理解Attention注意力的本质(附代码讲解与案例)
大部分关于attention的文章都是对‘attention is all your need‘这篇文章的讲解,对初学者并不友好,省略了很多先决知识,这篇文章翻译自’Attention Mechanism’,并结合了自己的理解,力求从浅入深地讲解attention机制的本质。
注:阅读本文之前需要对RNN结构有了解
可参考https://cuijiahua.com/blog/2018/12/dl-11.html
什么是注意力?
当我们想起‘注意力’(attention)这个词时,我们知道这意味着它会引导你专注于某个事物并引起更大的注意。像黑体加粗就是一种注意力。注意力机制在深度学习中则意味着在处理数据时我们会对某些因素(factors)给予更多的注意。
在更广的层面上看,attention是网络结构的一个组成,并由它负责管理和量化 相互依赖(inter-dependence):
1.在输入和输出元素之间(General Attention)
2.在输入元素之内(Self-Attention)
我们来看看一个attention在机器翻译中的例子。如果我们有句子 “How was your day”,想把它翻译成法语- “Comment se passe ta journée”。attention会做的就是把输入句子中重要且相关的词映射(map)到输出句子中的词,并且给这些词更高的权重,提升输出预测的准确性。
 在翻译的每一步,权重都被赋予到输入词上
在翻译的每一步,权重都被赋予到输入词上
上述关于attention的解释比较宽泛与模糊,因为目前有许多种attention。在这里我们只介绍最常用的几种attention,它们常常用于sequence-to-sequence模型。虽然attention机制在计算机视觉有一定的应用,但目前它仍主要用于NLP任务,比如解决机器翻译中长序列的问题。
我们经常看到attention有如下的解释,但这种解释不够细致、深入,忽略了许多的先决知识,对初学者并不友好。

下面,我们将从本质来讲解推导attention机制
Attention in Sequence-to-Sequence Models

普通的seq2seq模型通常不能处理长的输入序列,因为在encoder中,只有最后一层的隐藏层才能作为decoder的上下文(context)向量,如图中黑色箭头所示。
而attention直接解决了这个问题因为它保存并利用了encoder的所有隐藏层:它建立了一个特殊的映射,使得每一个encoder的隐藏层都能与decoder的输出有关联。这意味着当decoder生成一个输出时,它可以从这个输入序列中选出特殊的元素,而不是只从最后一层的隐藏层生成输出。
Attention的种类
attention主要有两种:Bahdanau Attention和Luong Attention
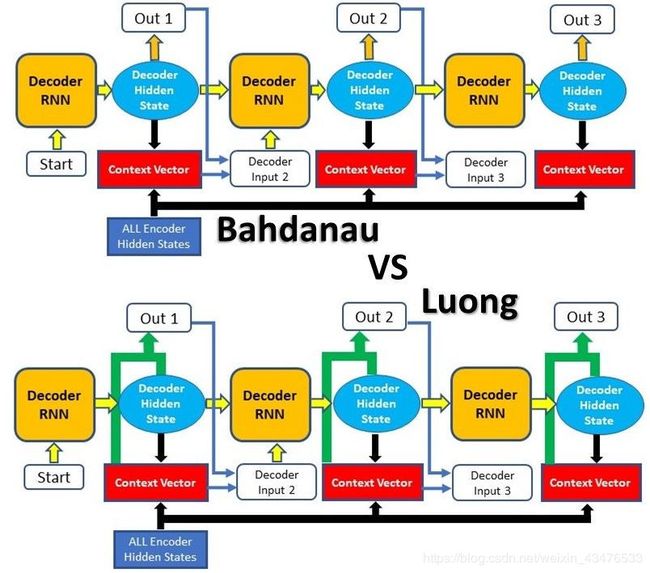
Attention的种类
第一种attention,通常叫做加性注意力(Additive Attention),来源于Dzmitry Bahdanau的论文。这篇文章旨在通过attention给予decoder以相关的输入句子。在该论文中,完整的步骤如下:
1.生成encoder的隐藏层
2.计算Alignment Scores (有些人翻译为相似度)
(注:encoder的最后一层隐藏层可用作decoder的第一层隐藏层)
3.对Alignment Scores进行softmax
4.计算上下文向量
5.对输出解码(decoding)
步骤2-5在每段时间(time step)不断重复直到有某种标志或输出超过了指定的最大长度。
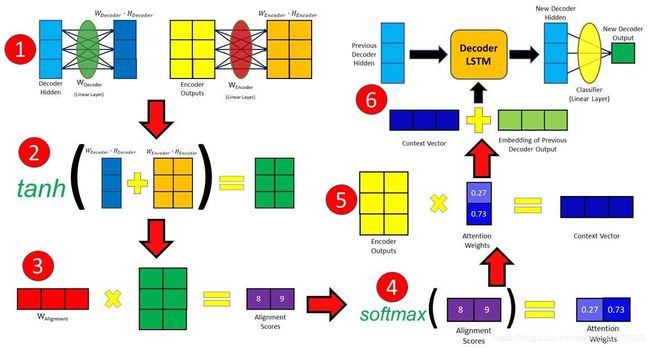
下面是具体阐述与代码讲解
1. Producing the Encoder Hidden States
首先,我们会用RNN或它的变体(LSTM,GRU)去解码(encode)输入序列。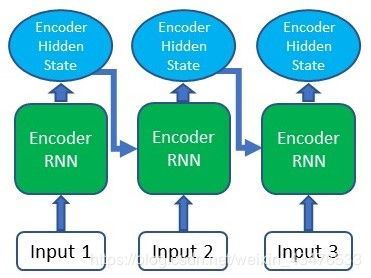
如图,每一个encoder RNN会对输入生成一个隐藏层状态。而后,我们会把隐藏层状态传给下一层RNN.
