利用selenium抓取英雄联盟壁纸
本博客主要来利用selenium这一利器来爬取LOL官网各个英雄皮肤的壁纸,注意是壁纸,不是图片!壁纸是图片,但图片不是壁纸。
selenium是一个自动化测试工具,利用它可以驱动浏览器执行一些特定的操作,比如点击、下拉等操作,由于selenium是模拟人的行为,所以对一些JavaScript渲染的网页特别有效 ,而且不易被封号或者反爬限制,但是爬取效率慢。selenium安装以及基本方法的使用详见https://blog.csdn.net/LuoZheng4698729/article/details/78032362?locationNum=5&fps=1博主昵称罗政,如果有机会,我会把我自己当时做的关于selenium库的笔记发上来,与大家一起交流。
下面我们进入正题,怎么利用selenium爬取LOL官网的所有英雄皮肤壁纸,网上有很多的关于爬取王者荣耀的英雄皮肤壁纸,LOL英雄壁纸的爬取相对王者荣耀的难度大,首先LOL官网上面的英雄信息全是异步加载的(非ajax加载),也就是说用一般的方法难以找到各个英雄信息的链接,而王者荣耀的官网的皮肤信息在源代码中就可以找到,所以难度不大,直接利用requests和正则即可。
首先,我们进入英雄联盟官网的资料库URL=http://lol.qq.com/web201310/info-heros.shtml(一波回忆杀。。。),然后查看源代码,我们在源代码里面看不到相关的英雄数据,同样的我们利用审查元素,也是找不到一些关于英雄ajax加载的信息。
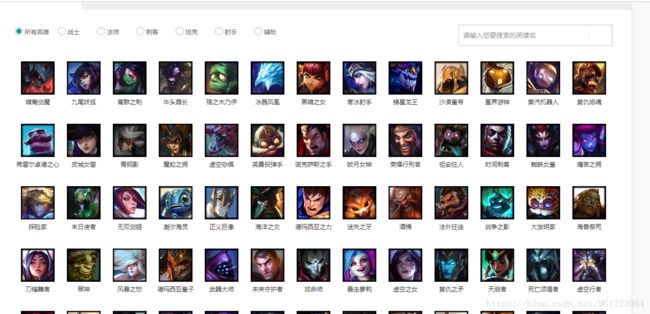
于是,我们想到利用selenium来抓取信息,首先进入该页面,然后通过点英雄图像,利用审查元素查看得到如下图所示的元素,我们可以看到在a 节点下面有个链接,点击进去,得各个单独的英雄的信息,这样我们到时候就可以在单独的页面提取英雄的皮肤信息

到此,我们已经完成了程序的一小步,部分程序如下:
from selenium import webdriver
import time ,requests
hero=[]
brower = webdriver.Chrome() #初始化,利用谷歌驱动
brower.get('http://lol.qq.com/web201310/info-heros.shtml') #模拟浏览器登录url初始网站
time.sleep(3) #设置等待,可以设置高级等待方式----显示等待
brower.execute_script("window.scrollBy(0,1500)") #滑动鼠标滚轮,使其到达页面尾部。
infor=brower.find_element_by_css_selector('#jSearchHeroDiv') #定位元素
#print(infor.text)
links=infor.find_elements_by_css_selector('li>a')
for link in links :
urls=link.get_attribute('href')
hero.append(urls.split())
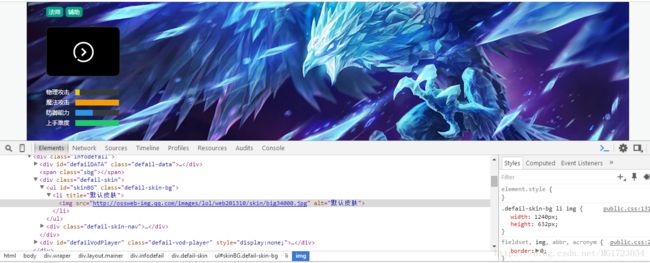
print(hero) #定位多元素,利用for一个个的将各个英雄的详细信息链接放入一个列表中继续,我们在各个英雄单独页面中,点击背景图片,点击审查元素,如图所示,我们可以看到,该元素中只有一个皮肤的大壁纸,而该英雄其他皮肤信息没有出现。这样我们该怎么办?

