python学习——day05
本文参与「少数派读书笔记征文活动」https://sspai.com/post/45653
今天安装wordcloud库的时候遇到报错:error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++ Build Tools”: http://landinghub.visualstudio.com/visual-cpp-build-tools (产生这个错误的主要原因是windows环境下没有默认安装c语言运行环境),根据提示我打开网址,发现这个网页已经不存在了;所以我在github上找到wordcloud下载解压,在解压路径下通过命令行 python setup.py install 安装,结果还是不行;所以最后还是在网上下载Microsoft Visual C++ 14.0安装了。(这个工具要占用4G的空间也是醉了,但是只安装VC++ 14.0的运行库也行不通,也只好如此了)
文件的使用
- 文件是存储在辅助存储器上的数据序列
- 文件展现形态:文本文件、二进制文件(本质上,所有文件都是二进制形式存储,所以都可以用二进制形式打开)
- 文本文件:由单一特定编码组成的文件,如UTF-8编码,由于存在编码,所以也被看成是存储着的长字符串(txt文件、.py文件等)
- 二进制文件:直接由比特0和1组成,没有统一字符串编码(png文件、.avi文件等)
文本形式打开bf=open("f.txt","rt")
二进制形式打开bf=open("f.txt","rb")
- 文件处理的步骤:打开-操作-关闭(文件的存储状态<->文件的占用状态)
打开模式(默认文本形式,只读模式)

f=open("f.txt","a+") #文本形式、追加写模式+读文件操作函数
1.读文件
a.read(size):读入全部内容,如果给出参数,读入前size长度
a.readline(size):读入当前指针指向的一行内容,如果给出参数,读入改行前size长度
a.readlines(hint):读入文件所有行,以每行为元素形成列表。如果给出参数,读入前hint行
2.写文件
a.write(s):向文件写入一个字符串或字节流
a.writelines(lines):向一个元素全为字符串的列表(元素全部拼接后)写入文件
a.seek(offset):改变当前文件操作指针(即文件写入后)的位置(offset=0:文件开头;offset=1:当前位置;offset=2:文件结尾)
3.关闭文件
a.close()
#TestFileRW
# fname=input("请输入要打开的文件名称:")
# fo=open("../data/"+fname,"r",encoding="utf-8")
#遍历全文本:方法一
# txt=fo.read() #一次读入,统一处理
# fo.close()
#遍历全文本:方法二
# txt=fo.read(2)
# while txt !="": #只要读入数据不为空,就一直读取
# txt=fo.read(2) #按数量读入,逐步处理
#逐行遍历文件:方法一
# for line in fo.readlines(): #readlines将文件每行作为一个元素组合为一个列表。故可迭代
# print(line)
#逐行遍历文件:方法二
# for line in fo: #fo为文件句柄;此迭代可实现逐行读入
# print(line)
#数据的文件写入
fo=open("../data/output.txt","w+")
ls=["中国","法国","英国"]
fo.writelines(ls) #写入一个字符串列表
fo.seek(0) #如果没有这行,接下来将不会输出任何内容
for line in fo: #逐行读取
print(line)
fo.close()注意:Windows平台下的文件路径是斜杠\,但在python下斜杠\被解析为转义符,所以一般用反斜杠/代替("D:/PYE/f.txt");若要用斜杠\也行("D:\\PYE\\f.txt")
实例1(自动轨迹绘制)
根据脚本来绘制图形(不是写代码而是写数据绘制轨迹)
数据脚本是自动化重要的第一步(数据和功能分离)
data文件内容如下图:
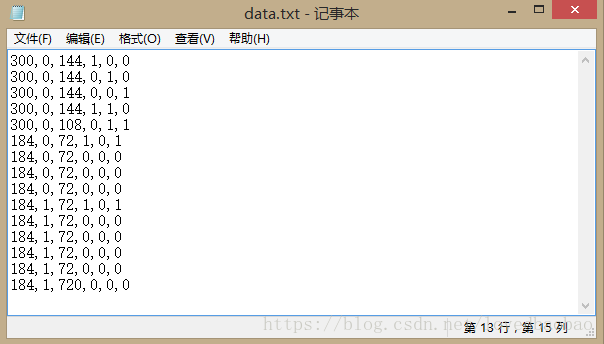
#AutoTraceDraw.py
#自动轨迹绘制
import turtle as t
t.title("自动轨迹绘制")
t.setup(800,600,0,0)
t.pencolor("red")
t.pensize(5)
#t.goto(-200,-170)
#t.setposition(-200,-170) #如果此时pendown()则"海龟会从原点跑到(-200,-170)并留下痕迹,setpos()和setposition()效果相同"
#数据读取
datals=[] #列表
f=open("../data/data.txt")
for line in f:
line=line.replace("\n","") #将换行符用空字符串代替
