数据库高可用HA实现
1.什么是数据库高可用
1.1什么是高可用集群
N+1原则:N就是集群,1就是高可用,高可用的核心就是冗余;集群式保证服务最低使用标准的
1.2高可用集群的衡量标准
一般是通过系统的可靠性和可维护性来衡量的
MTTF:平均无故障时间,这是衡量可靠性的
MTTR:衡量系统的可维护性能
HA=MTTF/(MTTF+MTTR)*100%
SLA: 99.999%-表示一年故障时间不超过6分钟 ;普通系统999到9999之间
1.3实现高可用的三种方式
-
主从方式(非对称)
这种方式的组织形式通常都是通过两个节和一个或多个服务器,其中一台作为主节点(active),
另外一台作为备份节点(standy),备份节点应该随时都在检测主节点的健康状况,当主节点发生故障,服务会自动切换到备份
节点保障服务正常运行
主从对外方式
-
对称方式
两个节点,都运行着不同的服务,且相互备份,相互检测对方的健康,当任意一个节点发送故障,这个节点上的服务就会
自动切换到另一个节点。
-
多机方式
包含多个节点多个服务,每个节点都要备份运行不同的服务,出现问题自动迁移
思考:公司的数据库服务主从是否自动切换?
1.4 mysql数据的高可用实现
1.4.1 主从方式(非对称)
-
资源:两条同版本的mysql数据库
-
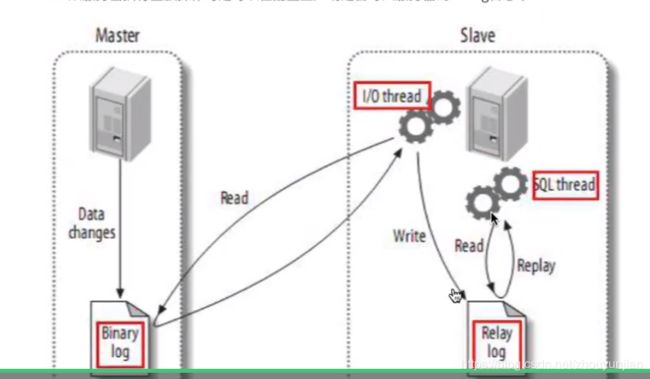
主从实现的内部运行原理和机制
1.主数据库服务会把数据的修改记录记录进binlog日志,binlog一定要打开
2.从库的i/o进行读取主库的binlog内容后存入自己的relay log(中继日志)中,这个i/o线程会和
主库建立一个普通的客户端连接,然后主库启动一个二进制转储线程 ,i/o线程通过转储线程读取
binlog更新事件,同步完毕后i/o进行sleep,有新的更新会唤醒。(不大清楚)
1.relay log和binlog的格式是一样的,可以用mysqlbinlog读取,也可show
2.show relaylog events in 'relay-log.00001';
目前数据库有两种复制方式
1.binlog日志点positon
2.GTID方式:全局事务id,也要依赖binlog
3.从服务器的sql进程会从relaylog中读取事件并在从库中重放
从服务器执行重放操作时可以在配置里声明是否写入服务器的binlog日志中
1.4.2 配置主从服务步骤
1.4.2.1 binlog日志点方式配置主从同步
-
配置主从服务器参数
-
在master服务器上创建用于复制并授权的数据库账号
-
备份master数据库并初始化slave服务器数据
-
启动复制链路
master服务配置
chown -R mysql:mysql /usr/local/binlog/ #授权
数据库配置文件(主库):
server_id=153 #主库ip
log_bin=/usr/local/binlog/mysql-bin
slave服务配置
chown -R mysql:mysql /usr/local/binlog/ #授权
数据库配置文件(从库):
server_id=152 #从库ip
log_bin=/usr/local/binlog/mysql-bin
relay_log=/usr/local/relaylog/relay-bin
relay_log_recovery=1 #当slave宕机后,如果relay log损坏了,导致一部分中继日志没有处理,则放弃所有未完成的,重新获取执行,保证完整性
read_only=on #让从库数据只读,super用户和root用户可写入(super_read_only=on #super不可写入设置,不建议)
skip_slave_start=on #从库的复制链路服务不会随数据库重启而重启,需要手动启动
#确保数据一致性,通过innoDb的崩溃恢复机制来保护
master_info_repository=TABLE
relay_log_info_repository=TABLE
#select * from mysql.slave_master_info;
#select * from mysql.slave_relay_log_info;
疑问:mysql、information_schema是干么用的(思考题)
主库授权
use mysql;
grant replication slave on *.* to 'root'@'118.190.173.250' identified by '123456';; #syncuser用户允许192.168.0.103访问
#密码等级改低,长度改6位 set global validate_password_policy=LOW; set global validate_password_length=6;
flush privileges; #刷新权限
初始化数据
create database mydbTest1; #建数据库
use mydbTest1; #使用数据库
create table test1(name varchar(10),age int,dateTime dateTime); #建表
insert into test1 values('zhou',10,'2019-12-19 00:00:00');#初始化数据
