P-CNN: Pose-based CNN Features for Action Recognition (CNN篇)
论文题目P-CNN: Pose-based CNN Features for Action Recognition, 链接
之前看过在静态图像上做action recognition的论文, 如 Georgia Gkioxari这位大美女的论文, Contextual Action Recognition with R*CNN (可以看zhujin师兄的 blog)
和RGB视频里面的action recognition的论文, 如Recognize Complex Events from Static Images by Fusing Deep Channels (可以看zhujin师兄的 blog)
该篇论文是ICCV 2015的, 文章的核心是feature descriptors的获取.
利用现有的pose estimation的method和一些经典的feature extractor的CNN模型来获取feature descriptors.
废话不多说, 直接看图说话:
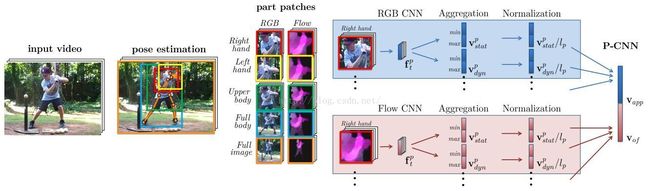
1 首先利用一些state-of-art的pose estimator来提取视频里面的每帧的pose.
2 定义parts, 如图中的upper body full body等, 并利用pose的坐标来截取每个part的patches.
这里的patches包括rgb原图和motion图.
motion图是事先计算好的, 原以为是用CNN这些网络来学习得到的, 略失望咯.
3 用一些经典已训练好的的CNN(s)模型来提取fc特征(如fc7的4096维特征)
4 用一些aggregation的方法来进一步提取特征, 使得一个视频的特征P-CNN输出纬度是固定大小的..
这里的aggregation的方法有max, min, mean, max/min等.
比较有意思的是, 从实验结果来看, motion的作用远大于rgb的.
5 训练svm的action classifiers.
一般来说, 视频的feature descriptors往往是高维的, 如P-CNN的160k-d.
所以在训练svm时, 需要对特征进行降维操作, 可以用PCA等这些方法.
整体来说, 论文的做法非常pineline,
每个步骤都是用一些state-of-art的模型来提取pose, 特征什么的.
所以个人觉得没有什么创新点.