python字符串内建函数详解
概述
字符串方法是从python1.6到2.0慢慢加进来的——它们也被加到了Jython中。
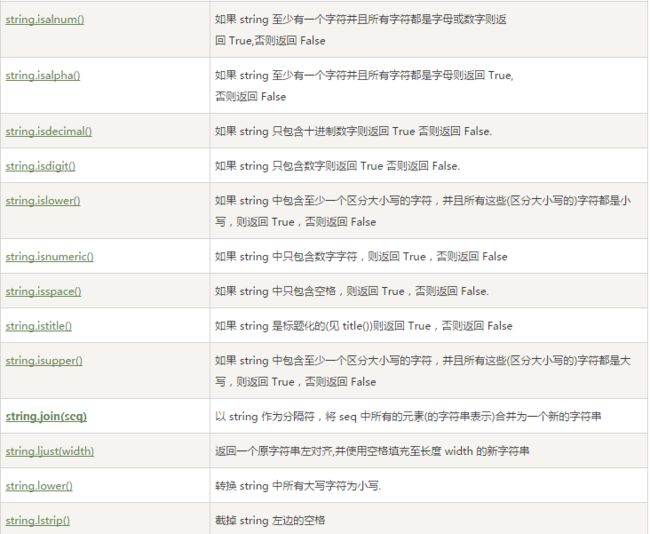
这些方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的。
Python capitalize()方法
描述
Python capitalize()将字符串的第一个字母变成大写,其他字母变小写。对于 8 位字节编码需要根据本地环境。
语法
capitalize()方法语法: str.capitalize()
参数
无。
返回值
该方法返回一个首字母大写的字符串。
实例
以下实例展示了capitalize()方法的实例:
#!/usr/bin/python
str = "this is string example....wow!!!";
print "str.capitalize() : ", str.capitalize()以上实例输出结果如下:
str.capitalize() : This is string example....wow!!!Python center()方法
描述
Python center() 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串。默认填充字符为空格。
语法
center()方法语法: str.center(width[, fillchar])
参数
width – 字符串的总宽度。 fillchar – 填充字符。
返回值
该方法返回一个原字符串居中,并使用空格填充至长度 width 的新字符串。
实例
以下实例展示了center()方法的实例:
#!/usr/bin/python
str = "this is string example....wow!!!";
print "str.center(40, 'a') : ", str.center(40, 'a')以上实例输出结果如下:
str.center(40, 'a') : aaaathis is string example....wow!!!aaaaPython count()方法
描述
Python count() 方法用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
语法
count()方法语法: str.count(sub, start= 0,end=len(string))
参数
sub – 搜索的子字符串
start – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
end –字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
返回值
该方法返回子字符串在字符串中出现的次数。
实例
以下实例展示了count()方法的实例:
#!/usr/bin/python
str = "this is string example....wow!!!";
sub = "i";
print "str.count(sub, 4, 40) : ", str.count(sub, 4, 40)
sub = "wow";
print "str.count(sub) : ", str.count(sub)以上实例输出结果如下:
str.count(sub, 4, 40) : 2
str.count(sub, 4, 40) : 1Python decode()方法
描述
Python decode() 方法以 encoding 指定的编码格式解码字符串。默认编码为字符串编码。
语法
decode()方法语法:
str.decode(encoding=’UTF-8’,errors=’strict’)
参数
encoding – 要使用的编码,如”UTF-8”。
errors – 设置不同错误的处理方案。默认为
‘strict’,意为编码错误引起一个UnicodeError。 其他可能得值有 ‘ignore’, ‘replace’,’xmlcharrefreplace’, ‘backslashreplace’ 以及通过 codecs.register_error() 注册的任何值。
返回值
该方法返回解码后的字符串。
实例
以下实例展示了decode()方法的实例:
#!/usr/bin/python
str = "this is string example....wow!!!";
str = str.encode('base64','strict');
print "Encoded String: " + str;
print "Decoded String: " + str.decode('base64','strict')以上实例输出结果如下:
Encoded String: dGhpcyBpcyBzdHJpbmcgZXhhbXBsZS4uLi53b3chISE=
Decoded String: this is string example....wow!!!Python encode()方法
描述
Python encode() 方法以 encoding 指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案。
语法
str.encode(encoding=’UTF-8’,errors=’strict’)
参数
encoding – 要使用的编码,如”UTF-8”。
errors – 设置不同错误的处理方案。默认为 ‘strict’,意为编码错误引起一个UnicodeError。 其他可能得值有’ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ 以及通过 codecs.register_error() 注册的任何值。
