2020年Elasticsearch面试题详解(上)
1、elasticsearch 了解多少,说说你们公司 es 的集群架构,索引数据大小,分片有多少,以及一些调优手段 。
面试官:想了解应聘者之前公司接触的 ES 使用场景、规模,有没有做过比较大规模的索引设计、规划、调优。
解答:如实结合自己的实践场景回答即可。
比如:ES 集群架构 13 个节点,索引根据通道不同共 20+索引,根据日期,每日递增 20+,索引:10 分片,每日递增 1 亿+数据,每个通道每天索引大小控制:150GB 之内。
仅索引层面调优手段:
1.1、设计阶段调优
(1)根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索引;
(2)使用别名进行索引管理;
(3)每天凌晨定时对索引做 force_merge 操作,以释放空间;
(4)采取冷热分离机制,热数据存储到 SSD,提高检索效率;冷数据定期进行 shrink操作,以缩减存储;
(5)采取 curator 进行索引的生命周期管理;
(6)仅针对需要分词的字段,合理的设置分词器;
(7)Mapping 阶段充分结合各个字段的属性,是否需要检索、是否需要存储等。……..
1.2、写入调优
(1)写入前副本数设置为 0;
(2)写入前关闭 refresh_interval 设置为-1,禁用刷新机制;
(3)写入过程中:采取 bulk 批量写入;
(4)写入后恢复副本数和刷新间隔;
(5)尽量使用自动生成的 id。
1.3、查询调优
(1)禁用 wildcard;
(2)禁用批量 terms(成百上千的场景);
(3)充分利用倒排索引机制,能 keyword 类型尽量 keyword;
(4)数据量大时候,可以先基于时间敲定索引再检索;
(5)设置合理的路由机制。
1.4、其他调优
部署调优,业务调优等。
上面的提及一部分,面试者就基本对你之前的实践或者运维经验有所评估了。
2、elasticsearch 的倒排索引是什么
面试官:想了解你对基础概念的认知。
解答:通俗解释一下就可以。
传统的我们的检索是通过文章,逐个遍历找到对应关键词的位置。
而倒排索引,是通过分词策略,形成了词和文章的映射关系表,这种词典+映射表即为倒排索引。有了倒排索引,就能实现 o(1)时间复杂度的效率检索文章了,极大的提高了检索效率。
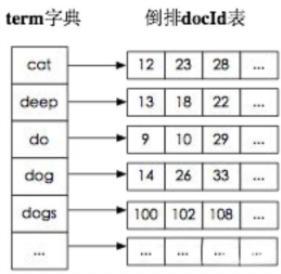
学术的解答方式:
倒排索引,相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成——词典和倒排表。
加分项:倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。
lucene 从 4+版本后开始大量使用的数据结构是 FST。FST 有两个优点:
(1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
(2)查询速度快。O(len(str))的查询时间复杂度。
3、elasticsearch 索引数据多了怎么办,如何调优,部署
面试官:想了解大数据量的运维能力。
解答:索引数据的规划,应在前期做好规划,正所谓“设计先行,编码在后”,这样才能有效的避免突如其来的数据激增导致集群处理能力不足引发的线上客户检索或者其他业务受到影响。
如何调优,正如问题 1 所说,这里细化一下:
3.1 动态索引层面
基于模板+时间+rollover api 滚动创建索引,举例:设计阶段定义:blog 索引的模板格式为:blog_index_时间戳的形式,每天递增数据。这样做的好处:不至于数据量激增导致单个索引数据量非常大,接近于上线 2 的32 次幂-1,索引存储达到了 TB+甚至更大。
一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
3.2 存储层面
冷热数据分离存储,热数据(比如最近 3 天或者一周的数据),其余为冷数据。
对于冷数据不会再写入新数据,可以考虑定期 force_merge 加 shrink 压缩操作,节省存储空间和检索效率。
