《ReDeBug: Finding Unpatched Code Clones in Entire OS Distributions》精读
Abstract摘要
程序员不应该为同一个漏洞打两次补丁,但是很不幸,这经常发生,因为在给漏洞打补丁的时候,却没有给其对应的克隆代码打补丁,没有打补丁的克隆代码意味着潜在的漏洞、安全风险,急需被很快探测到。
在本文中我们介绍了ReDeBug,这个工具可以在大规模场景下快速找到没打补丁的克隆代码。尽管在之前已经有一些相关工作,但是ReDeBug的特点在于使用了快速的、基于语法的方法来提高扩展性。与之前的方法相比,ReDeBug可能会找到更少的克隆代码,但是提高了速度、可扩展性,减少了误报率,以及与语言无关。
Introduction前言
打补丁时经常不会给克隆代码同样触发漏洞的地方带上补丁。比如下图是一个XML解析器在2009年8月打的关于边界校验的补丁
Abstract摘要
程序员不应该为同一个漏洞打两次补丁,但是很不幸,这经常发生,因为在给漏洞打补丁的时候,却没有给其对应的克隆代码打补丁,没有打补丁的克隆代码意味着潜在的漏洞、安全风险,急需被很快探测到。
在本文中我们介绍了ReDeBug,这个工具可以在大规模场景下快速找到没打补丁的克隆代码。尽管在之前已经有一些相关工作,但是ReDeBug的特点在于使用了快速的、基于语法的方法来提高扩展性。与之前的方法相比,ReDeBug可能会找到更少的克隆代码,但是提高了速度、可扩展性,减少了误报率,以及与语言无关。
Introduction前言
打补丁时经常不会给克隆代码同样触发漏洞的地方带上补丁。比如下图是一个XML解析器在2009年8月打的关于边界校验的补丁

这个漏洞被利用时会造成拒绝服务供给。然而这一处漏洞代码在其他位于Debian\Ubuntu\SourceForage package等攻击386处都有,但是它们都没有打上补丁,这都是潜在可以被攻击的地方。我们称这种bug为unpatched code clone。
现有研究的缺点包括:
scalabiilty缺乏可扩展性
Lack of support for many different languages不支持多种编程语言
High false detection rate高误报率
ReDeBug
A.The core system
1.ReDeBug会标准化每个文件,默认情况下会删除注释、非ascii字符、除了新行外的冗余的空格键,如果是C,C++,java,perl的话还会忽略花括号
2.被标准化的文件会基于新行和正则表达式子串is tokenized
3.在token stream上有一个长度为n的滑动窗口,每个n tokens都被作为进行比较的一个代码单元
4.考虑两个n-tokens的集合fa,fb,我们计算他们相同代码的数量。当找到没打补丁的克隆时,如果fa是原始有漏洞的代码段,那么我们计算
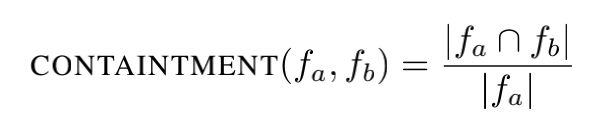
如果我们想要衡量文件间总的相似性,我们会计算相同token的百分比,比如使用Jaccard 系数
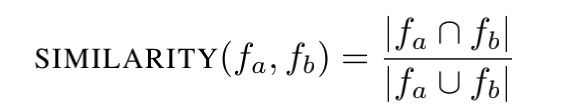
如果结果超过我们预先设定的阈值。如果fa属于fb,那么阈值为1,这样就没必要计算Containment的准确的比例
5.ReDeBug移除Bloom filter 错误后会对识别出的未打补丁的代码进行精确的匹配。ReDeBug也使用编译器来确定哪些代码可能是dead code
举例来说,假设有两个文件A=t1t2t3t4,B=t1t3t4t2,每个ti都是一个token,那么tokenization后就是A={t1,t2,t3,t4},B={t1,t2,t4,t2}。当n=2时,这里有三个2-token:fa={(t1,t2),(t2,t3),(t3,t4)},fb={(t1,t3)(t3,t4)(t4,t2)},则相似度为1/5
连续token的数量n,门限值cita,
本工作的设计和其他不同,其他工作也会规范表示代码,不过还会采取其他步骤,比如将代码转换为高级表示比如解析树parse tree和控制流图control flow graph,然后会应用高级的模糊匹配算法来找到我们可能会错过的代码克隆处。但是这会有很高的误报率,而且需要人工验证。并且实现一个好的解析器是非常困难的
B.Unpatched Code Clone Detection
ReDeBug寻找unix中以diff格式统一表示过的补丁对应的unpatched code clone。在流行的版本控制系统如Subversion中也有集成diff。
一个标准的diff补丁包含一系列不同的hunk。每个hunk都包含改变的名字,一系列的增删。增加的源码前面有+符号标记,删去的源码前面有-标记。行改变意味着删去原始行和增加改变的行
原始的原bug的代码包含所有被补丁删去的代码。然而,简单去查找被改变的行是远远不够的:我们必须考虑到补丁的上下文
如下所示

第一种补丁是用strncpy代替strcpy,我们可以找到代码中被删除的那一行,在其他地方看到时将其标记为漏洞代码。然而第二种补丁只是简单加了个校验。要想在对应的克隆代码处找到缺失的校验没有找一行缺失的代码直接。我们的方法是对改变的每一行找上下文token的拷贝,c,并报告克隆的上下文。
总体的步骤如下所示

预处理源码:
采用n-length的窗口得到n-tokens,并散列至Bloom flter
对每个以原始数据格式表示的源代码文件的Bloom filter将其保存下来
校对没打补丁的克隆代码
使用bitvector来加速pair-wise的比对
获得源码:对于Debian和Ubuntu来说,使用apt就可以了。对于SourceForge,我们爬取了所有的Subversion,CVS和Git目录
对于每个文件,都进行normalize和tokenize
对于每个n-token序列i,计算h(i)=d,然后设置对应文件的bitvector的第d个bit为m
计算每一对bitvector的相似度
Implementation & evaluation实现及评估
A.Implementation
ReDeBug由大约1000行c和250行python实现。归一化由python实现。
B.Unpatched code clone detection expeerimental setup
数据集

为了找到明显的bug,我们从debian,ubuntu security advisory(此处有相应的链接指向对应的package和patch/diff)收集了和安全相关的补丁。
D.Security-related bug
分三种情况进行讨论

E.The Identified Unpatched Code Clones

上图展示了我们多久找到克隆。。大多数patch有少于50个独立的未打补丁的克隆。
。。
主要是介绍一些关联性分析,
F.Code Clone Detection Errors
一种流行的指标是匹配过程的准确率,在ReDeBug中指的是布隆过滤器测试(Bloom filter test),它没有false negative,可能有false positive。
有时候匹配到的代码克隆漏洞会位于死代码(dead code,即无效代码)处,比如下图这个

这是位于libcompress-bzip2-perl,但是开发者说这是dead code,所以严格意义说不算漏洞。
在预处理阶段(pre-processing step),我们消除了在编译阶段不会被包含进去的dead code,
G.examples of security-realted bugs
我们向Debain安全团队报告了1532个克隆代码bug,目前收到了145个确认。接下来给出一些例子
QEMU是一款处理器模拟器。Cve-2008-0928可以使用攻击者拿到host机器上的root权限。
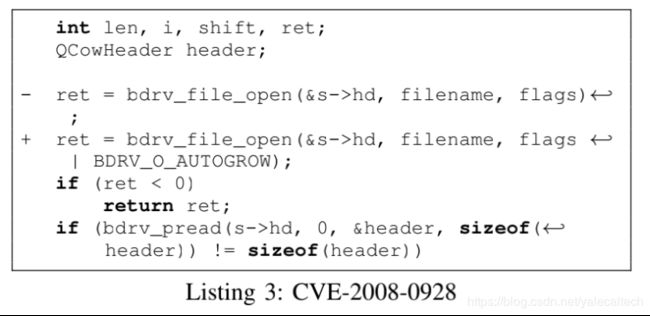
但是这个补丁没有被引用在派生出的packages,比如xen-qemu,这是Xen版本的qemu
下面这个是rsyslog的一个打了补丁的代码,利用这个漏洞攻击者可以伪造日志消息从而造成dos攻击

但是这个补丁没有被应用到Debian package rsyslogssapi,这是rsyslog带插件的版本,允许rsyslog写和接收GSSAPI加密的日志消息
下图是GIMP的Paint Shop Pro插件中的修补的一个缓冲区溢出漏洞

下图是php 5.3.6版本之前的整数溢出漏洞,会造成dos,可能还会造成信息泄露。但是这个补丁没有被应用在Debian php package中。

下图的补丁在ubuntu oneiric package实现了,但是没有应用在debian squeeze packge。这是修补了位于ecryptfsutils中的不正确的/etc/mtab所有权错误,可能会导致未挂载的任意位置(unmount arbitrary location,emmm不知道这是什么漏洞)

H.copied similarity metrics
主要就是通过实验发现代码克隆的现象非常普遍
DISCUSSION讨论
Related Work相关工作
MOSS是一款知名的使用n-tokens的相似度检测工具,MOSS基于叫做winnowing的算法,这是一种模糊hash技术,会选择n-tokens的子集来寻找相似的代码。ReDeBug与之区别在于ReDeBug使用特征hash来编码n-token为bitvector,从而使得ReDeBug可以以缓存有效的方法(cache-efficient)来执行相似性比较。我们使用特征hash来替换winnowing以提升速度。进一步地,为了发现未打补丁的代码克隆,我们只针对打了补丁的bug处开展我们的工作
近期学术界的大多数工作都是关注检测所有的代码克隆(比如减少缺失的代码克隆数量,但是会得到更高的误报率)。相关的例子有Deckard,CCFinder,CP-Miner和Deja Vu.探测到所有的代码。这种类型的研究会用到各种启发式的匹配算法,都需要基于高层次的代码抽象,比如CFG,解析树(parse tree),这些都要求实现鲁棒性强的解析器,这是非常困难的。
前面提到的这些技术都代表了独特的思考点,ReDeBug相较于CP-Miner,Deja Vu有更低的误报率,并且有更好的扩展性。
与SYDIT相比,这个工具是程序转换工具,可以将程序转为抽象语法树,它侧重语义,而ReDeBug侧重语法。
Patch Miner与我们的工作比较像,但是与他们联系没有取得任何回应,所以无法比较。
Deja Vu Deckard,Deja Vu使用LSH(locality sensitive hashing)局部敏感hash配合Jaccard距离算法来加速Pairwise的比较。而我们使用的特征hash(feature hashing)。理论上而言,我们的方法性能更好。
Brumley认为一旦一个补丁是公开可获取的,攻击者可通过逆向工程写出漏洞利用工具,我们在以后的工作中会将这一点作为附加考虑的点来展开研究。
Conclusion结论:
本文设计了ReDeBug,旨在检测未打补丁的克隆代码,具有高度可扩展性,可以处理真实代码,并最小化误报率。通过分析一款商用桌面版系统的2.1百万行代码,ReDeBug发现了了15546个没打补丁的克隆代码,这些很有可能会引发漏洞。我们在最新版本的Debian Squeeze package中确认了145个实际的bug,证明了ReDeBug的实际效果。我们有理由相信,对于开发者而言,ReDeBug会成为解决他们编写的代码安全性的一种较为现实的方法。
这个漏洞被利用时会造成拒绝服务供给。然而这一处漏洞代码在其他位于Debian\Ubuntu\SourceForage package等攻击386处都有,但是它们都没有打上补丁,这都是潜在可以被攻击的地方。我们称这种bug为unpatched code clone。
现有研究的缺点包括:
scalabiilty缺乏可扩展性
Lack of support for many different languages不支持多种编程语言
High false detection rate高误报率
ReDeBug
A.The core system
1.ReDeBug会标准化每个文件,默认情况下会删除注释、非ascii字符、除了新行外的冗余的空格键,如果是C,C++,java,perl的话还会忽略花括号
2.被标准化的文件会基于新行和正则表达式子串is tokenized
3.在token stream上有一个长度为n的滑动窗口,每个n tokens都被作为进行比较的一个代码单元
4.考虑两个n-tokens的集合fa,fb,我们计算他们相同代码的数量。当找到没打补丁的克隆时,如果fa是原始有漏洞的代码段,那么我们计算
如果我们想要衡量文件间总的相似性,我们会计算相同token的百分比,比如使用Jaccard 系数
如果结果超过我们预先设定的阈值。如果fa属于fb,那么阈值为1,这样就没必要计算Containment的准确的比例
5.ReDeBug移除Bloom filter 错误后会对识别出的未打补丁的代码进行精确的匹配。ReDeBug也使用编译器来确定哪些代码可能是dead code
举例来说,假设有两个文件A=t1t2t3t4,B=t1t3t4t2,每个ti都是一个token,那么tokenization后就是A={t1,t2,t3,t4},B={t1,t2,t4,t2}。当n=2时,这里有三个2-token:fa={(t1,t2),(t2,t3),(t3,t4)},fb={(t1,t3)(t3,t4)(t4,t2)},则相似度为1/5
连续token的数量n,门限值cita,
本工作的设计和其他不同,其他工作也会规范表示代码,不过还会采取其他步骤,比如将代码转换为高级表示比如解析树parse tree和控制流图control flow graph,然后会应用高级的模糊匹配算法来找到我们可能会错过的代码克隆处。但是这会有很高的误报率,而且需要人工验证。并且实现一个好的解析器是非常困难的
B.Unpatched Code Clone Detection
ReDeBug寻找unix中以diff格式统一表示过的补丁对应的unpatched code clone。在流行的版本控制系统如Subversion中也有集成diff。
一个标准的diff补丁包含一系列不同的hunk。每个hunk都包含改变的名字,一系列的增删。增加的源码前面有+符号标记,删去的源码前面有-标记。行改变意味着删去原始行和增加改变的行
原始的原bug的代码包含所有被补丁删去的代码。然而,简单去查找被改变的行是远远不够的:我们必须考虑到补丁的上下文
如下所示
第一种补丁是用strncpy代替strcpy,我们可以找到代码中被删除的那一行,在其他地方看到时将其标记为漏洞代码。然而第二种补丁只是简单加了个校验。要想在对应的克隆代码处找到缺失的校验没有找一行缺失的代码直接。我们的方法是对改变的每一行找上下文token的拷贝,c,并报告克隆的上下文。
总体的步骤如下所示
预处理源码:
采用n-length的窗口得到n-tokens,并散列至Bloom flter
对每个以原始数据格式表示的源代码文件的Bloom filter将其保存下来
校对没打补丁的克隆代码
使用bitvector来加速pair-wise的比对
获得源码:对于Debian和Ubuntu来说,使用apt就可以了。对于SourceForge,我们爬取了所有的Subversion,CVS和Git目录
对于每个文件,都进行normalize和tokenize
对于每个n-token序列i,计算h(i)=d,然后设置对应文件的bitvector的第d个bit为m
计算每一对bitvector的相似度
Implementation & evaluation实现及评估
A.Implementation
ReDeBug由大约1000行c和250行python实现。归一化由python实现。
B.Unpatched code clone detection expeerimental setup
数据集
为了找到明显的bug,我们从debian,ubuntu security advisory(此处有相应的链接指向对应的package和patch/diff)收集了和安全相关的补丁。
D.Security-related bug
分三种情况进行讨论
E.The Identified Unpatched Code Clones
上图展示了我们多久找到克隆。。大多数patch有少于50个独立的未打补丁的克隆。
。。
主要是介绍一些关联性分析,
F.Code Clone Detection Errors
一种流行的指标是匹配过程的准确率,在ReDeBug中指的是布隆过滤器测试(Bloom filter test),它没有false negative,可能有false positive。
有时候匹配到的代码克隆漏洞会位于死代码(dead code,即无效代码)处,比如下图这个
这是位于libcompress-bzip2-perl,但是开发者说这是dead code,所以严格意义说不算漏洞。
在预处理阶段(pre-processing step),我们消除了在编译阶段不会被包含进去的dead code,
G.examples of security-realted bugs
我们向Debain安全团队报告了1532个克隆代码bug,目前收到了145个确认。接下来给出一些例子
QEMU是一款处理器模拟器。Cve-2008-0928可以使用攻击者拿到host机器上的root权限。
但是这个补丁没有被引用在派生出的packages,比如xen-qemu,这是Xen版本的qemu
下面这个是rsyslog的一个打了补丁的代码,利用这个漏洞攻击者可以伪造日志消息从而造成dos攻击
但是这个补丁没有被应用到Debian package rsyslogssapi,这是rsyslog带插件的版本,允许rsyslog写和接收GSSAPI加密的日志消息
下图是GIMP的Paint Shop Pro插件中的修补的一个缓冲区溢出漏洞
下图是php 5.3.6版本之前的整数溢出漏洞,会造成dos,可能还会造成信息泄露。但是这个补丁没有被应用在Debian php package中。
下图的补丁在ubuntu oneiric package实现了,但是没有应用在debian squeeze packge。这是修补了位于ecryptfsutils中的不正确的/etc/mtab所有权错误,可能会导致未挂载的任意位置(unmount arbitrary location,emmm不知道这是什么漏洞)
H.copied similarity metrics
主要就是通过实验发现代码克隆的现象非常普遍
DISCUSSION讨论
Related Work相关工作
MOSS是一款知名的使用n-tokens的相似度检测工具,MOSS基于叫做winnowing的算法,这是一种模糊hash技术,会选择n-tokens的子集来寻找相似的代码。ReDeBug与之区别在于ReDeBug使用特征hash来编码n-token为bitvector,从而使得ReDeBug可以以缓存有效的方法(cache-efficient)来执行相似性比较。我们使用特征hash来替换winnowing以提升速度。进一步地,为了发现未打补丁的代码克隆,我们只针对打了补丁的bug处开展我们的工作
近期学术界的大多数工作都是关注检测所有的代码克隆(比如减少缺失的代码克隆数量,但是会得到更高的误报率)。相关的例子有Deckard,CCFinder,CP-Miner和Deja Vu.探测到所有的代码。这种类型的研究会用到各种启发式的匹配算法,都需要基于高层次的代码抽象,比如CFG,解析树(parse tree),这些都要求实现鲁棒性强的解析器,这是非常困难的。
前面提到的这些技术都代表了独特的思考点,ReDeBug相较于CP-Miner,Deja Vu有更低的误报率,并且有更好的扩展性。
与SYDIT相比,这个工具是程序转换工具,可以将程序转为抽象语法树,它侧重语义,而ReDeBug侧重语法。
Patch Miner与我们的工作比较像,但是与他们联系没有取得任何回应,所以无法比较。
Deja Vu Deckard,Deja Vu使用LSH(locality sensitive hashing)局部敏感hash配合Jaccard距离算法来加速Pairwise的比较。而我们使用的特征hash(feature hashing)。理论上而言,我们的方法性能更好。
Brumley认为一旦一个补丁是公开可获取的,攻击者可通过逆向工程写出漏洞利用工具,我们在以后的工作中会将这一点作为附加考虑的点来展开研究。
Conclusion结论:
本文设计了ReDeBug,旨在检测未打补丁的克隆代码,具有高度可扩展性,可以处理真实代码,并最小化误报率。通过分析一款商用桌面版系统的2.1百万行代码,ReDeBug发现了了15546个没打补丁的克隆代码,这些很有可能会引发漏洞。我们在最新版本的Debian Squeeze package中确认了145个实际的bug,证明了ReDeBug的实际效果。我们有理由相信,对于开发者而言,ReDeBug会成为解决他们编写的代码安全性的一种较为现实的方法。