datals.append(list(map(eval,line.split(",")))) #执行顺序从里到外;map内置函数将第一个参数(函数名)的功能作用于第二个参数(迭代类型)的每一个元素
f.close()
#自动绘制
for i in range(len(datals)): #逐一遍历每个“整数”
t.pencolor(datals[i][3],datals[i][4],datals[i][5]) #三四五为RGB值
t.forward(datals[i][0]) #零为前进距离
if datals[i][1]: #一为转向,=1则右转,=0则左转
t.right(datals[i][2]) #二为转向角度
else:
t.left(datals[i][2])
t.hideturtle()
t.done()运行结果:
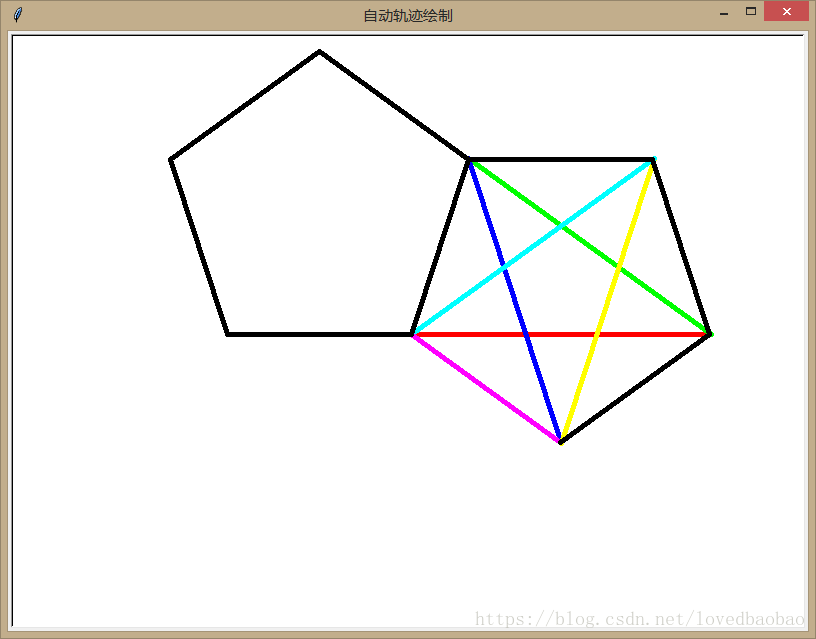
一维数据的格式化
- 数据的操作周期:存储<->表示<->操作
- 由对等关系的有序或无序数据构成,采用线性方式组织(对应python中列表、数组和集合概念)
存储方式:
1.空格分隔(缺点:数据中不能存在空格)
2.逗号(英文半角)分隔(缺点:数据中不能有英文逗号)
3.其他方式(建议采用特殊符号):中国$美国$日本$德国$法国$英国$意大利
一维数据的处理(存储<->处理):
1.从空格分隔的文件中读入数据
#中国 美国 日本 德国 法国 英国 意大利
txt=open(fname).read()
ls=txt.split() #利用空格分隔字符
f.close()->['中国','美国','日本','德国','法国','英国','意大利']
2.从特殊符号分隔的文件中读入数据(同上split('$'))
3.采用空格分隔方式将数据写入文件
ls=['中国','美国','日本']
f=open(fname,'w')
f.write(''.join(ls)) #将空格加入到列表每个元素之间
f.close()4.采用特殊分隔方式将数据写入文件(同上write('$'.join(ls)))
二维数据的格式化
- 由多个一维数据构成,是一维数据的组合形式(一般使用(二维)列表类型)
[ [3.1398,3.1349,3.1376],
[3.1413,3.1404,3.1401] ]
- 使用两层for循环遍历每个元素
ls=[[],[],[]] #二维列表
for row in ls:
for column in row:
print(ls[row][column])CSV(Comma-Separated Values)数据存储格式
- 是国际通用的一二维数据存储格式,一般.csv扩展名
- 逗号分隔(英文半角)表示一维(逗号与数据之间无额外空格),按行分隔表示二维
- 如果某个元素缺失,逗号仍要保留
- 二维数据的表头可以作为数据存储,也可以另行存储
- 若数据本身包含逗号,不同的CSV软件有不同的约定(如:在数据两侧加双引号)
- 按行存或者按列存都可以,具体由程序决定(一般索引习惯:ls[row][column],先行后列,根据一般习惯,外层列表的每个元素是一行,按行存)
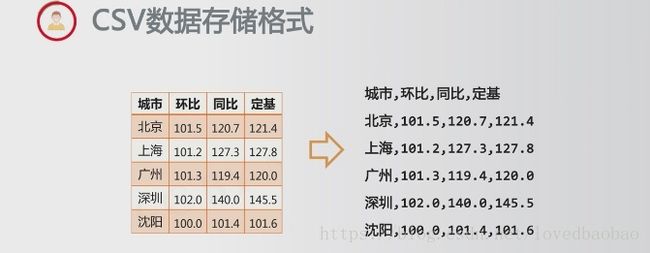
二维数据的处理:
1.从CSV格式的文件中读入数据
fo=open(fname]
ls=[]
for line in fo:
line=line.replace("\n","") #将行尾的回车符替换为空字符串
ls.append(line.split(","))
fo.close()2.将数据写入CSV格式的文件
ls=[[],[],[]] #二维列表
f=open(fname,"w")
for item in ls: #将列表中的每个元素作为一行写入CSV格式文件
f.write(','.join(item)+'\n')
f.close()多维数据
由一维或二维数据在新维度上扩展形成
高维数据
仅利用最基本的二元关系展示数据间的复杂结构(键值对)

wordcloud:词云展示的第三方库
- 词云以词语为基本单位,更加直观和艺术的展示文本
- wordcloud把词云当作一个WordCloud对象(wordcloud.WordCloud()代表一个文本对应的词云)
- 可以根据文本中词语出现的频率等参数绘制词云
wordcloud库常规方法:
步骤1:配置对象参数
步骤2:加载词云文本
步骤3:输出词云文件

wordcloud配置对象参数:
| 参数 | 描述 |
| width | 指定词云对象生成图片的宽度,默认400px >>>w=wordcloud.WorldCloud(width=600) |
| height | 指定词云对象生成图片的高度,默认200px >>>w=wordcloud.WorldCloud(height=400) |
| min_font_size | 指定词云中字体的最小字号,默认4号 >>>w=wordcloud.WorldCloud(min_font_size=10) |
