的一种表达式语言,全称是:Object Graphic Navigation Language 对象图导航语言它是按照一定的语法格式来获取数据的。语法格式就是使用 #{对象.对象} 的方式
#{user.username}它会先去找 user 对象,然后在 user 对象中找到 username 属性,并调用getUsername()方法把值取出来。
6、selectKey
XML方式
<!-- 添加用户 -->
<insert id="addUser" parameterType="User">
<!--配置插入操作后,获取数据的id-->
<!--keyProperty: 对应实体类的属性,若存在多个,则使用逗号分隔;
keyColumn: 对应数据库中的字段,若存在多个,则使用逗号分隔;
resultType: 对应返回的参数类型;
order: 表示什么时候执行(在插入操作之后执行)-->
<selectKey keyProperty="id" keyColumn="id" resultType="Long" order="AFTER" >
select last_insert_id()
</selectKey>
insert into user(id, username, birthday) values (#{id}, #{username}, #{birthday})
</insert>
注意: 以上插入语句是数据库自动生成主键,所以拿不到主键。只能存在于insert或update的子标签中,一般不建议使用。
7、数据库连接池
(1)连接池:减少了获取连接所消耗的时间
Mybatis中的连接池提供了3种配置,配置的位置在主配置文件下的dataSource标签中的type属性
POOLED: 采用传统的javax.sql.DataSource规范的连接池,mybatis做了实现
UNPOOLED: 采用传统的javax.sql.DataSource规范的连接池,但是没有池的思想
JNDI: 采用服务器提供的JNDI技术实现,来获取DataSource对象,不同的服务器所能拿到的DataSource是不一样的。注意:如果不是web或者maven工程是不能使用的,Tomcat采用的连接池是dbcp。
(2)Mybatis 中 DataSource 的存取
MyBatis 是 通 过 工 厂 模 式 来 创 建 数 DataSource 对 象 的 , MyBatis 定 义 了 抽 象 的 工 厂接口:org.apache.ibatis.datasource.DataSourceFactory,通过其 getDataSource() 方法返回数据源 DataSource。
MyBatis 创建了 DataSource 实例后,会将其放到 Configuration 对象内的 Environment 对象中, 供以后使用。
(3)Mybatis 中连接的获取过程分析
当我们需要创建 SqlSession 对象并需要执行 SQL 语句时,这时候 MyBatis 才会去调用 dataSource 对象
来创建java.sql.Connection对象。也就是说,java.sql.Connection对象的创建一直延迟到执行SQL语句
的时候。
@Test
public void testSql() throws Exception {
InputStream in = Resources.getResourceAsStream("SqlMapConfig.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
SqlSession sqlSession = factory.openSession();
List<User> list = sqlSession.selectList("findUserById",41);
System.out.println(list.size());
}
只有当第 4 句 sqlSession.selectList(“findUserById”),才会触发 MyBatis 在底层执行下面这个方法来创建 java.sql.Connection 对象。
在 PooledDataSource 中找到如下 popConnection()方法,如下所示:
/**
* This is a simple, synchronous, thread-safe database connection pool.
*
* @author Clinton Begin
*/
public class PooledDataSource implements DataSource {
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null) {
synchronized (state) {
if (!state.idleConnections.isEmpty()) {
// Pool has available connection
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {
// Pool does not have available connection
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// Can create new connection
conn = new PooledConnection(dataSource.getConnection(), this);
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {
// Cannot create new connection
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// Can claim overdue connection
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {
/*
Just log a message for debug and continue to execute the following
statement like nothing happened.
Wrap the bad connection with a new PooledConnection, this will help
to not interrupt current executing thread and give current thread a
chance to join the next competition for another valid/good database
connection. At the end of this loop, bad {@link @conn} will be set as null.
*/
log.debug("Bad connection. Could not roll back");
}
}
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
// Must wait
try {
if (!countedWait) {
state.hadToWaitCount++;
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {
// ping to server and check the connection is valid or not
if (conn.isValid()) {
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
if (conn == null) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}
}
由上可以分析出 PooledDataSource 的工作原理

下面是连接获取的源代码:
public class PooledDataSource implements DataSource {
@Override
public Connection getConnection() throws SQLException {
return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
}
@Override
public Connection getConnection(String username, String password) throws SQLException {
return popConnection(username, password).getProxyConnection();
}
}
最后我们可以发现,真正连接打开的时间点,只是在我们执行SQL语句时,才会进行。其实这样做我们也可以进一步发现,数据库连接是我们最为宝贵的资源,只有在要用到的时候,才去获取并打开连接,当我们用完了就再立即将数据库连接归还到连接池中。
8、事务控制
在连接池中取出的连接,都会将调用 connection.setAutoCommit(false)方法,这样我们就必须使用 sqlSession.commit()方法,相当于使用了 JDBC 中的 connection.commit()方法实现事务提交。
9、动态SQL
(1)if 标签与 where 标签
多条件语句查询,即满足条件之一即可
<!-- 多条件查询 -->
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.UserMapper">
<select id="selectMore" parameterType="User" resultType="User">
select * from user
<where>
<if test="username != null and username != ''">
and username like #{username}
</if>
<if test="address != null">
and address like #{address}
</if>
</where>
</select>
</mapper>
List<User> selectMore(User user);
测试
@Test
public void selectMore(){
User user = new User();
user.setUsername("%熊%");
user.setAddress("%C%");
List<User> users = userMapper.selectMore(user);
for(User item : users){
System.out.println(item);
}
}
(2)foreach 标签
传入多个 id 查询用户信息,用下边两个 sql 实现:
SELECT * FROM USERS WHERE username LIKE ‘%张%’ AND (id =10 OR id =89 OR id=16)
SELECT * FROM USERS WHERE username LIKE ‘%张%’ AND id IN (10,89,16)
创建一个QueryVo用于封装参数
①封装查询条件
@Data
public class UserQueryVo {
User user;
List<Integer> ids;
}
②mapper配置
List<User> selectByIds(UserQueryVo vo);
<!-- SQL 语句:
select 字段 from user where id in (?)
<foreach>标签用于遍历集合,它的属性:
collection:代表要遍历的集合元素,注意编写时不要写#{}
open:代表语句的开始部分
close:代表结束部分
item:代表遍历集合的每个元素,生成的变量名
sperator:代表分隔符 -->
<select id="selectByIds" parameterType="UserQueryVo" resultType="User">
select * from user
<where>
<if test="ids != null and ids.size() > 0">
<foreach collection="ids" open="id in (" close=")" item="uid" separator=",">
#{uid}
</foreach>
</if>
<if test="user.username != null">
and username like #{user.username}
</if>
</where>
</select>
测试
@Test
public void selectByIds(){
UserQueryVo vo = new UserQueryVo();
User user = new User();
user.setUsername("%熊%");
vo.setUser(user);
List<Integer> ids = new ArrayList<Integer>();
ids.add(1);
ids.add(3);
ids.add(9);
vo.setIds(ids);
List<User> users = userMapper.selectByIds(vo);
for(User item : users){
System.out.println(item);
}
}
10、简化编写的 SQL 片段
Sql 中可将重复的 sql 提取出来,使用时用 include 引用即可,最终达到 sql 重用的目的。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.UserMapper">
<sql id="userAll">
select * from user
</sql>
<!--查询所有-->
<select id="findAll" resultType="User">
<include refid="userAll"/>
</select>
</mapper>
11、联表查询
一对一查询(多对一)有两种方式
(1)定义一个专门的 PO 类对两张表联合查询后的结果进行封装,其中定义了 sql 查询结果集所有的字段。优点是简单易用
(2)使用 resultMap,定义专门的 resultMap 用于映射一对一查询结果。
如一个账号只能有一个用户
① 在 Account 类中加入 User 类的对象作为 Account 类的一个属性。
@Data
public class Account {
private Long id;
private Long uid;
private Double money;
private User user;
}
② Mapper配置
List<Account> selectList();
