中文预训练模型ZEN开源,效果领域内最佳,创新工场港科大出品
允中 发自 凹非寺
量子位 报道 | 公众号 QbitAI
改进策略简单有效、收敛速度快,同时小数据效果出色。
这就是中文预训练模型ZEN。
在中文任务中,ZEN不仅性能优于BERT,也比之前中文预训练模型更好。
可以说是目前全球中文领域最佳预训练模型。
而且现在,ZEN开源了。源代码和训练好的模型均已发布,未来还承诺会有更大数据和其他语言版本迭代上新。
详情我们展开往下说。
ZEN因何而生
随着BERT(Devlin et al., 2018)等一系列预训练模型的出现,该类型上下文相关表征方法受到了自然语言处理领域持续大范围的关注。
这些预训练模型带来的好处是显而易见:
一方面,它们可以利用大规模无标注纯文本语料进行学习;
另一方面,它们是对于文本的有效表征,并且大量实验表明,基于预训练模型的各类NLP模型相比于以前的方法能带来巨大的性能提升。
一般来说,预训练模型研究通常分为两个步骤:第一步是预训练 (pre-training),第二步是微调整 (fine-tune)。
其中,预训练是指通过在大规模无标注的语料上进行无监督训练,来学习通用的语言表达和上下文行文特点。
微调整指在特定的任务上,再次利用任务数据训练和调整预训练模型参数的过程。
目前,大多数中文预训练模型基本上沿用了英文模型的做法,聚焦于小颗粒度文本单元(字)的输入。
然而,与英文相比,中文没有空格等明确的词语边界。
这个特点使得很多文本表达中存在的交叉歧义也被带入了以字为序列的文本编码中,使得模型更难从单字的序列中学习到大颗粒度文本蕴含的语义信息,例如双字或者多字词的整体含义等。
虽然通过大规模文本建模可以一定程度上区分不同上下文环境的语义,但是依然没有充分并显式地利用预训练和微调整语料中经常出现的词、短语、实体等更大颗粒度的信息。
目前很多模型的解决方法依然是遵循传统BERT模型的遮盖(masking)策略,例如采用多层(词,短语等)遮盖策略来弥补这一缺陷。
然而遮盖策略依然只是一种弱监督学习方法,用于学习词边界信息含有诸多问题:
第一,信息的质量无法得到保证,例如BERT-wwm(Cui et al., 2019)的效果依赖于外部中文分词的质量;
第二,因为基于遮盖方式训练存在一个基础难题,即遮盖过程在训练中存在,但是在测试过程中并不存在,因此直接利用遮盖方式学习的词和短语信息会导致训练和测试过程的不匹配。
因此,如果能够有效集成大颗粒度文本的信息,并且在训练和测试过程中显式地加入这样的信息将有助于提升模型的表征能力。
于是,基于BERT的n-gram增强中文文本编码器ZEN,由此而生。
它可以显式地结合潜在词语的边界信息来帮助模型更好地对文本进行表征。ZEN有两大优势:
简单有效。从数据上看,与其他模型引入更多数据不同,ZEN仅仅基于中文维基百科进行训练。
ZEN不需要更多的数据集,但是却显示出了与其他模型相当的效果。从模型上看,引入n-gram编码器的方式简单灵活,不需要其他繁杂的预训练优化方式。
收敛迅速。因为模型结构简单,实验表明相比于原生BERT,ZEN模型收敛速度明显提高,在更短的时间内取得了更好的效果。这对于资源紧张的研究人员来讲,无疑是一个好消息。
另外,在涵盖词汇级和句子级两个层级的七大经典中文语言处理任务中——包括中文分词(CWS),词性标注(POS),命名实体识别(NER),文本分类(DC),情感分类(SA),语义匹配(SPM),自然语言推理(NLI),ZEN在七个下游任务上都带来了显著的提升。同时本文还在小规模数据集上进行了实验,模拟了只有少量预训练数据语料的场景。
而且ZEN如此效果,也展示了未来应用到其他文本受限领域的潜力,比如医疗。
同时,该研究中加入大颗粒度文本的方式是一种通用的增强方式,未来可在中文之外的其他语言上也得到应用。
具体模型
ZEN的模型架构如图所示:
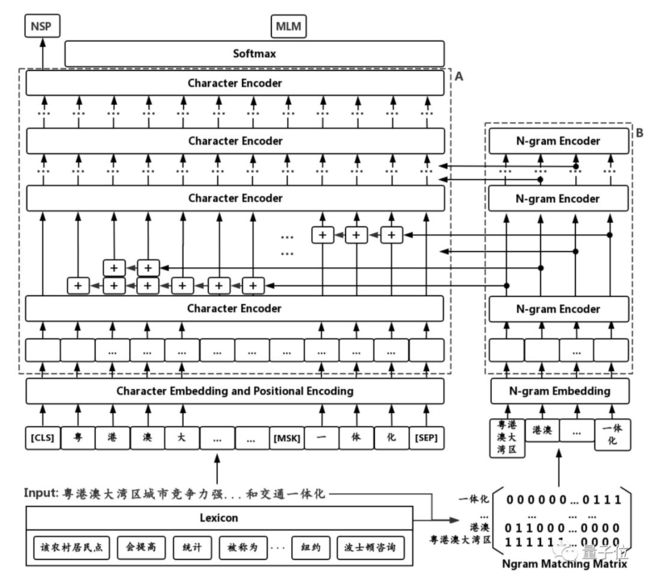
△ZEN 模型架构图
N-gram 抽取
首先,利用已有的预训练语料,基于频率来抽取n-gram,构造n-gram 词汇表(lexicon)。
其次,模型在将单字的序列作为输入的同时,也将出现的n-gram作为输入标记。利用已有的词汇表,对预训练数据中的每一个输入,抽取句中出现的n-gram。
N-gram 编码
给定一个输入句子相应的多个n-gram,本文利用了一个6层的transformer结构作为n-gram encoder,来对输入的n-gram提取特征进行编码。n-gram的嵌入向量经过n-gram encoder,得到n-gram的表示。
有了n-gram的表示之后,ZEN将字(Character)的表示与每个字对应的n-gram向量表示结合起来,在输出端相加,并一起被输入至后续结构之中。
结合n-gram和字编码的预训练
如图1所示,输入的带n-gram标记的句子首先会经过嵌入层 (Embedding Layer)。在这一层里,每个输入的单字和n-gram会被替换成嵌入矩阵中对应位置的向量。
与此同时,每个向量会被加上一个Positional Encoding,用来表示其在句子之中出现的位置。
之后,字的嵌入向量会被输入Character Encoder,进行计算并得到每个字在这一层的向量表达。
与此同时,n-gram的嵌入向量会被输入n-gram encoder。两部分输出会被同时输入attention encoder。
模型的最末端会被接入全连接层和Softmax层结构来帮助完成预训练。
实验结果