3.3 部署层面
一旦之前没有规划,这里就属于应急策略。
结合 ES 自身的支持动态扩展的特点,动态新增机器的方式可以缓解集群压力,注意:如果之前主节点等规划合理,不需要重启集群也能完成动态新增的。
4、elasticsearch 是如何实现 master 选举的
面试官:想了解 ES 集群的底层原理,不再只关注业务层面了。
解答:
前置前提:
(1)只有候选主节点(master:true)的节点才能成为主节点。
(2)最小主节点数(min_master_nodes)的目的是防止脑裂。
核对了一下代码,核心入口为 findMaster,选择主节点成功返回对应 Master,否则返回 null。选举流程大致描述如下:
第一步:确认候选主节点数达标,elasticsearch.yml 设置的值
discovery.zen.minimum_master_nodes;
第二步:比较:先判定是否具备 master 资格,具备候选主节点资格的优先返回;
若两节点都为候选主节点,则 id 小的值会主节点。注意这里的 id 为 string 类型。
题外话:获取节点 id 的方法。
1GET /_cat/nodes?v&h=ip,port,heapPercent,heapMax,id,name
2ip port heapPercent heapMax id name5、详细描述一下 Elasticsearch 索引文档的过程
面试官:想了解 ES 的底层原理,不再只关注业务层面了。
解答:
这里的索引文档应该理解为文档写入 ES,创建索引的过程。
文档写入包含:单文档写入和批量 bulk 写入,这里只解释一下:单文档写入流程。
记住官方文档中的这个图。
第一步:客户写集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演路由节点的角色。)
第二步:节点 1 接受到请求后,使用文档_id 来确定文档属于分片 0。请求会被转到另外的节点,假定节点 3。因此分片 0 的主分片分配到节点 3 上。
第三步:节点 3 在主分片上执行写操作,如果成功,则将请求并行转发到节点 1和节点 2 的副本分片上,等待结果返回。所有的副本分片都报告成功,节点 3 将向协调节点(节点 1)报告成功,节点 1 向请求客户端报告写入成功。
如果面试官再问:第二步中的文档获取分片的过程?
回答:借助路由算法获取,路由算法就是根据路由和文档 id 计算目标的分片 id 的过程。
1shard = hash(_routing) % (num_of_primary_shards)
6、详细描述一下 Elasticsearch 搜索的过程?
面试官:想了解 ES 搜索的底层原理,不再只关注业务层面了。
解答:
搜索拆解为“query then fetch” 两个阶段。
query 阶段的目的:定位到位置,但不取。
步骤拆解如下:
(1)假设一个索引数据有 5 主+1 副本 共 10 分片,一次请求会命中(主或者副本分片中)的一个。
(2)每个分片在本地进行查询,结果返回到本地有序的优先队列中。
(3)第 2)步骤的结果发送到协调节点,协调节点产生一个全局的排序列表。
fetch 阶段的目的:取数据。
路由节点获取所有文档,返回给客户端。

7、Elasticsearch 在部署时,对 Linux 的设置有哪些优化方法
面试官:想了解对 ES 集群的运维能力。
解答:
(1)关闭缓存 swap;
(2)堆内存设置为:Min(节点内存/2, 32GB);
(3)设置最大文件句柄数;
(4)线程池+队列大小根据业务需要做调整;
(5)磁盘存储 raid 方式——存储有条件使用 RAID10,增加单节点性能以及避免单节点存储故障。
8、lucence 内部结构是什么?
面试官:想了解你的知识面的广度和深度。
解答:
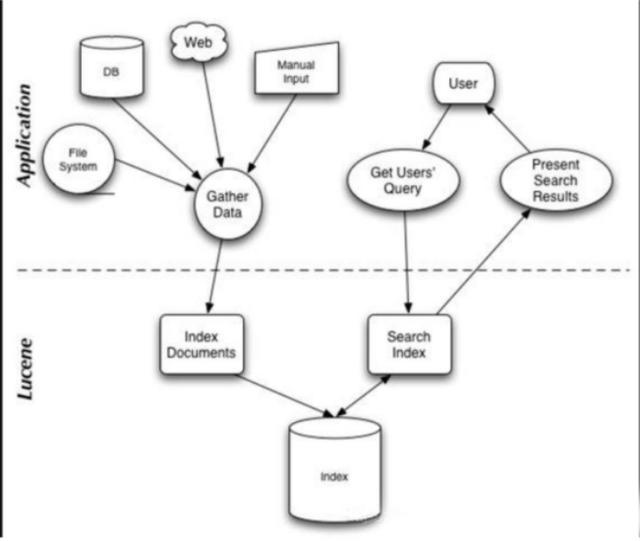
Lucene 是有索引和搜索的两个过程,包含索引创建,索引,搜索三个要点。可以基于这个脉络展开一些。
9、Elasticsearch 是如何实现 Master 选举的?