返回值
该方法返回编码后的字符串。
实例
以下实例展示了encode()方法的实例:
#!/usr/bin/python
str = "this is string example....wow!!!";
print "Encoded String: " + str.encode('base64','strict')以上实例输出结果如下:
Encoded String: dGhpcyBpcyBzdHJpbmcgZXhhbXBsZS4uLi53b3chISE=Python endswith()方法
描述
Python endswith()方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。
可选参数”start”与”end”为检索字符串的开始与结束位置。
语法
endswith()方法语法: str.endswith(suffix[, start[, end]])
参数
suffix – 该参数可以是一个字符串或者是一个元素。
start – 字符串中的开始位置。
end – 字符中结束位置。
返回值
如果字符串含有指定的后缀返回True,否则返回False。
实例
以下实例展示了endswith()方法的实例:
#!/usr/bin/python
str = "this is string example....wow!!!";
suffix = "wow!!!";
print str.endswith(suffix);
print str.endswith(suffix,20);
suffix = "is";
print str.endswith(suffix, 2, 4);
print str.endswith(suffix, 2, 6);以上实例输出结果如下:
True
True
True
FalsePython expandtabs()方法
描述
Python expandtabs() 方法把字符串中的 tab 符号(‘\t’)转为空格,tab 符号(‘\t’)默认的空格数是 8。
语法
expandtabs()方法语法: str.expandtabs(tabsize=8)
参数
tabsize – 指定转换字符串中的 tab 符号(‘\t’)转为空格的字符数
返回值
该方法返回字符串中的 tab 符号(‘\t’)转为空格后生成的新字符串。
实例
以下实例展示了expandtabs()方法的实例:
#!/usr/bin/python
str = "this is\tstring example....wow!!!";
print "Original string: " + str;
print "Defualt exapanded tab: " + str.expandtabs();
print "Double exapanded tab: " + str.expandtabs(16);以上实例输出结果如下:
Original string: this is string example....wow!!!
Defualt exapanded tab: this is string example....wow!!!
Double exapanded tab: this is string example....wow!!!Python find()方法
描述
Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
语法
find()方法语法: str.find(str, beg=0, end=len(string))
参数
str – 指定检索的字符串
beg – 开始索引,默认为0。
end – 结束索引,默认为字符串的长度。
返回值
如果包含子字符串返回开始的索引值,否则返回-1。
实例
以下实例展示了find()方法的实例:
#!/usr/bin/python
str1 = "this is string example....wow!!!";
str2 = "exam";
print str1.find(str2);
print str1.find(str2, 10);
print str1.find(str2, 40);以上实例输出结果如下:
15
15
-1Python index()方法
描述
Python index() 方法检测字符串中是否包含子字符串 str ,
如果指定 beg(开始) 和 end(结束)范围,则检查是否包含在指定范围内
该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。
语法
index()方法语法: str.index(str, beg=0, end=len(string))
参数
str – 指定检索的字符串
beg – 开始索引,默认为0。
end – 结束索引,默认为字符串的长度。
返回值
如果包含子字符串返回开始的索引值,否则抛出异常。
实例
以下实例展示了index()方法的实例:
#!/usr/bin/python
str1 = "this is string example....wow!!!";
str2 = "exam";
print str1.index(str2);
print str1.index(str2, 10);
print str1.index(str2, 40);以上实例输出结果如下:
15
15
Traceback (most recent call last):
File "test.py", line 8, in
print str1.index(str2, 40);
ValueError: substring not found
shell returned 1异常处理的部分后续再说~
其他