insert into test1 values('zhou',10,'2019-12-19 00:00:00');#初始化数据
##dump查看数据 mysqldump -uroot-p123456--master-data=2--single-transaction--routines-
-triggers--events--databases mydb > mydb.sql
创建复制链路(从库)
CHANGE MASTER TO
MASTER_HOST='115.29.66.116',
MASTER_PORT=3306,
MASTER_USER='root',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000007',
master_LOG_POS=2648;
start slave;
show slave status;
查看从库更新结果: 实时更新完成

从库的binlog是否写入
-
默认情况下是不写入的:因为写入binlog会消耗I/O,所以性能会下降,如果需要在从库上恢复数据就到relaylog
里进行导出处理
-
直接在从库上操作更新语句则会写入binlog
-
如果就是需要写入?在从库的my.cnf: log_slave_update=on #开启同步并写入binlog
-
开启同步并写入binlog应用于从到从的情况
#不同步哪些数据库
#master配置文件
binlog-ignore-db=mysql
binlog-ignore-db=mydbTest1
binlog-ignore-db=information_schema
#同步哪些库
binlog-do-db=game
binlog-do-db=mydb
#slave配置文件
#复制哪些数据库
replicate-do-db=mydb
#不复制哪些数据库
replicate-ignore-db=mysql
#指定表复制:忽略不不同的表
replicate-ignore-table=mydbTest1.test4
1.4.2.2 GTID的方式进行主从复制
跟position不同点
-
主从服务器的参数有不同的地方
#在上面的基础上,需要给主从服务器都加上
gtid_mod=on
enforce_gtid_consistency=on #开启强制gtid的一致性确保事务
-
gtid下复制链路的启动
change MASTER TO
MASTER_HOST='192.168.0.102',
MASTER_PORT=3306,
MASTER_USER='syncuser',
MASTER_PASSWORD='123456',
MASTER_AUTO_POSITION=1;
-
启动gtid后以下数据库操作不可用
1.create table table name ....select
2.在一个事务中创建临时表
3.在一个transaction中更新innoDb表和myisam表
2.数据库主从复制方式的容灾处理
2.1mysql支持的复制格式
2.1.1 基于语句的复制(statement)
-
优点:记录少、只记录执行语句,易懂,占用网络空间少
-
缺点:insert into table(create_time) values(now()),这个now就不是当时的时间了
2.1.2 基于行复制(row)
-
优点:几乎没有基于行复制无法处理的场景
-
缺点:数据量太大了
2.1.3混合类型的复制(MIXED)
mixed格式默认采用statement,出现statement无法精确复制时,用row; 比如用到UUID(),ROW_COUNT()
2.2主从切换
练习:自己把主从数据库更换
-
从库的binlog目前是没有写入的
-
需要给old主库授权new主库的权限
-
并且在old主库上创建复制链路
-
从库还需要把read_only关闭
2.3mysql主从复制模式
-
异步复制:mysql默认就是异步复制,性能最好,但主从复制数据不一致性概率最大
-
同步复制:当客户端发过来一个请求后,只有当所有的从库都写入到relay log中才回复给前端
该事务完成,性能最差,但一致性很强
-
半同步复制:至少一个从库完成relay log写入后就返回事务完成给前端
#主从上都要安装
install plugin rpl_semi_sync_master soname='semisync_master.so'
rpl_semi_sync_master_enabled
rpl_semi_sync_master_timeout #单位毫秒,如果主库等待从库回复超过这个时间就自动切换为异步
问题:做过主从复制,主从一般都是实时的同步的,如果出现数据库误操作,导致一大片数据错误如何解决?
-
update tableName set score=99;
-
从库是不是也会被直接更新掉?
-
一般情况下,从库对数据的实时性要求都不是非常高
-
如果我们有一个从库更新可以延时10分钟
-
如果运气好,在你拿到10分钟前的数据和你更新之间这个表没有操作,是不是完美解决?
-
设置一个从库,将延迟时间设置成能够处理和反映的周期长度即可
stop slave;
change master to master_delay=600 #设置延时600s sql_delay:600
start slave;