(1)Elasticsearch 的选主是 ZenDiscovery 模块负责的,主要包含 Ping(节点之间通过这个 RPC 来发现彼此)和 Unicast(单播模块包含一个主机列表以控制哪些节点需要 ping 通)这两部分;
(2)对所有可以成为 master 的节点(node.master: true)根据 nodeId 字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第 0 位)节点,暂且认为它是 master 节点。
(3)如果对某个节点的投票数达到一定的值(可以成为 master 节点数 n/2+1)并且该节点自己也选举自己,那这个节点就是 master。否则重新选举一直到满足上述条件。
(4)补充:master 节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data 节点可以关闭 http 功能*。
10、Elasticsearch 中的节点(比如共 20 个),其中的 10 个
选了一个 master,另外 10 个选了另一个 master,怎么办?
(1)当集群 master 候选数量不小于 3 个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
(3)当候选数量为两个时,只能修改为唯一的一个 master 候选,其他作为 data节点,避免脑裂问题。
11、客户端在和集群连接时,如何选择特定的节点执行请求的?
TransportClient 利用 transport 模块远程连接一个 elasticsearch 集群。它并不加入到集群中,只是简单的获得一个或者多个初始化的 transport 地址,并以 轮询 的方式与这些地址进行通信。
12、详细描述一下 Elasticsearch 索引文档的过程。
协调节点默认使用文档 ID 参与计算(也支持通过 routing),以便为路由提供合适的分片。
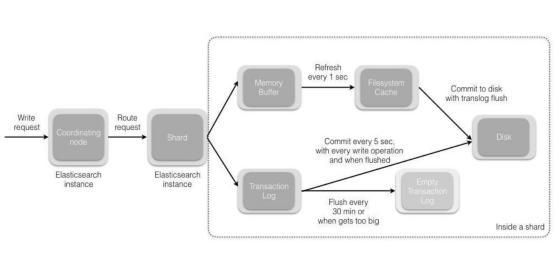
shard = hash(document_id) % (num_of_primary_shards)(1)当分片所在的节点接收到来自协调节点的请求后,会将请求写入到 MemoryBuffer,然后定时(默认是每隔 1 秒)写入到 Filesystem Cache,这个从 MomeryBuffer 到 Filesystem Cache 的过程就叫做 refresh;
(2)当然在某些情况下,存在 Momery Buffer 和 Filesystem Cache 的数据可能会丢失,ES 是通过 translog 的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到 translog 中 ,当 Filesystem cache 中的数据写入到磁盘中时,才会清除掉,这个过程叫做 flush;
(3)在 flush 过程中,内存中的缓冲将被清除,内容被写入一个新段,段的 fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的 translog 将被删除并开始一个新的 translog。
(4)flush 触发的时机是定时触发(默认 30 分钟)或者 translog 变得太大(默认为 512M)时;
补充:关于 Lucene 的 Segement:
(1)Lucene 索引是由多个段组成,段本身是一个功能齐全的倒排索引。
(2)段是不可变的,允许 Lucene 将新的文档增量地添加到索引中,而不用从头重建索引。
(3)对于每一个搜索请求而言,索引中的所有段都会被搜索,并且每个段会消耗CPU 的时钟周、文件句柄和内存。这意味着段的数量越多,搜索性能会越低。
(4)为了解决这个问题,Elasticsearch 会合并小段到一个较大的段,提交新的合并段到磁盘,并删除那些旧的小段。