用于视觉问答的与问题无关的注意模型《Question-Agnostic Attention for Visual Question Answering》
目录
一、文献摘要介绍
二、网络框架介绍
三、实验分析
四、结论
这是视觉问答论文阅读的系列笔记之一,本文有点长,请耐心阅读,定会有收货。如有不足,随时欢迎交流和探讨。
一、文献摘要介绍
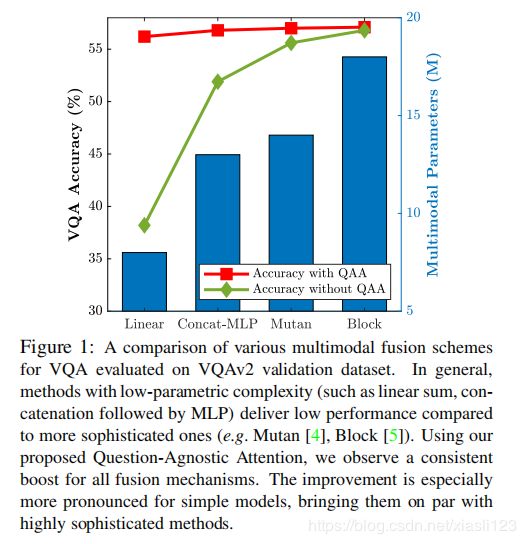
Visual Question Answering (VQA) models employ attention mechanisms to discover image locations that are most relevant for answering a specifific question. For this purpose, several multimodal fusion strategies have been proposed, ranging from relatively simple operations (e.g. linear sum) to more complex ones (e.g., Block ). The resulting multimodal representations define an intermediate feature space for capturing the interplay between visual and semantic features, that is helpful in selectively focusing on image content. In this paper, we propose a question-agnostic attention mechanism that is complementary to the existing question-dependent attention mechanisms. Our proposed model parses object instances to obtain an ‘object map’ and applies this map on the visual features to generate Question-Agnostic Attention (QAA) features. In contrast to question-dependent attention approaches that are learned end-to-end, the proposed QAA does not involve question-specifific training, and can be easily included in almost any existing VQA model as a generic light-weight pre-processing step, thereby adding minimal computation overhead for training. Further, when used in complement with the question-dependent attention, the QAA allows the model to focus on the regions containing objects that might have been overlooked by the learned attention representation. Through extensive evaluation on VQAv1, VQAv2 and TDIUC datasets, we show that incorporating complementary QAA allows state-of-the-art VQA models to perform better, and provides significant boost to simplistic VQA models, enabling them to performance on par with highly sophisticated fusion strategies (see Fig. 1).
视觉问答(VQA)模型采用注意力机制来发现与回答特定问题最相关的图像位置。为此目的,已经提出了几种多峰融合策略,范围从相对简单的操作(例如线性和)到更复杂的操作(例如Block)。所得的多峰表示法定义了一个中间特征空间,用于捕获视觉特征和语义特征之间的相互作用,这有助于选择性地关注图像内容。在本文中,我们提出了一个与问题无关的注意机制,以补充现有的与问题相关的注意机制。我们提出的模型解析对象实例以获得“对象图”,并将此图应用于视觉特征以生成与问题无关的注意(QAA)特征。与端到端学习的与问题相关的注意力方法不同,所提出的QAA不涉及针对问题的训练,并且可以作为常规的轻量级预处理步骤轻松地包含在几乎所有现有的VQA模型中,从而为训练增加了最小的计算开销。此外,当与依赖于问题的注意力配合使用时,QAA允许模型集中于包含可能被学习的注意力表示忽略的对象的区域。通过对VQAv1、VQAv2和TDIUC数据集的广泛评估,我们表明,结合互补的QAA可以使最先进的VQA模型性能更好,并为简化的VQA模型提供显著的提升,使其性能与高度复杂的融合策略相当(见图1)。
二、网络框架介绍
给定有关图像  的问题
的问题 ![]() ,为VQA任务设计的AI代理将根据从训练示例中获得的学习预测答案
,为VQA任务设计的AI代理将根据从训练示例中获得的学习预测答案 ![]() 。基准VQA模型将此任务框架化为候选答案集中的多类分类问题,并且这些模型学会预测给定图像问题(IQ)对的正确答案。 此任务可以表述为:
。基准VQA模型将此任务框架化为候选答案集中的多类分类问题,并且这些模型学会预测给定图像问题(IQ)对的正确答案。 此任务可以表述为:
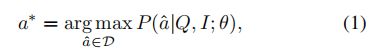
其中 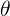 表示模型参数,而
表示模型参数,而![]() 是根据候选答案集
是根据候选答案集![]() 的字典预测的,下图是作者提出模型的网络框架。
的字典预测的,下图是作者提出模型的网络框架。

简单的VQA模型由两个主要部分组成:(1)特征提取模块;(2)多模态特征嵌入。
模型的第一部分从图像中提取视觉特征,并从问题![]() 中提取语义特征。使用基于深度CNN的对象识别模型(例如ResNet )从图像中提取视觉特征,该模型在大规模图像识别数据集(如ImageNet )上进行了预训练,从模型的最后卷积层提取图像特征图作为视觉特征
中提取语义特征。使用基于深度CNN的对象识别模型(例如ResNet )从图像中提取视觉特征,该模型在大规模图像识别数据集(如ImageNet )上进行了预训练,从模型的最后卷积层提取图像特征图作为视觉特征![]() ,其中
,其中 ![]() 是图像在粗网格上的空间位置的索引,而
是图像在粗网格上的空间位置的索引,而![]() 是每个空间网格位置的特征嵌入维度。另一方面,为了从一个问题中提取语言特征,每个单词都被输入到一个预先训练好的编码器(如GloVe,Skip-think)中,从而得到问题单词的向量嵌入。然后,将这些向量传递到由门控循环单元(GRU)组成的语言模型,以生成语义特征
是每个空间网格位置的特征嵌入维度。另一方面,为了从一个问题中提取语言特征,每个单词都被输入到一个预先训练好的编码器(如GloVe,Skip-think)中,从而得到问题单词的向量嵌入。然后,将这些向量传递到由门控循环单元(GRU)组成的语言模型,以生成语义特征![]() 。
。
在第二部分中,提取的视觉和语义特征被组合成一个多模态表示,然后用它来最小化损失函数来预测正确答案。VQA模型利用联合嵌入函数![]() 将提取的特征融合到一个公共的多模态空间中。函数
将提取的特征融合到一个公共的多模态空间中。函数![]() 可以是一个简单的固定函数(例如线性和、连接后接MLP)或一个复杂的运算(例如多模态池或融合)。最重要的是,多模式嵌入用于使用学习的注意力机制选择性地关注视觉特征。 这种关注是从给定的问题和图像对共同获得的。 与这些注意方法不同,我们提出了一个预处理步骤,该步骤无需考虑所有输入问题即可估计注意力图。 这种无需训练的简单方法令人惊讶地给出了令人信服的结果。
可以是一个简单的固定函数(例如线性和、连接后接MLP)或一个复杂的运算(例如多模态池或融合)。最重要的是,多模式嵌入用于使用学习的注意力机制选择性地关注视觉特征。 这种关注是从给定的问题和图像对共同获得的。 与这些注意方法不同,我们提出了一个预处理步骤,该步骤无需考虑所有输入问题即可估计注意力图。 这种无需训练的简单方法令人惊讶地给出了令人信服的结果。
