python学习笔记(requests模块)
爬取页面内容
import requests
from urllib.error import HTTPError
def get_content(url):
try:
response = requests.get(url)
print(response.text)
print(type(response.text))
response.raise_for_status() # 如果状态码不是200, 引发HttpError异常
# 从内容分析出响应内容的编码格式
response.encoding = response.apparent_encoding
except HTTPError as e:
print(e)
else:
print(response.status_code)
# print(response.headers)
return response.text
if __name__ == '__main__':
url = 'http://www.baidu.com'
get_content(url)
向服务器提交数据
Http常见请求方法:
GET:从指定的资源请求数据。
post:向指定的资源提交要被处理的数据。

get方法
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
response = requests.get('http://www.baidu.com')
print(response.text)

url = 'https://movie.douban.com/subject/4864908/comments'
data = {
'start':20,
'limit':40,
'sort':'new_score',
'status': 'P'
}
response = requests.get(url, params=data)
print(response.text)
print(response.url)
post方法
- POST 请求不会被缓存
- POST 请求不会保留在浏览器历史记录中
- POST 不能被收藏为书签
- POST 请求对数据长度没有要求
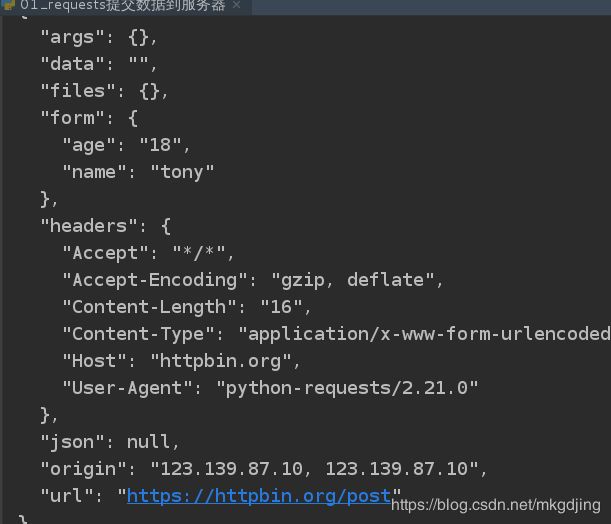
response = requests.post('http://httpbin.org/post',
data={'name':'tony', 'age':18})
print(response.text)
delete方法
response = requests.delete('http://httpbin.org/delete', data={'name':'tony'})
print(response.text)

百度、360搜索的关键字提交
import requests
def keyword_post(url, data):
try:
user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36"
response = requests.get(url, params=data, headers={'User-Agent': user_agent})
response.raise_for_status() # 如果返回的状态码不是200, 则抛出异常;
response.encoding = response.apparent_encoding # 判断网页的编码格式, 便于respons.text知道如何解码;
except Exception as e:
print("爬取错误")
else:
print(response.url)
print("爬取成功!")
return response.content
def baidu():
url = "https://www.baidu.com"
keyword = input("请输入搜索的关键字:")
# wd是百度需要
data = {
'wd': keyword
}
keyword_post(url, data)
def search360():
url = "https://www.so.com/s"
keyword = input("请输入搜索的关键字:")
# q是360需要
data = {
'q': keyword
}
content = keyword_post(url, data)
with open('360.html', 'wb') as f:
f.write(content)
if __name__ == '__main__':
search360()

上传登录信息
import requests
# 1). 上传数据;
url = 'http://bbs.chinaunix.net/member.php?mod=logging&action=login&loginsubmit=yes&loginhash=La2A2'
postData = {
'username': 'xxx',
'password': '12345678'
}
response = requests.post(url, data=postData)
# 2). 将获取的页面写入文件, 用于检测是否爬取成功;
with open('doc/chinaunix.html', 'wb') as f:
f.write(response.content)
# 3). 查看网站的cookie信息
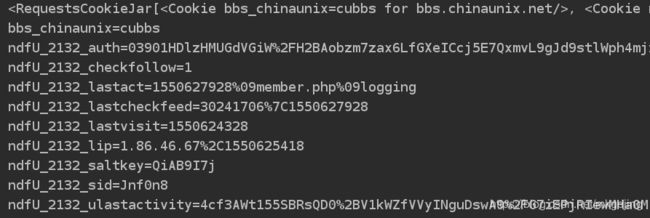
print(response.cookies)
for key, value in response.cookies.items():
print(key + '=' + value)
解析json格式数据
import requests
# 解析json格式
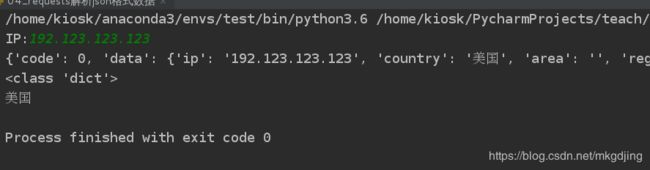
ip = input('IP:')
url = "http://ip.taobao.com/service/getIpInfo.php"
data = {
'ip': ip
}
response = requests.get(url, params=data)
# 将响应的json数据编码为python可以识别的数据类型;
content = response.json()
print(content)
print(type(content))
country = content['data']['country']
print(country)
获取二进制数据
下载图片或视频
import requests
def get_content(url):
try:
user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36"
response = requests.get(url, headers={'User-Agent': user_agent})
# print('a')
response.raise_for_status() # 如果返回的状态码不是200, 则抛出异常;
response.encoding = response.apparent_encoding # 判断网页的编码格式, 便于respons.text知道如何解码;
except Exception as e:
print("爬取错误")
else:
# print(response.url)
print("爬取成功!")
return response.content # 下载视频需要的是bytes类型
# return response.text #文本类型
if __name__ == '__main__':
url = 'https://gss0.bdstatic.com/-4o3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign=4f7bf38ac3fc1e17fdbf8b3772ab913e/d4628535e5dde7119c3d076aabefce1b9c1661ba.jpg'
# url = "http://gslb.miaopai.com/stream/sJvqGN6gdTP-sWKjALzuItr7mWMiva-zduKwuw__.mp4"
movie_content = get_content(url)
print("正在下载....")
with open('doc/movie.jpg', 'wb') as f:
f.write(movie_content)
print("下载完成.....")

requests的常见使用
上传文件,指定文件内容
data = {
'name':'fentiao'
}
files = {
# 二进制文件需要指定rb
'file': open('doc/movie.jpg', 'rb')
}
response = requests.post(url='http://httpbin.org/post', data = data, files=files)
print(response.text)

设置代理
proxy = {
'http':'183.148.158.164:9999',
# 'https':'110.52.235.228:9999'
}
response = requests.get('http://httpbin.org/get', proxies=proxy,timeout=3)
print(response.text)
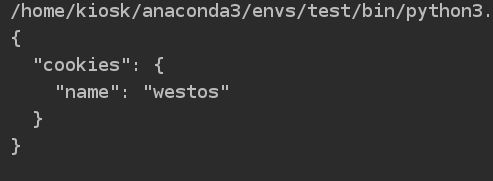
cookie信息保存
# 3). cookie信息的保存, 加载====== 客户端的缓存, 保持客户端和服务端连接会话seesion
seesionObj = requests.session()
# 专门用来设置cookie信息的,
response1 = seesionObj.get('http://httpbin.org/cookies/set/name/westos')
# 专门用来查看cookie信息的网址
response2 = seesionObj.get('http://httpbin.org/cookies')
print(response2.text)