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.AccountsMapper">
<resultMap id="accountMap" type="Account">
<id property="id" column="aid"/>
<result property="uid" column="uid"/>
<result property="money" column="money"/>
<!-- 一对一关系, association 的属性
property:指定映射到的实体类对象属性,与表字段一一对应;
column:指定表中对应的字段(外键);
javaType:指定映射到实体对象属性的类型;
select:指定引入嵌套查询的子SQL语句,该属性用于关联映射中的嵌套查询;
fetchType:指定在关联查询时是否启用延迟加载。该属性有lazy和eager两个属性值,默认值为lazy(即默认关联映射延迟加载)。
-->
<association property="user" column="uid" javaType="User">
<id property="id" column="uid"/>
<result property="username" column="username"/>
<result property="address" column="address"/>
</association>
</resultMap>
<select id="selectList" resultMap="accountMap">
select a.id as aid, a.money, u.id as uid, u.username, u.address
from accounts a
join user u
on a.uid = u.id
</select>
</mapper>
一对多查询
一个用户可以有多个用户
① User 类加入 List
@Data
public class User {
private Long id;
private String username;
private Date birthday;
private String address;
private List<Account> accounts;
}
② Mapper 配置
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.UserMapper">
<resultMap id="userMap" type="User">
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="address" column="address"/>
<!-- 一对多查询,collection
<collection>子元素的属性大部分与<association>元素相同,但其还包含一个特殊属性 ofType,
ofType属性与javaType属性对应,它用于指定实体对象中集合类属性所包含的元素类型。
property指的是类属性,
column指的是表字段(外键),
select表示嵌套的子查询,
ofType表示关联的集合类属性类型。
-->
<collection property="accounts" ofType="Account">
<id property="id" column="aid"/>
<result property="uid" column="uid"/>
<result property="money" column="money"/>
</collection>
</resultMap>
<!--查询所有-->
<select id="findAll" resultMap="userMap">
select u.id, u.username, u.address, a.id as aid, a.uid, a.money
from user u
left join accounts a
on u.id = a.uid
</select>
</mapper>
多对多查询
一般是通过一个中间表把两张表作连接,可以看成双向的多对多关系
如用户和角色的关系
② Mapper配置(和一对多没有差别,就 sql 语句有差别,因为是利用中间表作连接的)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.RoleMapper">
<resultMap id="roleMap" type="Role">
<id property="id" column="id"/>
<result property="name" column="name"/>
<collection property="users" ofType="User">
<id property="id" column="uid"/>
<result property="username" column="username"/>
</collection>
</resultMap>
<select id="findAll" resultMap="roleMap">
select r.id, r.name, u.id as uid, u.username
from role r
left join user_role ur
on r.id = ur.rid
left join user u
on u.id = ur.uid
</select>
</mapper>
12、延迟加载策略
延迟加载:
就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。延迟加载也称懒加载.
好处:
先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速度要快。
坏处:
因为只有当需要用到数据时,才会进行数据库查询,这样在大批量数据查询时,因为查询工作也要消耗时间,所以可能造成用户等待时间变长,造成用户体验下降。
实现方式:
mybatis可以使用了resultMap来实现一对一,一对多,多对多关系的操作。主要是通过 association、collection 实现一对一及一对多映射。association、collection 具备延迟加载功能。
具体代码:
首先,开启mybatis对延迟加载的支持

<!-- 这是 MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为。 -->
<settings>
<!-- 开启延迟加载的支持 -->
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="true"/>
</settings>
(1)使用 assocation 实现延迟加载
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.AccountMapper">
<resultMap id="accountMap" type="Account">
<id property="id" column="id"/>
<result property="money" column="money"/>
<!--select: 填写我们要调用的 select 映射的 id
column : 填写我们要传递给 select 映射的参数
-->
<association property="user" column="uid" select="com.xcm.mapper.UserMapper.findById" javaType="User">
<id property="id" column="id"/>
<result property="username" column="username"/>
</association>
</resultMap>
<select id="findAll" resultMap="accountMap">
select * from account
</select>
</mapper>
(2)使用 collection 实现延迟加载
