飞桨学习总结
人流密度调优学习
1 数据分析
- 边界框标注
- 坐标标注
- 数据分辨率、来源场景、采集角度、人与人之间遮挡等是否不同。
2 方案选择
- 回归问题
- vgg resnet
- 损失函数 均方误差等
- 分类问题
- 需要提前分好类别
- 交叉熵损失
- 目标检测问题
- 精心设计网络结构
- 损失也比较复杂
- 密度图回归
- 均方误差损失
- 融合方法
- 目标检测+分类
- 目标检测+回归 等
3 数据预处理
1 数据增强
- 改角度
- 改亮度
- 该对比度
- 改变饱和度
- 针对性增强,以标记数据的为中心圈出一个小区域;或对边缘图像做填充
- 针对人流密度:
- 多尺度采样
- 高密度采样
- 目前有opencv等库
4 训练调优
1 梯度消失梯度爆炸
- 1、更换激活函数
- relu
- 2、ResNetBlock
- 残差块
- 3、Batch normalization
- 解决梯度消失
- 4、梯度截断
- 通过截断控制网络在一定范围内学习
- 5、与训练+微调
2 过拟合
- 1、数据增强
- 离线 便于对比
- 在线 在batch读取前进行增强,保证训练前数据不同
- 2、提前停止
- 3、权重正则化
- L1 使网络偏系数 某些特征不关注
- L2 所有特征关注相同
- 4、dropout
- 给一定概率使权重失效
3 参数调优其他方法
- 1、学习率
- warmup
- 2、batchsize
- batchsize 不是越大越好,虽然速度更快;batchsize过大容易陷入局部最优解,不同平台不同。
- 3、优化函数
- adam
- sgd
4 方法介绍 for 人流密度检测
- MCNN
- 用不同卷积核来表示图像中人的大小,
- CSRnet
- 空洞卷积-改变感受野
- RCNN
- 区域拉伸
- 边界框回归
- FastRCNN
- 多任务损失
- ROI Pooling
- 一阶段经典
- 区域大小不同
- Faster RCNN
- RPN网络提出候选区域
- SSD-Default box
- 直接对默认框回归
- 多层预测解决目标大小不同
- SSD-损失函数
- 分类损失
- 交叉熵
- 定位损失
- L1
- 分类损失
5 python 库
argument opencv paddlecv
前辈分享
避免过拟合
- 减少网络参数量<1000 避免过拟合
- 仅保存验证集上保存最好的模型
- 学习率调度器 warmup等
- 学习率难以下降 收敛慢
- 网络结构和超参数影响模型效果
Paddle 黑科技
- Forward Recomputation Backpropagation
- Paddle hub
- PaddleX
- 图形化全流程开发工具
学习心得体会
我的水平:看过李宏毅的机器学习,了解过深度学习的一些技术,学过一些tensorflow,但是云里雾里。
学习目的:最近这个月突然想进行自己的工程能力培养,于是参加了百度的七天CV课,内容是讲一些基础,然后直接上手代码。这个和我的目的差不多,看看【深度学习】这个东西到底长什么样子,不是说深度学习网络结构长什么样子,而是代码长什么样子。
感受超赞:
首先平台用Paddle的平台,类似jupyterbook还有终端,重点!提供免费的GPU V100,很靓。不多说,上图:
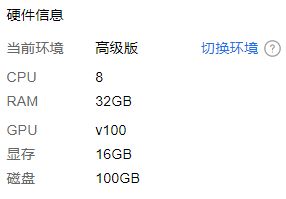
其次,Paddle自研库,我没有很熟悉TF、pytorch,仅对一个新人来讲Paddle还比较友好并没有很难理解,关键是文档全中文,文档里面还会有实例代码。
Paddle官网文档
最后,老师讲课和群内氛围。这两项在我接触到的免费训练营中非常负责的训练营,这个怎么讲呢?
第一,讲课老师和班主任分工合作,非常专业;
第二,群内实时答疑,答疑的不止老师,还有一些比你完成的快的学员,就这个氛围,超过了很多所谓学习群;
第三,百度官方给提供很多奖品,实物奖品包邮到家,这一点说实话,能学习还能得奖品已经足够吸引我在这上面用心花费时间了。
在这样得环境中,多少你都会学到自己想学的东西,个人学习最容易遇到问题没人帮助解决,而这里真的有。
其实不仅这些,更多的是看到了国内优秀的深度学习平台的发展,据说2.0版本提升更大,无论百度团队,还是其它团队,希望大家都加油,使2020变得更好!