2019年CS224N课程笔记-Lecture 2: Word Vectors and Word Senses
资源链接:https://www.bilibili.com/video/BV1r4411f7td?p=1(中英文字母版)
word2vec的复习
其实没什么内容就是将上节课说的复习了一遍,不过最后又添加了一下新内容,如下:word2vec是根据语义进行训练的,相同语义的词在空间上是比较靠近的,而且能很好的表示类比关系,例如:国王-男人+女人=王后/皇后;相对于瓶子和盖子的关系,类比暖壶,可能输出壶塞。
上节课也说了,word2vec的计算是很大的。一种方法是使用SGD/随机梯度下降方法,对于θ(超参数列表)来说,每次更新的只有极少数参数
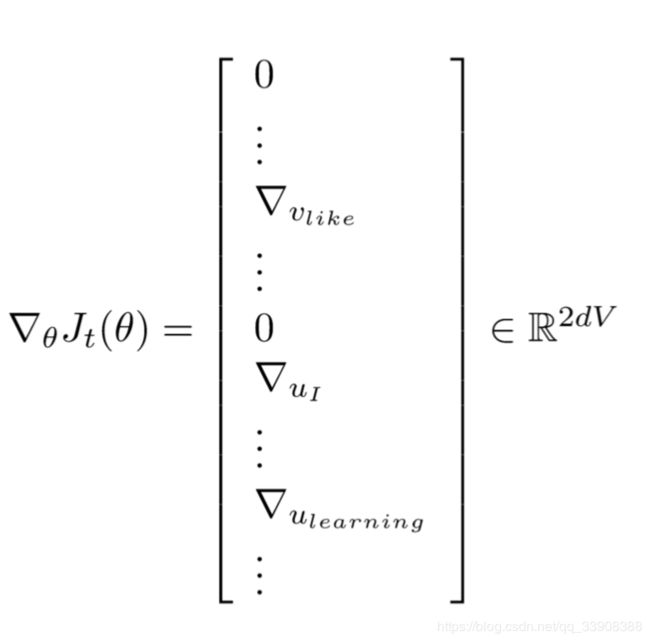 (该矩阵中大量元素为0,如果做矩阵减法,很多元素-0,大量浪费时间)
(该矩阵中大量元素为0,如果做矩阵减法,很多元素-0,大量浪费时间)
解决方法:去矩阵中的需要更新的值进行更新,而不是直接矩阵减法
正课内容
近似算法-负采样
为什么word2vec会消耗大量时间呢?
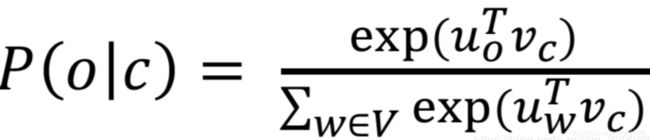
归根结底就是上述公式的分母和整个语料库有关/呈线性关系,所以计算量超级大
负采样思想:
1、为对中心词向量和外围词向量的点乘进行sigmoid计算,把softmax变成sigmoid。
2、选取了K个负样本,负样本为窗口之外的样本。对于窗口中的每个词u,计算uo*vc的sigmoid,计算负样本和中心词的点乘uj*vc,求sigmoid。最大化uo*vc,最小化uj*vc,得出目标函数如下所示。
其实如果没接触过的话,这个地方会非常蒙的(下面放一段李沫老师的动手学深度学习nlp部分的一些内容)


可以看出来,课程中的公式是经过需要推导才过来的,因为省略了太多导致很不容易让别人理解。
(层序softmax没讲,大家有兴趣可以看看李沫老师的课~)
共现矩阵
(这一部分我不是很理解,可能之前学其他课程的时候也没怎么接触过这个概念)
共现矩阵的例子如下:(其中窗口大小设置为1)
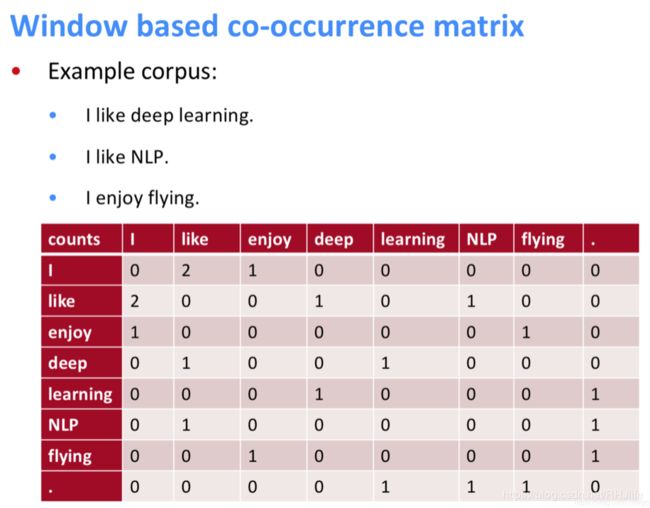
共现矩阵存在的问题:
- 随着语料库的大小的增大,向量的大小会增长
- 非常高维,需要大量的存储空间
- 子序列分类问题模型有非常稀疏的问题
- 模型可能不健壮
解决方案:
采用奇异值分解的方法,把所有信息量都浓缩在一个小的维度向量中。(将原矩阵转化为低维度矩阵)
(该方法我不会。。。就不详细介绍了)
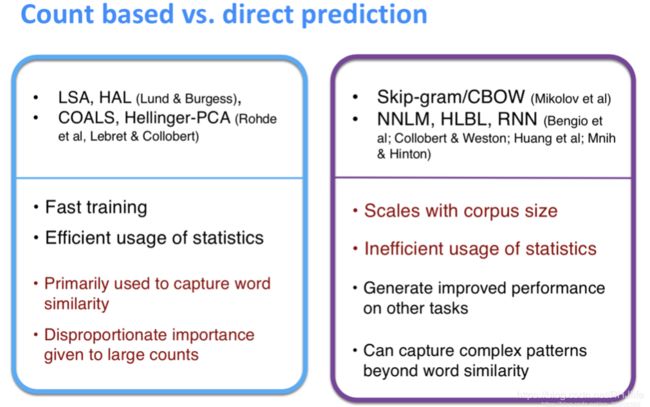
基于计数的模型和根据文本语义预测的模型比较:
计数模型:(例如即将要说的GloVe)
- 训练速度快
- 有效的利用数据
- 主要用来获取单词的相似度
- 对于出现次数多的单词基于重视
语义预测:(例如Word2Vec)
- 与语料库大小有关
- 数据使用不高效
- 提高其他任务的性能
- 能捕捉到复杂的语义模式
(这一部分其实也比较难懂,如果不理解,我后面会放李沫老师课程中的介绍,大家相互结合着看吧)
共现概率的比值可以体现出单词之间的类比关系的是否接近(举例说明就是,冰ice和固体soild与蒸汽steam和固体soild比较,因为是8.9所以说明,前者关系更大,也就是冰与蒸汽相比,冰与固体关系更大,或者说越接近)
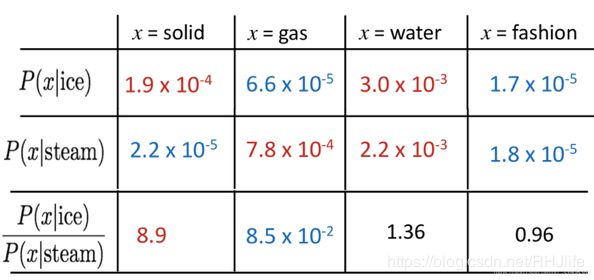
共现概率的比率

glove模型

(李沫老师的内容)



(在glove中,中心词和背景词是等价的,因为是对称矩阵嘛,但是实际中训练过程可能有一点点小微差别,因为随机初始化参数造成的影响,所以最终的选择还是求和/求平均)
后续内容
说一些glove的各种优势,这里就不总结了,大家理性看待就行
还有一些后续内容不是很理解,看其他人的笔记有说是:如何评估一个词向量的
那就根据别人的笔记和自己了解的一些整理一些吧
评估一个词向量?
从内在方面和外在方面两个方面说(我也不是很了解。。)
内在方面
在一个特殊的子任务上评估结果(使用该词向量,看看效果咋样,例如用某词向量生成文章、古诗很符合我们的认知,那么肯定很不错~)
能够让模型更快的训练(也就是词向量维度等少一点,例如one-hot和分布式词向量,明显后者更快)
帮助理解其他系统(不了解含义)
除非与实际任务建立了相关性,否则不清楚是否真的有用(不了解含义)
外在方面
在一个真正的任务上评估(不了解含义)
可能会花很长一段时间计算准确度(不了解含义)
不清楚子系统是问题所在,还是它的交互作用,还是其他子系统(不了解含义)
如果用另一个子系统替换一个子系统可以提高精确度——>获胜!(类似用A词向量生成的古诗狗屁不通,用B后胜似李白,那肯定B>A)
内在词向量评估
词向量类比:使用余弦cos计算两个词向量的相似度。(其实就是相似词,在空间中接近)

如果相同的单词有不同的含义,怎么办?
答案:使用加权求不同含义的和。
比如pike这个单词,不同场景下有多个不同的含义,计算公式如下图所示。其中f为权重。(为什么f为权重呢,因为虽然不同单词有不同语义,但是不同的语义的权重是不一样的,例如jack,大部分是名字,少部分是抢劫~)

外在单词向量评估
该类中的后续任务。
一个例子:命名体识别:识别出名字,组织和位置等。词向量表示的好效果就好。