【Python】批量创建线程
在《【Python】线程的创建、执行、互斥、同步、销毁》(点击打开链接)中介绍了Python中线程的使用,但是里面线程的创建,使用了很原始的方式,一行代码创建一条。其实,Python里是可以批量创建线程的。利用Python批量创建线程可以将之前的程序优化,具体请看如下的代码:
# -*-coding:utf-8-*-
import threading;
mutex_lock = threading.RLock(); # 互斥锁的声明
ticket = 100000; # 总票数
# 用于统计各个线程的得票数
ticket_stastics=[];
class myThread(threading.Thread): # 线程处理函数
def __init__(self, name):
threading.Thread.__init__(self); # 线程类必须的初始化
self.thread_name = name; # 将传递过来的name构造到类中的name
def run(self):
# 声明在类中使用全局变量
global mutex_lock;
global ticket;
while 1:
mutex_lock.acquire(); # 临界区开始,互斥的开始
# 仅能有一个线程↓↓↓↓↓↓↓↓↓↓↓↓
if ticket > 0:
ticket -= 1;
# 统计哪到线程拿到票
print "线程%s抢到了票!票还剩余:%d。" % (self.thread_name, ticket);
ticket_stastics[self.thread_name]+=1;
else:
break;
# 仅能有一个线程↑↑↑↑↑↑↑↑↑↑↑↑
mutex_lock.release(); # 临界区结束,互斥的结束
mutex_lock.release(); # python在线程死亡的时候,不会清理已存在在线程函数的互斥锁,必须程序猿自己主动清理
print "%s被销毁了!" % (self.thread_name);
# 初始化线程
threads = [];#存放线程的数组,相当于线程池
for i in range(0,5):
thread = myThread(i);#指定线程i的执行函数为myThread
threads.append(thread);#先讲这个线程放到线程threads
ticket_stastics.append(0);# 初始化线程的得票数统计数组
for t in threads:#让线程池中的所有数组开始
t.start();
for t in threads:
t.join();#等待所有线程运行完毕才执行一下的代码
print "票都抢光了,大家都散了吧!";
print "=========得票统计=========";
for i in range(0,len(ticket_stastics)):
print "线程%d:%d张" % (i,ticket_stastics[i]);
运行结果还是原来的功能:
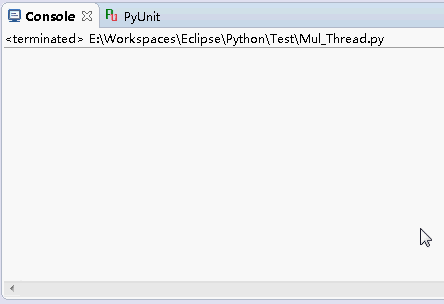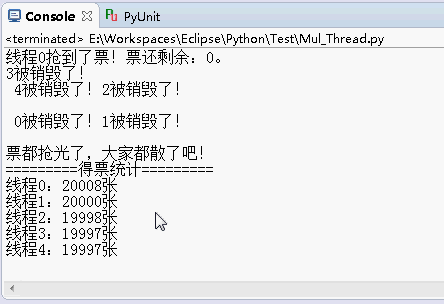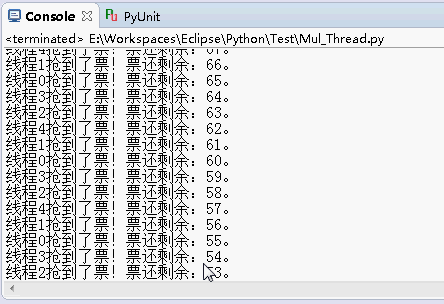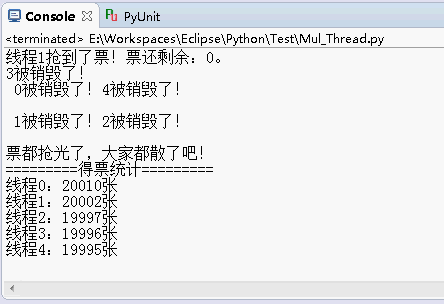
但是,这里利用了一个数组和for循环创建线程,先遍历创建一堆线程放到线程池threads里面,实质上所谓的“线程池”也就是存放线程的数组,再用一个for循环,让这个线程池threads里面的线程全部开始。
# 初始化线程
threads = [];#存放线程的数组,相当于线程池
for i in range(0,5):
thread = myThread(i);#指定线程i的执行函数为myThread
threads.append(thread);#先讲这个线程放到线程threads
for t in threads:#让线程池中的所有数组开始
t.start();
for t in threads:
t.join();#等待所有线程运行完毕才执行一下的代码这里不能写成如下的代码段:
for t in threads:#让线程池中的所有数组开始
t.start();
t.join();#等待所有线程运行完毕才执行一下的代码