如上图,ZEN的总体性能及其与现有模型在七项NLP任务上的比较情况。
文章对BERT和ZEN两个模型分别实现了两组设置:R(随机初始化) 和 P(基于谷歌开源的BERT中文模型进行初始化)。
实验结果表明,在两组设置上,ZEN都取得了比BERT更好的性能。
同时,ZEN与现有的其他模型在七个任务上进行了比较,ZEN取得了包括CWS、POS、NER、DC、SPM在内的五个任务上最好的结果。
在仅仅利用中文维基百科,没有其他语料的前提下,在情感分类和自然语言推理任务上也达到了相当不错的表现。
分析讨论
小数据集潜力
除了以上实验,该研究还探究了模型在小数据集上的潜力。
考虑到目前的预训练模型使用了大型的训练语料,但是对于很多特殊的领域,大型数据集很难获取。
因此本文抽出1/10的中文维基百科语料,来模拟了一种语料有限的场景,目的是探究ZEN在小数据集上的潜力。
实验结果如下图所示,在全部七个任务上,ZEN都明显优于BERT。这表明ZEN在数据有限的场景下,具有更大的潜力。

△BERT和ZEN利用小语料训练, 在七项NLP任务上的表现
收敛速度
中文分词和情感分类两个任务被用于该分析的探测任务,来探究BERT与ZEN的收敛速度造成在这些任务上性能的差异。
两个任务上的实验都表明,ZEN可以在更少的迭代次数情况下达到更高的性能。
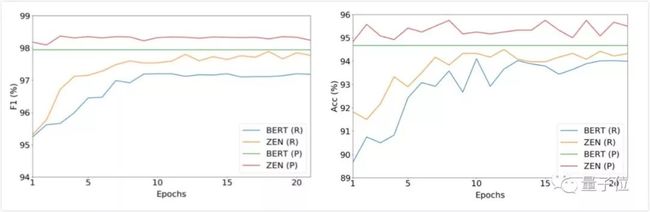
如上图,BERT与ZEN在中文分词任务(左图)和情感分类任务(右图)收敛速度的比较情况。
热图分析
通过热度图,还通过实验分析了两个案例,将n-gram encoder的注意力机制可视化出来。
通过热度图可以清晰地看到,注意力会更多的关注在有效的n-gram。比如“波士顿”的权重明显高于“士顿”。对于有划分歧义的句子,n-gram encoder可以正确的关注到“速度”而不是“高速”。
更加有趣的是,在不同层次的encoder关注的n-gram也不同。更高层的encoder对于“提高速度”和“波士顿咨询”这样更长的有效n-gram分配了更多的权重。
这表明,结合n-gram的方法的预训练,不仅仅提供给文本编码器更强大的文本表征能力,甚至还间接产生了一种文本分析的有效方法。这个案例分析暗示我们,或许将来可以用类似地方法提供无指导的文本抽取和挖掘
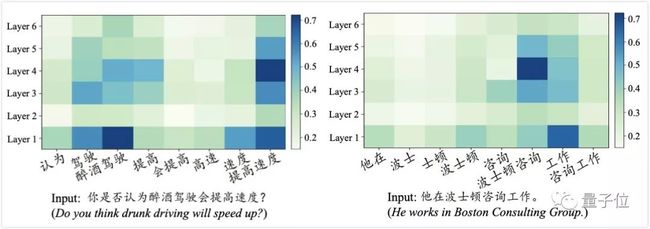
△案例分析-热度图
结语
所以通过研究解析,也可以看出,ZEN对高概率成词的n-gram添加了独有的编码和向量表示,此模型可以提供更强的文本的编码能力和理解能力。
在多个中文自然语言任务之上都有比基于单字的语言模型有更好的表现效果。
与之前的中文预训练模型相比,ZEN的优势在于提出的改进策略简单有效并且收敛速度快,同时在有限语料的基础上可以达到更大规模语料的训练效果。
相比于大多数已有研究对预训练策略的改进,ZEN是为数不多的对预训练模型架构进行了改进的工作。
这也带来更进一步的启示,可以深度探索已有模型的内部机制,进一步分析文本及其表征模型中蕴含的Zen——禅意。