class EncoderLSTM(nn.Module):
def __init__(self, input_size, hidden_size, n_layers=1, drop_prob=0):
super(EncoderLSTM, self).__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.embedding = nn.Embedding(input_size, hidden_size)
self.lstm = nn.LSTM(hidden_size, hidden_size, n_layers, dropout=drop_prob, batch_first=True)
def forward(self, inputs, hidden):
#这里我们假设是语言任务,把输入embed成词向量
embedded = self.embedding(inputs)
#使词向量通过encoderLSTM,并返回输出
output, hidden = self.lstm(embedded, hidden)
return output, hidden
def init_hidden(self, batch_size=1):
return (torch.zeros(self.n_layers, batch_size, self.hidden_size, device=device),
torch.zeros(self.n_layers, batch_size, self.hidden_size, device=device))
2. 计算 Alignment Scores
下面是前向传播:
class BahdanauDecoder(nn.Module):
def __init__(self, hidden_size, output_size, n_layers=1, drop_prob=0.1):
super(BahdanauDecoder, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.drop_prob = drop_prob
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.fc_hidden = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
self.fc_encoder = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
self.weight = nn.Parameter(torch.FloatTensor(1, hidden_size))
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.drop_prob)
self.lstm = nn.LSTM(self.hidden_size*2, self.hidden_size, batch_first=True)
self.classifier = nn.Linear(self.hidden_size, self.output_size)
def forward(self, inputs, hidden, encoder_outputs):
encoder_outputs = encoder_outputs.squeeze()
# Embed input words
embedded = self.embedding(inputs).view(1, -1)
embedded = self.dropout(embedded)
# Calculating Alignment Scores
x = torch.tanh(self.fc_hidden(hidden[0])+self.fc_encoder(encoder_outputs))
alignment_scores = x.bmm(self.weight.unsqueeze(2))
# Softmaxing alignment scores to get Attention weights
attn_weights = F.softmax(alignment_scores.view(1,-1), dim=1)
# Multiplying the Attention weights with encoder outputs to get the context vector
context_vector = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
# Concatenating context vector with embedded input word
output = torch.cat((embedded, context_vector[0]), 1).unsqueeze(0)
# Passing the concatenated vector as input to the LSTM cell
output, hidden = self.lstm(output, hidden)
# Passing the LSTM output through a Linear layer acting as a classifier
output = F.log_softmax(self.classifier(output[0]), dim=1)
return output, hidden, attn_weights
再获得了所有的encoder输出后,我们可以开始用decoder产生输出了。
alignment score是attention机制的核心,因为在生成decoder输出时,它量化了在分配每个encoder输出的attention的量。
alignment score计算公式如下:
![]()
decoder隐藏层状态和encoder输出将会通过(pass through)各自的线性层,并得到它们的训练权重。
在上图中,隐藏层大小是3,encoder输出是2。因此,它们将会被相加,并经过tanh激活。在此例中,decoder隐藏层将会被加到每个encoder输出中。
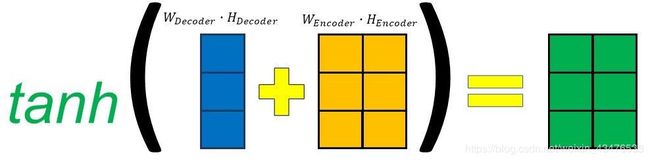
然后,再做矩阵乘法,得到最终的alignment score向量,每个encoder输出都有自己的得分。

注:因为decoder第一层没有之前的隐藏层和输出,则encoder的最后一层隐藏层和一个开始的标志 () 可以被用来分别替代这两项。
3 Softmaxing the Alignment Scores
在获得Alignment Score后,我们对其应用softmax,得到attention权重。
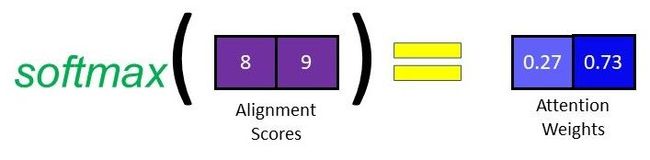
4. 计算上下文向量(Context Vector)
在得到attention权重后,我们通过把attention权重与encoder输出逐个相乘得到上下文向量。
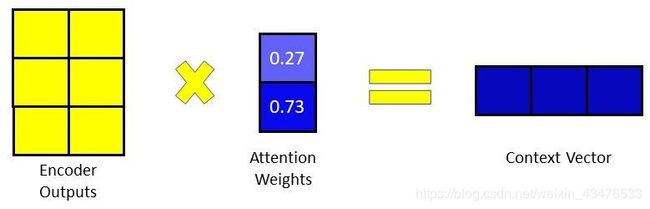
5. 对输出解码(decoding)
在产生上下文向量后,我们将其与之前的decoder输出合并(concatenate)。而后我们将其投入decoder RNN单元(这里是LSTM)得到一个新的decoder隐藏层。将新的decoder隐藏层经过线性层(分类)处理后,我们得到了最终的输出,它给出下一个预测词的概率分数。

重复步骤2-4直到decoder产生了一个结束标志(End Of Sentence token)或者输出长度超过特定的最长长度。
Luong Attention
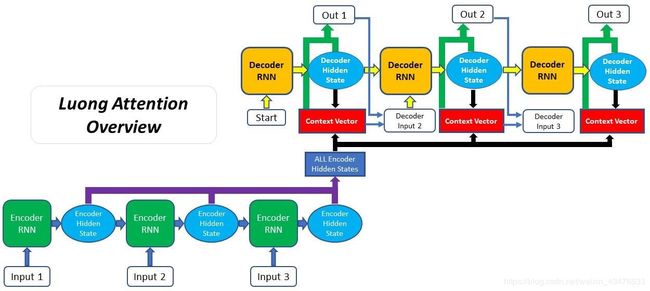
第二种attention是Thang Luong在论文里提到的,它通常叫做Multiplicative Attention,并且它是基于Bahdanau Attention建立的。
两者主要的差别在于:
1.alignment score计算方式不同
2.attention机制在decoder中应用的位置不同
在Luong的论文中介绍了3种计算alignment score的方法,而Bahdanau只介绍了一种。并且,通常的Attention Decoder框架结构不同于Luong Attention,因为上下文向量只是在RNN生成输出的时候被使用。接下来我们将详细的介绍Luong Attention:
(一定要结合图看 )
1.生成Encoder隐藏层——encoder生成输入序列中每个元素的隐藏层
2.Decoder RNN——之前的decoder隐藏层和输出经过RNN处理,产生新的隐藏层。
3.计算Alignment Scores——使用新的decoder隐藏层和encoder隐藏层计算alignment scores
4.Softmaxing the Alignment Scores
5.计算上下文向量——encoder隐藏层和它们各自的alignment scores相乘得到上下文向量。
6.生成最终输出——上下文向量和decoder隐藏层合并(concatenate),并通过全连接层生成新的输出。
the context vector is concatenated with the decoder hidden state generated in step 2 as passed through a fully connected layer to produce a new output
-
生成Encoder隐藏层
该步骤与Bahdanau一致 -
Decoder RNN
不同于Bahdanau Attention, Luong Attention里的decoder使用RNN作为第一步而非最后一步。RNN会用之前的隐藏层和之前最终输出(步骤6)生成一个新的隐藏层。
class LuongDecoder(nn.Module):
def __init__(self, hidden_size, output_size, attention, n_layers=1, drop_prob=0.1):
super(LuongDecoder, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.drop_prob = drop_prob
# The Attention Mechanism is defined in a separate class
self.attention = attention
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.dropout = nn.Dropout(self.drop_prob)
self.lstm = nn.LSTM(self.hidden_size, self.hidden_size)
self.classifier = nn.Linear(self.hidden_size*2, self.output_size)
def forward(self, inputs, hidden, encoder_outputs):
# Embed input words
embedded = self.embedding(inputs).view(1,1,-1)
embedded = self.dropout(embedded)
# Passing previous output word (embedded) and hidden state into LSTM cell
lstm_out, hidden = self.lstm(embedded, hidden)
# Calculating Alignment Scores - see Attention class for the forward pass function
alignment_scores = self.attention(lstm_out,encoder_outputs)
# Softmaxing alignment scores to obtain Attention weights
attn_weights = F.softmax(alignment_scores.view(1,-1), dim=1)
# Multiplying Attention weights with encoder outputs to get context vector
context_vector = torch.bmm(attn_weights.unsqueeze(0),encoder_outputs)
# Concatenating output from LSTM with context vector
output = torch.cat((lstm_out, context_vector),-1)
# Pass concatenated vector through Linear layer acting as a Classifier
output = F.log_softmax(self.classifier(output[0]), dim=1)
return output, hidden, attn_weights
class Attention(nn.Module):
def __init__(self, hidden_size, method="dot"):
super(Attention, self).__init__()
self.method = method
self.hidden_size = hidden_size
# Defining the layers/weights required depending on alignment scoring method
if method == "general":
self.fc = nn.Linear(hidden_size, hidden_size, bias=False)
elif method == "concat":
self.fc = nn.Linear(hidden_size, hidden_size, bias=False)
self.weight = nn.Parameter(torch.FloatTensor(1, hidden_size))
def forward(self, decoder_hidden, encoder_outputs):
if self.method == "dot":
# For the dot scoring method, no weights or linear layers are involved
return encoder_outputs.bmm(decoder_hidden.view(1,-1,1)).squeeze(-1)
elif self.method == "general":
# For general scoring, decoder hidden state is passed through linear layers to introduce a weight matrix
out = self.fc(decoder_hidden)
return encoder_outputs.bmm(out.view(1,-1,1)).squeeze(-1)
elif self.method == "concat":
# For concat scoring, decoder hidden state and encoder outputs are concatenated first
out = torch.tanh(self.fc(decoder_hidden+encoder_outputs))
return out.bmm(self.weight.unsqueeze(-1)).squeeze(-1)
3. 计算 Alignment Scores
在Luong Attention中,有3种不同的方式计算alignment score:
Dot
encoder与decoder的隐藏层相乘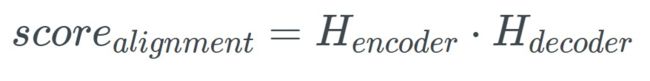 General
General
增加了一个权重矩阵

Concat
![]()
与Bahdanau Attention的是,在经过线性层(分类器)之前,decoder和encoder的隐藏层被加在一起。这意味着decoder和encoder的隐藏层不会有自己的权重矩阵,而是共享一个。
在经过线性层处理后,我们对输出进行tanh激活,而后与权重矩阵相乘得到alignment score。
4. Softmaxing the Alignment Scores
5. 计算上下文向量
6. 生成最终输出
这三步与之前一致
案例:机器翻译
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import pandas
import spacy
from spacy.lang.en import English
from spacy.lang.de import German
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
from tqdm import tqdm_notebook
import random
from collections import Counter
if torch.cuda.is_available:
device = torch.device("cuda")
else:
device = torch.device("cpu")
# Reading the English-German sentences pairs from the file
with open("deu.txt","r+") as file:
deu = [x[:-1] for x in file.readlines()]
en = []
de = []
for line in deu:
en.append(line.split("\t")[0])
de.append(line.split("\t")[1])
# Setting the number of training sentences we'll use
training_examples = 10000
# We'll be using the spaCy's English and German tokenizers
spacy_en = English()
spacy_de = German()
en_words = Counter()
de_words = Counter()
en_inputs = []
de_inputs = []
# Tokenizing the English and German sentences and creating our word banks for both languages
for i in tqdm_notebook(range(training_examples)):
en_tokens = spacy_en(en[i])
de_tokens = spacy_de(de[i])
if len(en_tokens)==0 or len(de_tokens)==0:
continue
for token in en_tokens:
en_words.update([token.text.lower()])
en_inputs.append([token.text.lower() for token in en_tokens] + ['_EOS'])
for token in de_tokens:
de_words.update([token.text.lower()])
de_inputs.append([token.text.lower() for token in de_tokens] + ['_EOS'])
# Assigning an index to each word token, including the Start Of String(SOS), End Of String(EOS) and Unknown(UNK) tokens
en_words = ['_SOS','_EOS','_UNK'] + sorted(en_words,key=en_words.get,reverse=True)
en_w2i = {o:i for i,o in enumerate(en_words)}
en_i2w = {i:o for i,o in enumerate(en_words)}
de_words = ['_SOS','_EOS','_UNK'] + sorted(de_words,key=de_words.get,reverse=True)
de_w2i = {o:i for i,o in enumerate(de_words)}
de_i2w = {i:o for i,o in enumerate(de_words)}
# Converting our English and German sentences to their token indexes
for i in range(len(en_inputs)):
en_sentence = en_inputs[i]
de_sentence = de_inputs[i]
en_inputs[i] = [en_w2i[word] for word in en_sentence]
de_inputs[i] = [de_w2i[word] for word in de_sentence]
hidden_size = 256
encoder = EncoderLSTM(len(en_words), hidden_size).to(device)
attn = Attention(hidden_size,"concat")
decoder = LuongDecoder(hidden_size,len(de_words),attn).to(device)
lr = 0.001
encoder_optimizer = optim.Adam(encoder.parameters(), lr=lr)
decoder_optimizer = optim.Adam(decoder.parameters(), lr=lr)
EPOCHS = 10
teacher_forcing_prob = 0.5
encoder.train()
decoder.train()
tk0 = tqdm_notebook(range(1,EPOCHS+1),total=EPOCHS)
for epoch in tk0:
avg_loss = 0.
tk1 = tqdm_notebook(enumerate(en_inputs),total=len(en_inputs),leave=False)
for i, sentence in tk1:
loss = 0.
h = encoder.init_hidden()
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
inp = torch.tensor(sentence).unsqueeze(0).to(device)
encoder_outputs, h = encoder(inp,h)
#First decoder input will be the SOS token
decoder_input = torch.tensor([en_w2i['_SOS']],device=device)
#First decoder hidden state will be last encoder hidden state
decoder_hidden = h
output = []
teacher_forcing = True if random.random() < teacher_forcing_prob else False
for ii in range(len(de_inputs[i])):
decoder_output, decoder_hidden, attn_weights = decoder(decoder_input, decoder_hidden, encoder_outputs)
# Get the index value of the word with the highest score from the decoder output
top_value, top_index = decoder_output.topk(1)
if teacher_forcing:
decoder_input = torch.tensor([de_inputs[i][ii]],device=device)
else:
decoder_input = torch.tensor([top_index.item()],device=device)
output.append(top_index.item())
# Calculate the loss of the prediction against the actual word
loss += F.nll_loss(decoder_output.view(1,-1), torch.tensor([de_inputs[i][ii]],device=device))
loss.backward()
encoder_optimizer.step()
decoder_optimizer.step()
avg_loss += loss.item()/len(en_inputs)
tk0.set_postfix(loss=avg_loss)
# Save model after every epoch (Optional)
torch.save({"encoder":encoder.state_dict(),"decoder":decoder.state_dict(),"e_optimizer":encoder_optimizer.state_dict(),"d_optimizer":decoder_optimizer},"./model.pt")
encoder.eval()
decoder.eval()
# Choose a random sentences
i = random.randint(0,len(en_inputs)-1)
h = encoder.init_hidden()
inp = torch.tensor(en_inputs[i]).unsqueeze(0).to(device)
encoder_outputs, h = encoder(inp,h)
decoder_input = torch.tensor([en_w2i['_SOS']],device=device)
decoder_hidden = h
output = []
attentions = []
while True:
decoder_output, decoder_hidden, attn_weights = decoder(decoder_input, decoder_hidden, encoder_outputs)
_, top_index = decoder_output.topk(1)
decoder_input = torch.tensor([top_index.item()],device=device)
# If the decoder output is the End Of Sentence token, stop decoding process
if top_index.item() == de_w2i["_EOS"]:
break
output.append(top_index.item())
attentions.append(attn_weights.squeeze().cpu().detach().numpy())
print("English: "+ " ".join([en_i2w[x] for x in en_inputs[i]]))
print("Predicted: " + " ".join([de_i2w[x] for x in output]))
print("Actual: " + " ".join([de_i2w[x] for x in de_inputs[i]]))
# Plotting the heatmap for the Attention weights
fig = plt.figure(figsize=(12,9))
ax = fig.add_subplot(111)
cax = ax.matshow(np.array(attentions))
fig.colorbar(cax)
ax.set_xticklabels(['']+[en_i2w[x] for x in en_inputs[i]])
ax.set_yticklabels(['']+[de_i2w[x] for x in output])
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
plt.show()