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.UserMapper">
<resultMap id="userMap" type="User">
<id property="id" column="id"/>
<result property="username" column="username"/>
<!-- collection 是用于建立一对多中集合属性的对应关系
ofType 用于指定集合元素的数据类型
select 是用于指定查询账户的唯一标识(账户的 dao 全限定类名加上方法名称)
column 是用于指定使用哪个字段的值作为条件查询
-->
<collection property="accounts" column="id" select="com.xcm.mapper.AccountMapper.findByUid" ofType="Account">
<id property="id" column="id"/>
<result property="money" column="money"/>
</collection>
</resultMap>
<select id="findAll" resultMap="userMap">
select * from user
</select>
<select id="findById" parameterType="Long" resultType="User">
select * from user where id = #{id}
</select>
</mapper>
13、缓存
像大多数的持久化框架一样,Mybatis 也提供了缓存策略,通过缓存策略来减少数据库的查询次数,从而提高性能。
Mybatis 中缓存分为一级缓存,二级缓存。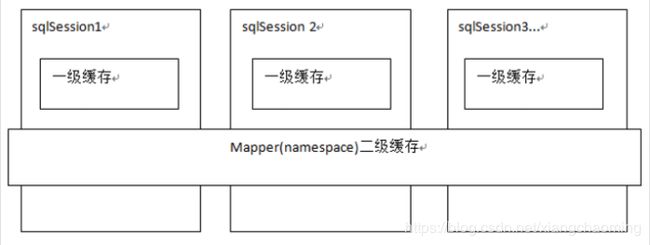
一级缓存
证明一级缓存存在
public class CacheTest {
InputStream in;
SqlSessionFactory factory;
SqlSession sqlSession;
@Before
public void init() throws IOException {
in = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
factory = builder.build(in);
sqlSession = factory.openSession();
}
@After
public void destroy() throws IOException {
//sqlSession.commit();
sqlSession.close();
in.close();
}
@Test
public void selectList(){
SqlSession sqlSession1 = factory.openSession();
UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);
User user1 = mapper1.findById(1L);
User user2 = mapper1.findById(1L);
System.out.println(user1 == user2); // true
}
}
一级缓存是 SqlSession 范围的缓存,当调用 SqlSession 的修改,添加,删除,commit(),close()等方法时,就会清空一级缓存。
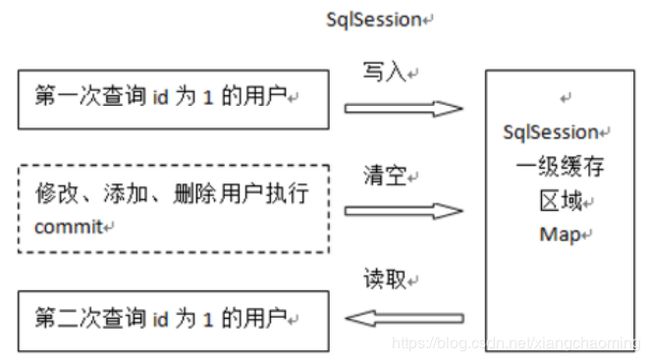
第一次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,如果没有,从数据库查询用户信息。
得到用户信息,将用户信息存储到一级缓存中。
如果 sqlSession 去执行 commit 操作(执行插入、更新、删除),清空 SqlSession 中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
第二次发起查询用户 id 为 1 的用户信息,先去找缓存中是否有 id 为 1 的用户信息,缓存中有,直接从缓存中获取用户信息。
二级缓存
二级缓存是 mapper 映射级别的缓存,多个 SqlSession 去操作同一个 Mapper 映射的 sql 语句,多个 SqlSession 可以共用二级缓存,二级缓存是跨 SqlSession 的。
第一步:开启二级缓存
<settings>
<!-- 开启二级缓存的支持 -->
<setting name="cacheEnabled" value="true"/>
</settings>
因为 cacheEnabled 的取值默认就为 true,所以这一步可以省略不配置。为 true 代表开启二级缓存;为false 代表不开启二级缓存。
第二步:Mapper配置
标签表示当前这个 mapper 映射将使用二级缓存,区分的标准就看 mapper 的 namespace 值。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xcm.mapper.UserMapper">
<!-- 开启二级缓存的支持 -->
<cache></cache>
<resultMap id="userMap" type="User">
<id property="id" column="id"/>
<result property="username" column="username"/>
<!-- collection 是用于建立一对多中集合属性的对应关系
ofType 用于指定集合元素的数据类型
select 是用于指定查询账户的唯一标识(账户的 dao 全限定类名加上方法名称)
column 是用于指定使用哪个字段的值作为条件查询
-->
<collection property="accounts" column="id" select="com.xcm.mapper.AccountMapper.findByUid" ofType="Account">
<id property="id" column="id"/>
<result property="money" column="money"/>
</collection>
</resultMap>
<select id="findAll" resultMap="userMap">
select * from user
</select>
<!-- 中设置 useCache=”true”代表当前这个 statement 要使用二级缓存,如果不使用二级缓存可以设置为 false。 -->
<!-- 注意:针对每次查询都需要最新的数据 sql,要设置成 useCache=false,禁用二级缓存。 -->
<select id="findById" parameterType="Long" resultType="User" useCache="true">
select * from user where id = #{id}
</select>
</mapper>
第三步:测试
public class CacheTest {
InputStream in;
SqlSessionFactory factory;
SqlSession sqlSession;
@Before
public void init() throws IOException {
in = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
factory = builder.build(in);
sqlSession = factory.openSession();
}
@After
public void destroy() throws IOException {
//sqlSession.commit();
sqlSession.close();
in.close();
}
@Test
public void selectList2(){