作者
最后,简单介绍下ZEN模型背后的团队。
这是创新工场AI工程院和香港科技大学的联合研究。
或许对于VC身份的创新工场你已熟悉,但如此深入开展科研和前沿技术开源的创新工场旗下组织,你可能还不那么熟悉。

创新工场AI工程院成立于2016年9月,以“科研+工程实验室”模式,规划研发方向发展。
而且这也不是创新工场AI工程院首次成果展示,光2019年,其联合国内外科研高校,就有过8篇顶会论文研究披露。
包含NeurIPS 2019、ICCV、IROS、EMNLP、IEEE TVCG等在内的顶会和顶级期刊,均有创新工场AI工程院的身影。

此外值得一体的是,今年创新工场AI工程院还有一篇区块链技术论文入选计算机网络顶级学术会议NSDI,这是国际主流学术界首次认可区块链扩容方案的相关研究,是该会议今年录取的唯一一篇与区块链相关的论文。
创新工场也积极参与了国际相关的技术标准制定工作。例如,今年8月,第28届国际人工智能联合会议(IJCAI)在中国澳门隆重举办,期间召开了IEEE P3652.1(联邦学习基础架构与应用)标准工作组第三次会议。
领军人才方面,香港科技大学教授、前腾讯AI Lab主任张潼目前是创新工场科研合伙人、创新工场大湾区AI研究院名誉院长。
香港科技大学也是创新工场的重要合作机构之一,今年3月20日,香港科技大学和创新工场还联合宣布成立计算机感知与智能控制联合实验室(Computer Perception and Intelligent Control Lab)。
按照官方披露,目前创新工场AI工程院设有医疗AI、机器人、机器学习理论、计算金融、计算机感知等面向前沿科技与应用方向的研发实验室,还先后设立了创新工场南京国际人工智能研究院、创新工场大湾区人工智能研究院。
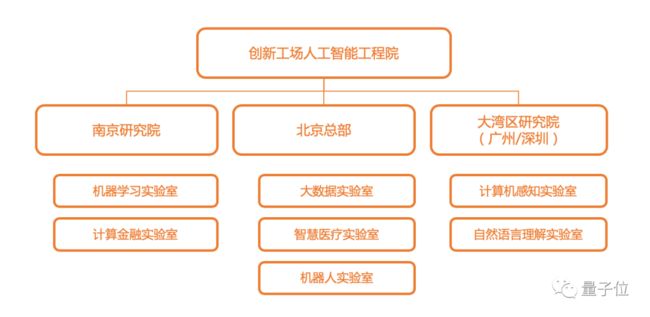
目标是培养人工智能高端科研与工程人才,研发以机器学习为核心的前沿人工智能技术,并同各行业领域相结合,为行业场景提供一流的产品和解决方案。
所以怎么说呢?在新技术周期时代,创新工场可能是全世界最硬核、最愿意为技术研发投入的投资机构了。
此次开源的中文预训练模型ZEN,就是一个更好的开始。
对于学术科研领域来说,有钱有心的投资机构们愿意参与推动这样的技术进步,再好不过啦。
传送门
ZEN开源地址:
https://github.com/sinovation/zen
论文地址:
http://arxiv.org/abs/1911.00720
— 完 —
大咖齐聚!量子位MEET大会报名开启
量子位 MEET 2020 智能未来大会启幕,将携手优秀AI企业、杰出科研人员呈现一场高质量行业峰会!VIP票即将售罄,快扫码报名吧~

榜单征集!三大奖项,锁定AI Top玩家
2019中国人工智能年度评选启幕,将评选领航企业、商业突破人物、最具创新力产品3大奖项,并于MEET 2020大会揭榜,欢迎优秀的AI公司扫码报名!


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !