io_submit,io_getevents被阻塞原因分析
libaio虽然是异步direct-io,但某些情况下仍然会被阻塞。
测试环境,
硬盘信息:ATA HGST硬盘,6.0 Gbps SATA HDD,容量5.46TiB(6.00TB);
逻辑盘信息:RAID0,容量5.457TiB,条带大小256KB,读策略Read ahead,写策略Write back;
[root@localhost ~]# lsscsi
[0:2:0:0] disk AVAGO MR9361-8i 4.68 /dev/sda
fio测试命令:
./fio -ioengine=libaio -bs=8k -direct=1 -numjobs 16 -rw=read -size=10G -filename=/dev/sda2 -name="Max throughput" -iodepth=128 -runtime=60
查看系统调用耗时(如果被阻塞,libaio系统调用耗时会比较大,'--duration 1'表示如果系统调用耗时大于1ms则输出):
perf trace -p `pidof -s fio` --duration 1
查看fio线程被调度出去的原因(即因libaio系统调用被阻塞而被调度出去,该命令打印出调度出去的调用栈):
offcputime -K -p `pgrep -nx fio`
使用ebpf的bcc工具biolatency来查看后端设备在不同的nr_requests下的压力(即IO在D2C阶段的耗时,其反映了后端设备的性能,本测试中D2C反应的'raid卡+hdd'的性能):
biolatency -D
sda请求队列长度128(默认):
cat /sys/block/sda/queue/nr_requests
由于块设备层的request资源有限(默认128,request的申请与拥塞控制原理见之前的博文"Linux IO并发拥塞控制机制分析-1/2/3"),在fio多任务测试下,由于request资源不够用,导致io_submit系统调用被阻塞在request资源上。
在nr_requests调整为256后,系统调用io_submit几乎不阻塞,在修改为512后,完全不阻塞;
但随着nr_requests加大,io_getevents会越来越阻塞,与io_submit的阻塞情况完全相反,详细测试结果见下面的贴图。
nr_requests = 128时的测试日志:




nr_requests = 256时的测试日志:




关于nr_requests加大,io_getevents会变得阻塞,先看下io_getevents的主要逻辑,io_getevents会调到read_events函数来读取aio的完成events:
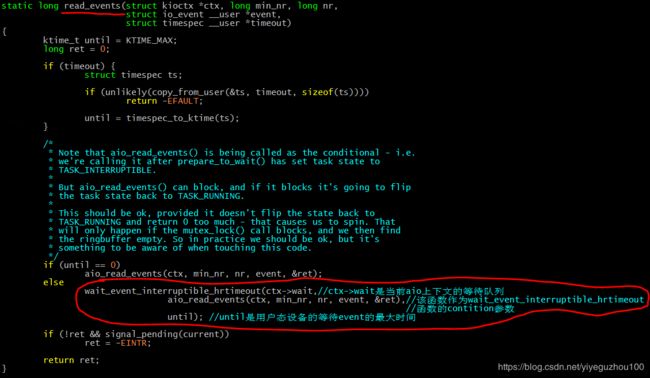



aio完成后,注册的aio回调函数aio_complete(在bio的回调中被调用)被调用,在该函数中会判断当前aio上下文的等待队列(ctx->wait)是否为空,若不空,就唤醒等待队列中的线程,因为aio_complete被调用时就表示已经有aio完成了,所以当前aio上下文的ring buffer必然不空,所以可以唤醒等待该event的线程:
aio_complete函数的最后部分:

所以本测试中,当nr_requests加大,io_getevents会变得阻塞,是因为IO提交流程中request资源充足,io_submit的IO提交流程没有阻塞,造成提交给后端设备的io会很多(通过上述iostat可知sda的请求队列长度随着nr_requests的加大而增大),后端设备处理IO的压力变大(通过上述biolatency -D命令可知D2C耗时随着nr_requests加大而增大),IO完成速率变慢,所以io_getevents需要更多的时间睡眠等待aio完成event。
但总的来说随着nr_requests增大,带宽、iops都变大,性能更好,
128:
read : io=623432KB, bw=10387KB/s, iops=1298, runt= 60020msec
256:
read : io=1009.5MB, bw=17206KB/s, iops=2150, runt= 60075msec
512:
read : io=1024.0MB, bw=19077KB/s, iops=2384, runt= 54966msec