我们提出的与问题无关的注意力模型如图2所示。首先采用一种注意力机制,该机制通过创建一个“对象图”来关注不同的对象实例,并以此生成与问题无关的特征。与问题无关的注意力使模型能够集中于任意对象形状和对象部位,从而提高了模型注意力。与原始的CNN提取的空间网格特征映射不同,问题无关的特征通过VQA模型传递,在VQA模型中使用给定的语言查询进一步细化视觉特征。这些改进的视觉特征用于生成最终的分类预测。该模型的模块化体系结构使其能够结合来自其他VQA模型的预测,这些预测汇总了多个预测以生成给定问题的智能答案。
2.1Question-Agnostic Attention
输入图像通过预训练的实例分割模块以预测与对象实例相对应的像素。值得注意的是,我们确保预训练的网络没有看到评估数据集的任何测试图像,并且在完全不同的任务上进行了预训练(即与VQA相对的实例分割)。 这些实例具有任意的形状和大小,这使得对其进行编码变得更加困难,并且VQA模型使用实例级特征进行训练在计算上是不可行的。 为此,通过在整个图像上创建大小为 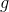 的网格来生成对象实例的粗略表示,然后将对象实例映射到该网格上。该网格的二进制表示形式称为对象图
的网格来生成对象实例的粗略表示,然后将对象实例映射到该网格上。该网格的二进制表示形式称为对象图![]() 它基本上标识了一个对象实例是否占据网格位置。
它基本上标识了一个对象实例是否占据网格位置。
2.2.Multiple Prediction Embedding
QAA的模块化体系结构使其能够共同考虑来自任何其他VQA模型的预测,以生成最终的预测向量。为了进一步验证我们提出的QAA模型的互补性,我们提供了一种简单的空间注意力机制,该机制通常在大多数VQA模型中使用,来根据问题细化视觉特征。除了用于生成与问题无关的特征的固定对象图之外,此可选模块还可用于根据问题提炼与问题无关的特征,从而提供了在QAA之上合并空间注意机制的灵活性。通过计算与问题无关的特征网格位置![]() 和
和![]() 之间的相似性度量,并通过联合嵌入函数
之间的相似性度量,并通过联合嵌入函数![]() 将它们投影到公共空间,实现了这一点。通常,这表示空间网格位置与回答该输入问题的相关性。 这种相似性度量被用作语义加权函数,称为空间注意力
将它们投影到公共空间,实现了这一点。通常,这表示空间网格位置与回答该输入问题的相关性。 这种相似性度量被用作语义加权函数,称为空间注意力![]() ,该函数对输入视觉特征的空间网格进行加权求和。 它可以表示为:
,该函数对输入视觉特征的空间网格进行加权求和。 它可以表示为:
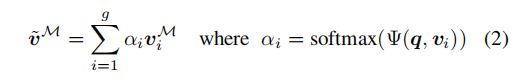
其中![]() 表示输入问题强调的与问题无关的注意力特征的组合。最后,将其与问题特征
表示输入问题强调的与问题无关的注意力特征的组合。最后,将其与问题特征![]() 进行第二次多峰嵌入,以生成预测向量
进行第二次多峰嵌入,以生成预测向量![]() ,该向量的维数与候选答案字典
,该向量的维数与候选答案字典![]() 的维数相同,任何其他VQA模型的预测都可以与我们的模型的预测连接起来。所连接的预测将通过学习如何生成
的维数相同,任何其他VQA模型的预测都可以与我们的模型的预测连接起来。所连接的预测将通过学习如何生成![]() 维最终预测向量的多层预测嵌入层传递。
维最终预测向量的多层预测嵌入层传递。
三、实验分析
我们使用在ImageNet 上经过预训练的ResNet 来提取尺寸为196×2048的图像的视觉特征。在这里,g = 196表示与图像区域相对应的14×14空间网格,而2048是每个网格位置的视觉特征的维度。 语言模型为每个问题生成![]() = 2400维特征。 首先通过由GRU组成的嵌入层对疑问词进行预处理,标记和编码,并使用经过预先训练的“skip-thought”编码器。 对于没有可选的空间注意机制的模型,输入的视觉特征在空间网格上平均,以从2048×14×14维度特征图生成2048-d特征向量,并传递给问题特征。候选答案
= 2400维特征。 首先通过由GRU组成的嵌入层对疑问词进行预处理,标记和编码,并使用经过预先训练的“skip-thought”编码器。 对于没有可选的空间注意机制的模型,输入的视觉特征在空间网格上平均,以从2048×14×14维度特征图生成2048-d特征向量,并传递给问题特征。候选答案![]() 的字典由来自VQA数据集的各个版本的前3000个频繁答案组成。将交叉熵损失最小化以从字典
的字典由来自VQA数据集的各个版本的前3000个频繁答案组成。将交叉熵损失最小化以从字典![]() 中预测正确答案。
中预测正确答案。
表1:在VQA数据集上使用互补QAA功能时,不同多模态操作的比较。

表2:将与最先进的单(非集成)VQA模型与我们提出的QAA模型进行比较,在VQAv2Test-dev和Test-std数据集上进行评估。

表3:对我们的QAA模型在TDIUC数据集上的测试集进行了评价,并与最先进的方法进行了比较。

图3:使用互补的图像问题无关注意功能的VQA准确性(右y轴)。
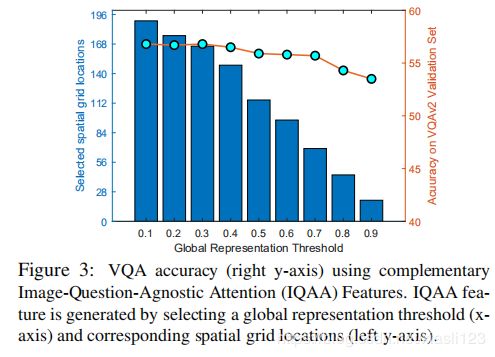
图4:对象映射的全局表示:
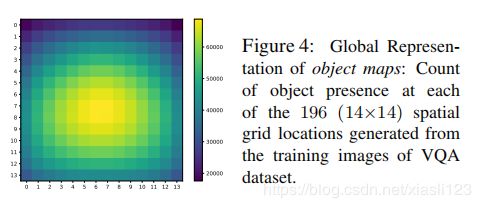
图5:关于VQAv2val-set的定性结果,以证明使用互补QAA的有效性。

四、结论
In this paper, we introduced Question-Agnostic Attention that can be used to augment existing VQA approaches. Rather than using computationally intensive methods to learn question-specific attention, our approach derives attention only from the image, based on the insight that questions generally relate to object instances. We use an object parsing model to automatically generate an Object Map, that has the same resolution as the feature map from a pre-existing classification network. The Object Map is used to mask the convolutional feature map to generate question-agnostic attention features. When high-performing computationally-intensive VQA models are augmented with QAA, it improves their accuracy to be a new state-of-the-art. When simple linear models are augmented with QAA, they preform significantly better when answering question that require a higher level of visual reasoning (e.g. activity recognition), which a simplistic model cannot learn on its own. This capability provides the simplistic (low-complexity) models a significant boost that brings them close to state-of-the-art.
在本文中,作者介绍了可用于增强现有VQA方法的与问题无关的注意力。我们的方法不是使用计算密集型方法来学习特定于问题的注意力,而是基于问题通常与对象实例相关的见解,仅从图像中获得注意力。我们使用对象解析模型自动生成一个对象映射,该对象映射的分辨率与来自现有分类网络的特征映射相同。对象图用于掩盖卷积特征图,以生成与问题无关的注意力特征。当使用QAA增强高性能的计算密集型VQA模型时,它会提高其准确性,成为最新的技术。当简单的线性模型通过QAA进行增强时,它们在回答需要更高级别的视觉推理(例如活动识别)的问题时会表现得更好,这是简单模型无法自行学习的。此功能为简化(低复杂度)模型提供了显着的提升,使它们接近最新技术。
该论文通过Mask-RCNN分离出实例对象,以达到与问题无关的目的,是个很好的方法,如果利用这个实例和问题进行融合,再查询图像区域,是不是能有点好的效果,这篇文章也是不错的思路,值得借鉴。