其实也很简单,我们点击其他皮肤的任意一个,再点击审查元素,我们就可以看到该英雄所有皮肤的信息,如下图所示,当然,selenium中的点击可以用.cick()来实现, 最后我们就是根据elements里面的节点来定位元素,最后提取元素属性。

该节的代码如下:
for m in range(len(hero)) : ##单独的提取一个个英雄的详细信息网址
#print(hero[m][0])
brower.get(hero[m][0]) #进入单个英雄的网页
time.sleep(2)
brower.execute_script("window.scrollBy(100,800)") #将网页移动到视野可见,两个值#(100,800)可以自己设置。
brower.find_element_by_css_selector('#skinNAV').find_elements_by_css_selector('li a')[1].click() #模拟点击
skins=brower.find_element_by_css_selector('#skinBG').find_elements_by_css_selector('li') #定位皮肤信息位置
for skin in skins :
skin_name=skin.get_attribute('title')
img_url=skin.find_element_by_css_selector('img').get_attribute('src')
if skin_name=='默认皮肤':
skin_name='默认皮肤'+hero[m][0].split('?')[1] #数据处理,因为每一个英雄都有##一个默认皮肤,所以将英雄的默认皮肤名称改为默认皮肤+英雄id,这样在下载的时候,前面英雄的默认皮肤####不会被后面英雄的默认皮肤冲掉。
img=requests.get(img_url) ####requests请求img所在的网址
print(skin_name,img_url)
filename='C:\\Users\\FangWei\\Desktop\\网络爬虫\\爬取英雄联盟壁纸\\'+skin_name+'.jpg'
with open(filename,'wb') as f:
f.write(img.content) ####下载图片
print('图片已下载')最后,提出一个问题:我们在定位元素时候是在#skinBG的节点下得到的皮肤图片,多一步点击,有人说,我在#skinNAV节点下就可以得到该英雄的所有皮肤信息,而且也有图片,为什么我还要利用你这个方式,还多一步点击?原因如下:
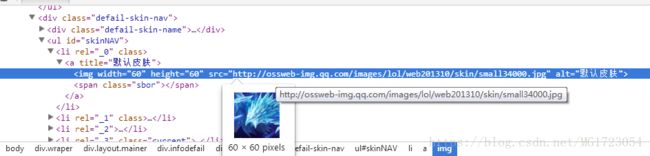
利用#skinBG下面的节点时候获得的皮肤是980*500像素,而利用上面问题提出的方法得到的是60*60像素,我们爬取的是壁纸,不是图片,所以我们不能利用#skinNAV节点下的元素来获取img网址,再下载。

爬取到的部分结果截图如下:

本内容的所有代码:
# -*- coding: utf-8 -*-
"""
Created on Mon May 7 22:47:56 2018
@author: NJUer
"""
from selenium import webdriver
import time ,requests
hero=[]
brower = webdriver.Chrome()
brower.get('http://lol.qq.com/web201310/info-heros.shtml')
time.sleep(3)
brower.execute_script("window.scrollBy(0,1500)")
infor=brower.find_element_by_css_selector('#jSearchHeroDiv')
#print(infor.text)
links=infor.find_elements_by_css_selector('li>a')
for link in links :
urls=link.get_attribute('href')
hero.append(urls.split())
print(hero)
for m in range(len(hero)) :
print(hero[m][0])
brower.get(hero[m][0])
time.sleep(2)
brower.execute_script("window.scrollBy(100,800)")
brower.find_element_by_css_selector('#skinNAV').find_elements_by_css_selector('li a')[1].click()
skins=brower.find_element_by_css_selector('#skinBG').find_elements_by_css_selector('li')
for skin in skins :
skin_name=skin.get_attribute('title')
img_url=skin.find_element_by_css_selector('img').get_attribute('src')
if skin_name=='默认皮肤':
skin_name='默认皮肤'+hero[m][0].split('?')[1]
img=requests.get(img_url)
print(skin_name,img_url)
filename='C:\\Users\\FangWei\\Desktop\\网络爬虫\\爬取英雄联盟壁纸\\'+skin_name+'.jpg'
with open(filename,'wb') as f:
f.write(img.content)
print('图片已下载')
原创不易,如若转载,请注明出处,谢谢!!!