统计学习导论之读书笔记(四):重抽样方法(Resampling Methods)
统计学习导论之读书笔记(四):重抽样方法
- 1. 交叉验证法(Cross Validation, CV)
- 1.1 验证集方法(Validation set approach)
- 1.2 留一交叉验证法(leave-one-out-validation, LOOCV)
- 1.3 k折交叉验证法(k-fold CV)
- 2. 自助法(Bootstrap)
- 3 R语言实现
1. 交叉验证法(Cross Validation, CV)
1.1 验证集方法(Validation set approach)
方法原理:把获得的观测数据随机分为两部分:一部分为训练集(通常为原始数据集的一半),另一部分为验证集,或者叫保留集。在训练集上拟合模型,用拟合的模型在验证集上计算响应变量的值,进而得到验证集错误率,即测试错误率。
方法缺陷:
- 测试错误率的波动会很大,这取决于哪部分数据在训练集中,哪部分数据在验证集中。
- 在验证集方法中,只有一部分观测数据(没用到所有的数据)被用于拟合模型。由于训练的观测数据越少,统计方法的表现就会越差。这意味着,此方法可能会高估在整个数据集上拟合模型所得到的测试错误率。
1.2 留一交叉验证法(leave-one-out-validation, LOOCV)
LOOCV原理:将一个单独的观测数据 ( x 1 , x 2 ) (x_{1},x_{2}) (x1,x2)当作验证集数据,剩下的观测数据当作训练集数据。在训练集上训练模型,在验证集上计算MSE。重复这个步骤n次(数据量共总为n),对于每个观测数据,计算其MSE,最终的测试均方误差是n个MSE的均值,即:
C V ( n ) = 1 n ∑ i = 1 n M S E i \ CV_{(n)} = \frac{1}{n}\sum_{i=1}^{n}MSE_{i}\, CV(n)=n1i=1∑nMSEi
相对于验证集方法,LOOCV的优点为:
- 偏差较小,由于反复用包含n-1个观测数据来训练模型,观测数几乎与整个数据集中的数据量相等,所以LOOCV相比于验证集方法不容易高估测试误差率。
- 相比于验证集方法,LOOCV方法在训练集和验证集的分割下不存在随机性。(因为每个数都被选出来当作验证集了),所以每次运用LOOCV方法总会得到相同的结果。
1.3 k折交叉验证法(k-fold CV)
k折交叉验证法类似LOOCV。它的原理是:将观测集随机地分为k个大小基本一致的组,或者说折(fold)。第一折作为验证集,然后在剩下的 k − 1 k-1 k−1折上拟合模型,并在验证集上计算MSE1。重复这个步骤 k k k次,每一次把不同的观测组作为验证集。最后计算这 k k k个MSE的均值,公式如下:
C V k = 1 k ∑ i = 1 k M S E i \ CV_{k} = \frac{1}{k}\sum_{i=1}^{k}MSE_{i}\, CVk=k1i=1∑kMSEi
使用k-fold CV时,一般令 k = 5 k=5 k=5或 k = 10 k=10 k=10,目的是为了计算方便,LOOCV方法计算量大。
2. 自助法(Bootstrap)
很多时候我们的样本数据没有那么多,这时候可以使用bootstrap的方式来对一个数据集进行重抽样,其基本思想是:反复地从原始数据集中有放回地抽取观测数据得到多个数据集进行实验。
bootstrap可以衡量一个指定的统计量或统计学习方法中不确定的因素。如:它可以用来估计一个线性回归拟合模型的系数的标准差。
3 R语言实现
对于任意一个广义线性模型,都可以用glm()和在boot库里面的cv.glm()来实现LOOCV或k-fold CV。如下是用ISLR库中的Auto数据给出的例子:
LOOCV
library(ISLR)
glm.fit <- glm(mpg ~ horsepower, data = Auto)
library(boot)
cv.error <- cv.glm(Auto, glm.fit)
LOOCV <- cv.error$delta[1] # 最终LOOCV值
k-fold CV
glm.fit <- glm(mpg ~ horsepower, data = Auto)
library(boot)
CV <- cv.glm(Auto, glm.fit, K = 10)$delta[1] # 采用10折CV计算得到的CV
bootstrap
实现bootstrap需要两个步骤:
(1)写出待估系数或者统计量的函数
(2)使用boot库中的boot()函数
如下使用Auto数据给出简单线性回归拟合模型中的 β 1 , β 2 \beta_{1},\beta_{2} β1,β2的标准差的估计:
先写一个函数boot.fn,它返回的是线性回归模型的截距和斜率的估计值
boot.fn <- function(data, index)
return(coef(lm(mpg ~ horsepower, data = data, subset = index)))
接着使用boot()函数计算截距和斜率项的标准差的估计值
boot(Auto, boot.fn, R = 1000) # R = 1000 表示从Auto数据中有放回地抽样了1000次
以下是运行结果:
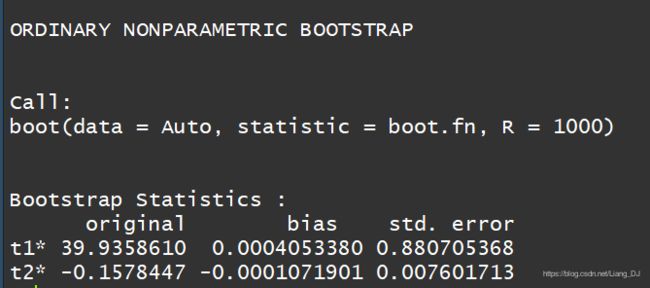
从Bootstrap Statistics中的std.error可以看到 β 1 , β 2 \beta_{1},\beta_{2} β1,β2的标准差的估计值。