SqlSession sqlSession1 = factory.openSession();
SqlSession sqlSession2 = factory.openSession();
UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);
User user1 = mapper1.findById(1L);
sqlSession1.close(); // 一级缓存消失
User user2 = mapper2.findById(1L);
sqlSession2.close();
System.out.println(user1);
System.out.println(user2);
System.out.println(user1 == user2);
}
}
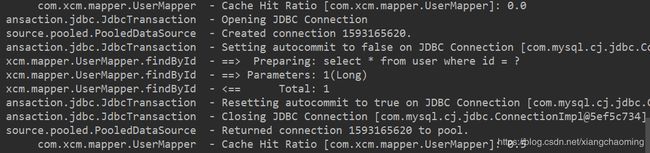
经过上面的测试,我们发现执行了两次查询,并且在执行第一次查询后,我们关闭了一级缓存,再去执行第二次查询时,我们发现并没有对数据库发出 sql 语句,所以此时的数据就只能是来自于我们所说的二级缓存。
特别注意:
当我们在使用二级缓存时,所缓存的类一定要实现 java.io.Serializable 接口,这种就可以使用序列化方式来保存对象。
@Data
public class User implements Serializable {
private Long id;
private String username;
private Date birthday;
private String address;
private List<Account> accounts;
}
14、注解开发
(1)常用注解说明
@Insert: 实现新增
@Update: 实现更新
@Delete: 实现删除
@Select: 实现查询
@Result: 实现结果集封装
@Results: 可以与@Result 一起使用,封装多个结果集
@ResultMap: 实现引用@Results 定义的封装
@One: 实现一对一结果集封装
@Many: 实现一对多结果集封装
@SelectProvider: 实现动态 SQL 映射
@CacheNamespace: 实现注解二级缓存的使用
(2)简单查询
此处的 POJO 属性与数据库字段名称不一致,这里还使用了 ResultMap、SelectKey
public interface UserMapper {
/**
* 查询所有用户
* @return
*/
@Select("select * from user")
@Results(id = "userMap",
value = {
@Result(id = true, property = "userId", column = "id"),
@Result(property = "userName", column = "username"),
@Result(property = "userBirthday", column = "birthday"),
@Result(property = "userAddress", column = "address")
})
List<User> findAll();
/**
* 根据id查询用户
* @param id
* @return
*/
@Select("select * from user where id = #{id}")
@ResultMap("userMap")
User findById(Long id);
/**
* 保存用户
* @param user
* @return
*/
@Insert("insert into user(id, username, birthday, address) values (#{userId}, #{userName}, #{userBirthday}, #{userAddress})")
@SelectKey(keyProperty = "userId", keyColumn = "id", resultType = Long.class, before = false,
statement = { "select last_insert_id()"}
)
Long saveUser(User user);
}
(3)使用注解实现一对一复杂关系映射及延迟加载
@Results 注解
代替的是标签
该注解中可以使用单个@Result 注解,也可以使用@Result 集合
@Results({@Result(),@Result()})或@Results(@Result())
@Resutl 注解
代替了
@Result 中 属性介绍:
id 是否是主键字段
column 数据库的列名
property 需要装配的属性名
one 需要使用的@One 注解(@Result(one=@One)()))
many 需要使用的@Many 注解(@Result(many=@many)()))
@One 注解(一对一)
代替了标签,是多表查询的关键,在注解中用来指定子查询返回单一对象。
@One 注解属性介绍:
select 指定用来多表查询的 sqlmapper
fetchType 会覆盖全局的配置参数 lazyLoadingEnabled。。
使用格式:
@Result(column=" “,property=”",one=@One(select=""))
@Many 注解(多对一)
代替了
注意:聚集元素用来处理“一对多”的关系。需要指定映射的 Java 实体类的属性,属性的 javaType(一般为 ArrayList)但是注解中可以不定义;
使用格式:
@Result(property="",column="",many=@Many(select=""))
一对一延迟加载
public interface AccountMapper {
@Select("select * from account")
@Results(id = "accountMap",
value = {
@Result(id = true, property = "aId", column = "id"),
@Result(property = "aUid", column = "uid"),
@Result(property = "aMoney", column = "money"),
@Result(property = "user", column = "uid",
one = @One(select = "com.xcm.mapper.UserMapper.findById",
fetchType = FetchType.LAZY)
)
}
)
List<Account> findAll();
}
一对多延迟加载
public interface UserMapper {
/**
* 查询所有用户
* @return
*/
@Select("select * from user")
@Results(id = "userMap",
value = {
@Result(id = true, property = "userId", column = "id"),
@Result(property = "userName", column = "username"),
@Result(property = "userBirthday", column = "birthday"),
@Result(property = "userAddress", column = "address"),
@Result(property = "accounts", column = "id",
many = @Many(
select = "com.xcm.mapper.AccountMapper.findByUid",
fetchType = FetchType.LAZY
)
)
})
List<User> findAll();
}
(4)基于注解的二级缓存
@CacheNamespace(blocking=true)//mybatis 基于注解方式实现配置二级缓存
public interface IUserDao {}