| max_font_size | 指定词云中字体的最大字号,根据高度自动调节 >>>w=wordcloud.WorldCloud(max_font_size=20) |
| font_step | 指定词云中字体字号的步进间隔,默认为1 >>>w=wordcloud.WorldCloud(font_step=2) |
| font_path | 指定字体文件的路径,默认None >>>w=wordcloud.WorldCloud(font_path="msyh.ttc") |
| max_words | 指定词云显示的最大单词数量,默认200 >>>w=wordcloud.WorldCloud(max_words=20) |
| stop_words | 指定词云的排除词列表,即不显示的单词列表 >>>w=wordcloud.WorldCloud(stop_words={"Python"}) |
| mask | 指定词云形状,默认为长方形,需要引用imread()函数 >>>from scipy.misc import imread >>>mk=imread("pic.png") >>>w=wordcloud.WorldCloud(mask=mk) |
| background_color | 指定词云图片的背景颜色,默认为黑色 >>>w=wordcloud.WorldCloud(background_color="white") |
#TestWordCloud.py
import wordcloud
c=wordcloud.WordCloud() #定义词云对象
c.generate("HuiRuoQi And ZhuTing")
c.to_file("pywordcloud.png") #默认400*200
"""
以上程序wordcloud分4步进行:
1.分隔:以空格分隔单词
2.统计:单词出现次数并过滤
3.字体:根据统计配置字号
4.布局:颜色环境尺寸
"""得到图片:
#TestWordCloud2.py
import wordcloud
import jieba
#英文词云
txt="life is short,you need python"
w=wordcloud.WordCloud(background_color="white")
w.generate(txt)
w.to_file("pywcloud.png")
#中文词云
#因为wordcloud库利用空格进行分词,而中文本身不是以空格为分割线,所以需要先手动空格分隔
txt="中国女排郎平惠若琪朱婷张常宁刘晓彤颜妮袁心玥龚翔宇杨方旭魏秋月丁霞林莉\
段放杨珺箐王梦洁曾春蕾"
w=wordcloud.WordCloud(width=1000,font_path="msyh.ttc",height=700) #字体为微软雅黑
w.generate(" ".join(jieba.lcut(txt)))
w.to_file("pywcloud2.png")得到的图片:


实例2(政府工作报告词云)
生成词云->优化词云
用到的文本下载地址:
https://python123.io/resources/pye/%E6%96%B0%E6%97%B6%E4%BB%A3%E4%B8%AD%E5%9B%BD%E7%89%B9%E8%89%B2%E7%A4%BE%E4%BC%9A%E4%B8%BB%E4%B9%89.txt
https://python123.io/resources/pye/%E5%85%B3%E4%BA%8E%E5%AE%9E%E6%96%BD%E4%B9%A1%E6%9D%91%E6%8C%AF%E5%85%B4%E6%88%98%E7%95%A5%E7%9A%84%E6%84%8F%E8%A7%81.txt
#GovRpWordCloudV1.py
import jieba
import wordcloud
import scipy.misc as sci #SciPy是一组专门解决科学计算中各种标准问题域的包的集合
mask=sci.imread("../data/fivestar.jpg") #imread读取图片颜色数据,所以背景需为白色
#mask=sci.imread("../data/chinamap.jpg")
f=open("../data/新时代中国特色社会主义.txt","r",encoding="utf-8")
#f=open("../data/关于实施乡村振兴战略的意见.txt","r",encoding="utf-8")
t=f.read()
f.close()
ls=jieba.lcut(t)
txt=" ".join(ls)
w=wordcloud.WordCloud(font_path="msyh.ttc",width=1000,height=700,background_color="white"\
,max_words=100,mask=mask)#配置
w.generate(txt) #加载
w.to_file("govwordcloud1.png") #生成词云图片
#w.to_file("govwordcloud2.png") #生成词云图片得到图片:

