机器学习概论
机器学习基础-每日目标
完成机器学习基础理论知识学习,
为推荐系统算法实践提供理论基础,为
成为一名算法工程师或推荐算法工程师
构建基础理论体系。
今日大纲
推荐系统-机器学习理论基础详解
1.大数据时代究竟改变了什么?(了解)
3.大数据项目架构-以电信日志分析为例(理解)
5.机器学习-人工智能概念区别和联系(掌握)
6.机器学习-数据、数据分析、数据挖掘区别和联系(掌握)
7.什么是机器学习(掌握)
2.大数据的4V特征(理解)
4.机器学习-人工智能发展(了解)
8.基于规则的学习和基于模型的学习(掌握)
9.机器学习关于数据集的概念(掌握)
11.机器学习经典案例举例-手写体识别(了解)
13.何设计机器学习系统(了解)
15.机器学习三要素数学理论补充(理解)
16.正则化(了解)
10.机器学习分类详解(理解)
12.机器学习三要素详解及概念强化(熟悉)
14.模型选择-泛化性能体现(掌握)
16.为什么先在是进入机器学习最佳时机(了解)
17.交叉验证(了解)
18.今日总结
第一部分-人工智能部分
• 人工智能引入性介绍
• 人工智能和机器学习区别
• 人工智能发展
• 数据分析、数据挖掘、机器学习区别
• 通过成熟案例了解实际应用
人工智能对未来生活的改变
10年后,⼈⼯智能将可能取代世界上90%的:
⼈⼯智能不是“模仿⼈类”,⽽通常是“远超⼈类”:
⼏年后,你能和这样的电脑竞争吗:
• 每天自我对弈100万盘棋,并从中学习的 AlphaGo?
• 每天从100万辆车实际⾏驶中吸收所有经验的 Tesla?
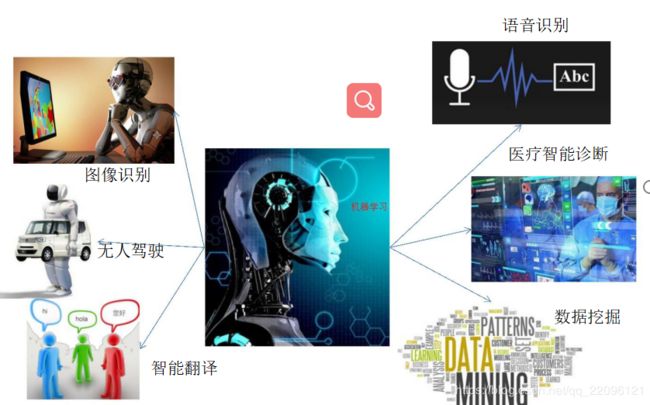
人工智能的热门方向
1.人工智能的三次浪潮
- 1956 Artificial Intelligence提出(61年)
- 1950-1970 符号主义流派:专家系统占主导地位
• 1950:图灵设计国际象棋程序
• 1962:IBM 的跳棋程序战胜人类高手(人工智能第一次浪潮) - 1980-2000统计主义流派:主要用统计模型解决问题
• Vapnik 1993 SVM模型
• 1997:IBM 深蓝战胜象棋选手卡斯帕罗夫(人工智能第二次浪潮) - 2010-至今神经网络、深度学习、大数据流派
• Hinton 2006 DNN(深度神经网络)
• 2016:Google AlphaGO 战胜围棋选手李世石(人工智能第三次浪潮)
天啊,人类要毁灭了…

国家层面人工智能领域建设
2017年7月20日国务院印发
《新一代人工智能发展规划》
- 到2020年,人工智能总体技术和应用与世界先进水平同步
- 第二步到2025年,人工智能理论基础实现重大突破、技术与应用部分达到
世界领先水平 - 第三步到2030年,人工智能理论、技术与应用总体达到世界领先水平
- 人才的培养是关键
回顾与总结
• 人工智能对未来生活的改变
• AlphaGo为什么这么厉害?是因为它自己与自己下了很多棋
• 人脸识别为什么那么厉害?是因为他们看了上亿张脸,然后从中学习
• 机器学习在任何狭隘领域,看到大量的数据,是人脑完全不能和它竞争的
• 人工智能发展
• 跳棋、国际象棋、围棋分别战胜人类高手
• 如今的人工智能深入到了生活的每个角落
2.人工智能、机器学习、深度学习的关系
• 机器学习是人工智能的一个分支,深度学习是实现机器学习的一种技术。
数据分析、数据挖掘和机器学习的关系
• 数据:即观测值,如测量数据
• 信息:可信的数据。
• 数据分析:从数据到信息的整理、筛选和加工过程
• 数据挖掘:对信息进行价值化的分析
• 用机器学习的方法进行数据挖掘。机器学习是一种方法;数据挖掘
是一件事情;还有一个相似的概念就是模式识别,这也是一件事情。
而现在流行的深度学习技术只是机器学习的一种;
各技术交叉点
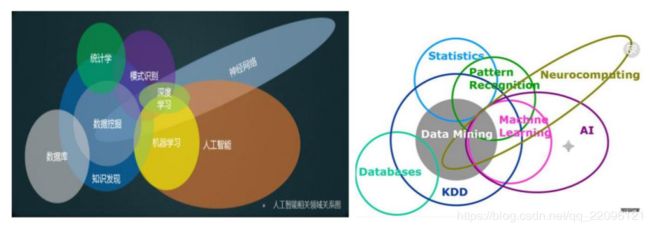
机器学习和模式识别都是达到人工智能目标的手段之一;
对数据挖掘而言,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。
第二部分-了解机器学习概念
• 什么是机器学习
• 什么不是机器学习
• 基于规则的学习
• 基于模型的学习
• 机器学习的各种概念剖析
• 机器学习的分类
3.什么是机器学习?
- 机器学习,它正是这样一门学科,它致力于研究如何通
过计算(CPU和GPU计算)的手段,利用经验来改善
(计算机)系统自身的性能。 - 它是人工智能的核心,是使计算机具有智能的根本途径,应用遍及人工智能各领域。
- 机器学习所研究的主要内容就是
关于在计算机上从数据中产生“模型(model)”算法(学习算法)
数据+机器学习算法=机器学习模型 - 有了学习算法我们就可以把经验数据提供给它,它就能基于这些数据产生模型。
- 面对新的情况(没有切开的西瓜),模型会提供相应的判断(好西瓜or坏西瓜)
什么不是机器学习?
• 机器学习:从已有的经验中学习经验,从经验中去分析
• (1)计算每种颜色箱子的个数?----确定的问题
• (2)计算一组数据平均值大小?----数值计算问题
• 机器学习的目的是建立预测模型–看是否有预测的过程
• (1)确定收到的邮件是否为垃圾邮件?
• (2)获取2014年世界杯冠军的名字?2018年?
• (3)自动标记你在Facebook中的照片
• (4)选择统计课程中成绩最高的学生(不是)
• 机器学习的目的是建立预测模型–看是否有预测的过程
• (5)考虑购物习惯,推荐相关商品?
• (6)根据病人状况确定属于什么疾病?
• (7)预测2018年人民币汇率涨or不涨?
• (8)计算公司员工的平均工资?
基于规则的学习
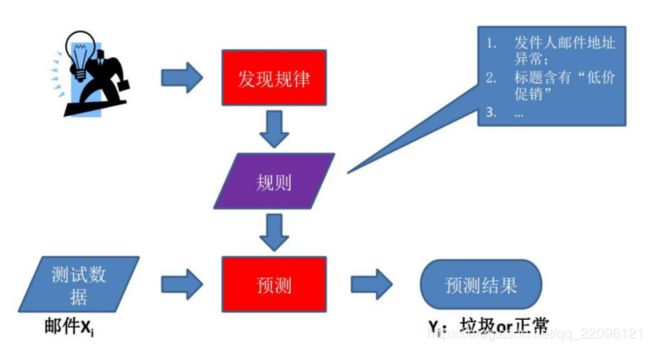
基于模型学习—机器学习

再论房价预测
假设有一个房屋销售的数据如下: 我们可以画一个图,x轴是房屋的面积。
y轴是房屋的售价:
面积(m
123
150
87
2
) 销售价钱(万元)
250
320
160
220
…
102
…
再论房价预测

我们可以使用一条直线尽可能多的
通过这些点,不通过的点尽量分布在直
线的两侧,利用这条直线所表示的线性
关系,我们就可以预测房价。
直线可以写成y=ax+b,若a,b已知,
我们就能够预测房价。机器学习中a,b称
为参数,y=ax+b称为模型。通常 a,b未
知,是我们需要求解的量。
4.机器学习各个概念理解
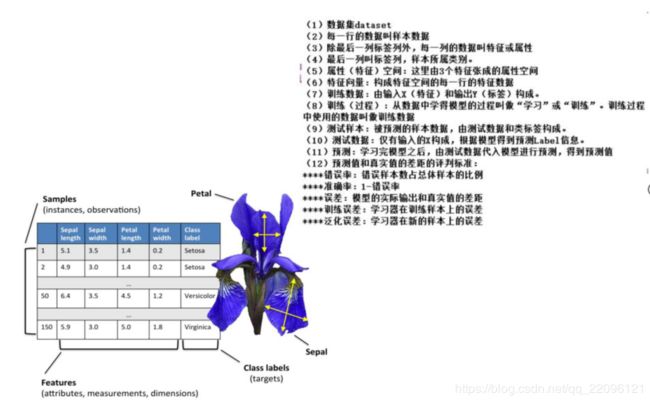
5.机器学习基本概念
-
基本概念:训练集,测试集,特征值,监督学习,非监督学习,半监督学习,分类,回归
-
概念学习:人类学习概念(如婴儿):鸟,狗;车,房子;黑匣子和计算机(怎么认识和区分?) 定义:概念学习是指从有关某个布尔函数(是或否)的输入输出训练样例中推断出该布尔函数 ?看下面例子
-
例子:学习 “享受运动" 这一概念:
小明进行水上运动,是否享受运动取决于很多因素
从第1天到第4天的各种因素决定小明是否享受运动
决定小明是否享受运动的因素?

概念学习:
- 概念定义在实例(instance)集合之上,这个集合表示为X。(X:
所有可能的日子,每个日子的值由 天气,温度,湿度,风力,水温,
预报6个属性表示。 - 待学习的概念或目标函数成为目标概念(target concept), 记做
c。(概念学习的过程求解c(x)过程)
c(x) = 1, 当享受运动时; c(x) = 0 当不享受运动时,c(x)也可叫
做y.
x: 每一个实例(每一行数据6个属性的值)
X: 样例, 所有实例的集合
学习目标:f: X -> Y
几个重要概念理解
-
训练集(training set/data)/训练样例(training examples): 用来进行训练,也就是产生模型或者算法的数据集
-
测试集(testing set/data)/测试样例 (testing examples):(通
常只知道特征,用来进行预测)用来专门进行测试已经学习好的模
型或者算法的数据集 -
特征向量(features/feature vector):属性的集合,通常用一个向量来表示,附属于一个实例
-
标记(label): c(x), 实例类别的标记
-
正例(positive example)
-
反例(negative example)
又是房价的举例…
• 例子:研究国内房价
影响房价的两个重要因素:面积(平方米),学区(评分1-10)

该数据集和小明享受水上运动的方式有什么区别呢?
对!!房价是连续型的数值
引出分类和回归问题
• 分类 (classification):
• 目标标记为类别型数据(category)
• 回归(regression):
• 目标标记为连续性数值 (continuous numeric value)
初识机器学习分类
• 例子:研究肿瘤良性,恶性于尺寸,颜色的关系
• 特征值:肿瘤尺寸,颜色
• 标记:良性/恶性
• 有监督学习(supervised learning): 训练集有类别标记(class label)
• 无监督学习(unsupervised learning): 无类别标记(class label)
• 半监督学习(semi-supervised learning):有类别标记的训练集 + 无
• 标记的训练集
初识机器学习步骤框架
• 机器学习步骤框架
1.把数据拆分为训练集和测试集
2.用训练集和训练集的特征向量来训练算法
3.用学习来的算法运用在测试集上来评估算法 (可能要设计到调
整参数(parameter tuning)–(验证集(validation set))
按照小明享受运动来理解:
- 100 天: 训练集
- 10天:测试集 (不知道是否 ” 享受运动“, 知道6个属性,来预测每一天是否享受运动)
第三部分-机器学习分类
• 机器学习分类详解
• 机器学习案例分析
机器学习分类
• 监督学习
• 非监督学习
• 半监督学习
• 强化学习
• 迁移学习
• 深度强化迁移学习
监督学习
- 监督(supervised)是指训练数据集中的每个样本均有一个已知的
- 输出项(类标label)。
- 输出变量为连续变量的预测问题称为回归(regression)问题(西瓜的成熟度)。
- 输出变量为有限个离散变量的预测问题称为分类问题(西瓜的分类)。
学习算法分类
Tip:你是见or不见?
分类算法:
决策树
KNN
SVM
Perception&&NeuralNetwork
Bayes
LogisticRegression
回归算法:
简单线性回归
多元线性回归
Lasso回归
Ridge回归
ElasticNet
案例:垃圾邮件的分类问题
基于有类标的电子邮件样本库,可以使用监督学习算法训练生成一个判定模型,
用来判别一封新的电子邮件是否为垃圾邮件;
1.30个训练样本,15个正样本,15个负样本
2.每个样本都有两个与其相关的值:x1和x2
3.图中的一条黑色的虚线将两类样本分开
4.可以根据值将新样本划分到某个类别中
(观察在直线的那一侧)

非监督学习(unsupervised learning)
• 人们给机器一大堆没有分类标记的数据,让机器可以对数据分类、
检测异常等。
1.聚类(KMeans)

2.降维(PCA,LDA)

半监督学习
半监督学习就是提供了一条利用“廉价”的未标记样本的途径。
强化学习
• 是机器学习的一个重要分支,主要用来解决连续决策的问题。
• 围棋可以归纳为一个强化学习问题,需要学习在各种局势下如何走
出最好的招法。

迁移学习
• 迁移学习能解决那些问题?
小数据的问题。比方说新开一个网店,卖一种新的糕点,没有任何的数据,就无法建立模型对用
户进行推荐。但用户买一个东西会反映到用户可能还会买另外一个东西,所以如果知道用户在另
外一个领域,比方说卖饮料,已经有了很多很多的数据,利用这些数据建一个模型,结合用户买
饮料的习惯和买糕点的习惯的关联,就可以把饮料的推荐模型给成功地迁移到糕点的领域,这样,
在数据不多的情况下可以成功推荐一些用户可能喜欢的糕点。这个例子就说明,有两个领域,一
个领域已经有很多的数据,能成功地建一个模型,有一个领域数据不多,但是和前面那个领域是
关联的,就可以把那个模型给迁移过来。
个性化的问题。比如每个人都希望自己的手机能够记住一些习惯,这样不用每次都去设定它,怎
么才能让手机记住这一点呢?其实可以通过迁移学习把一个通用的用户使用手机的模型迁移到个
性化的数据上面。
总结和回顾
机器学习第二天部分
• 机器学习经典案例举例
• 如何设计机器学习系统?
• 模型选择问题
• 其他
机器学习经典案例举例

灰度化和二值化
转化为11024
二值图片向量
学习算法
处理,如SVM
识别结果
3232矩阵
车牌、验证码识别的普通方法为:
(1)将图片灰度化与二值化。
(2)去噪,然后切割成一个一个的字符。
(3)提取每一个字符的特征,生成特征矢量或特征矩阵。
(4)分类与学习。将特征矢量或特征矩阵与样本库进行比对,挑选出相似的那类样本,
将这类样本的值作为输出结果。

机器学习三要素

模型—寻找规律

策略–模型好不好


算法

6.如何构建机器学习系统?

当面临这么多的模型需要选择,我们如何选择适合问题的模型呢?
首先看看数据

哪条曲线拟合效果是最好的?----模型选择

泛化
防火防盗放过拟合
• 模型具有好的泛化能力指的是:模型不但在训练数据集上表现的效
果很好,对于新数据的适应能力也有很好的效果。
• 泛化能力的表现:过拟合和欠拟合
• 过拟合overfitting:模型在训练数据上表现良好,在未知数据或者测试
集上表现差。
• 欠拟合underfitting:在训练数据和未知数据上表现都很差。
欠拟合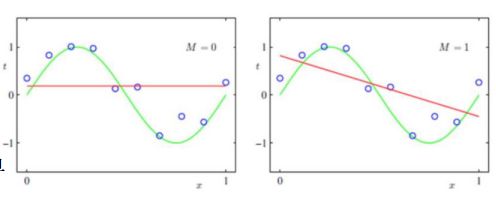
• 产生的原因:模型过于简单
• 出现的场景:欠拟合一般出现在机器学习模型刚刚训练的时候,也
就是说一开始我们的模型往往是欠拟合也正是因为如此才有了优化
的空间,我们通过不断优化调整算法来使得模型的表达能力更强。
• 解决办法:(1)添加其他特征项:因为特征项不够而导致欠拟合,
可以添加其他特征项来很好的解决。
• (2)添加多项式特征:可以在线性模型中通过添加二次或三次项使
得模型的泛化能力更强。
• (3)减少正则化参数,正则化的目的是用来防止过拟合的,但是现
在模型出现了欠拟合,需要减少正则化参数。
过拟合

• 产生的原因:可能是模型太过于复杂、数据不纯、训练数据太少等
造成。
• 出现的场景:当模型优化到一定程度,就会出现过拟合的情况。
• 解决办法:(1)重新清洗数据
• (2)增大训练的数据量
• (3)采用正则化方法对参数施加惩罚:常用的有L1正则和L2正则
• (4)采用dropout方法,即采用随机采样的方法训练模型,常用于
神经网络算法中。
•
•
注:使用复杂的卷积神经网络训练图像数据时尤其有效,
Dropout思路是:在训练时,将神经网络某一层的输出节点数据随机丢失一部分。
模型选择的----奥卡姆剃刀原则
• 给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型
更可取。
• 奥卡姆剃刀原则是模型选择的基本而且重要的原则。
机器学习三要素补充
• 机器学习三要素数学理论补充
策略

经验风险

经验风险最小化

结构风险

结构风险最小化

模型评估和模型选择
• 当损失函数给定时,基于损失函数的模型的训练误差和模型的测试
误差就自然成为学习方法评估的标准。

过拟合与模型选择

过拟合与模型选择
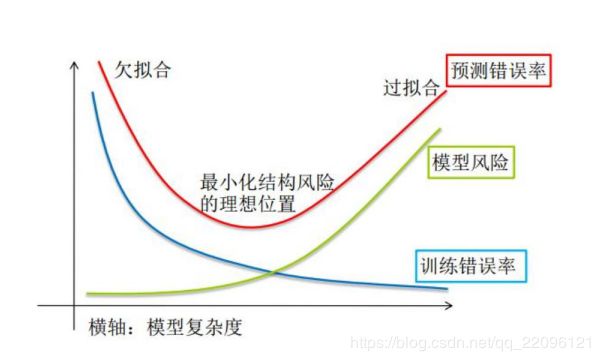
什么是正则化?

正则化

什么是交叉验证?

简单交叉验证
简单交叉验证的方法是这样的,随机从最初的样本中选择部分,形成验
证数据,而剩下的当作训练数据。一般来说,少于三分之一的数据被选作验证
数据。
10折交叉验证
10折交叉验证是把样本数据分成10份,轮流将其中9份做训练数据,
将剩下的1份当测试数据,10次结果的均值作为对算法精度的估计,通
常情况下为了提高精度,还需要做多次10折交叉验证。
更进一步,还有K折交叉验证,10折交叉验证是它的特殊情况。K
折交叉验证就是把样本分为K份,其中K-1份用来做训练建立模型,留剩
下的一份来验证,交叉验证重复K次,每个子样本验证一次。
留一验证
留一验证只使用样本数据中的一项当作验证数据,而剩下的全作为
训练数据,一直重复,直到所有的样本都作验证数据一次。可以看出留
一验证实际上就是K折交叉验证,只不过这里的K有点特殊,K为样本数
据个数。
7.为什么现在是进入机器学习的最佳时机?
• 借助于近些年发展起来诸多强大的开源库,我们现在是进入机器学
习领域的最佳时机。不用像前些年那样需要自己使用编程语言一步
一步实现机器学习算法,而是使用成熟的机器学习库帮我完成做好
的算法,我们只需要了解清楚各个模型的参数如何调整就能够将模
型应用于实际的业务场景。
Scikit-learn
- 简单高效的数据挖掘和数据分析工具
- 可供大家使用,可在各种环境中重复使用
- 建立在NumPy,SciPy和matplotlib上
- 开源,可商业使用-获取BSD许可证

Scikit-learn算法选择

SparkMLLIB
• MLlib是Spark机器学习库
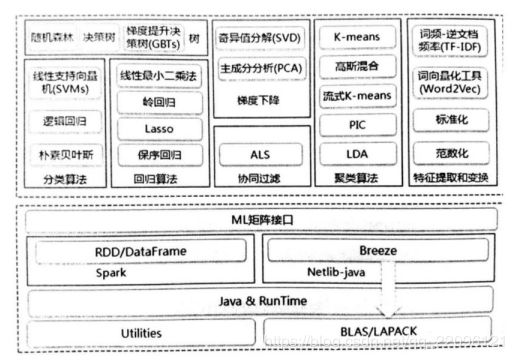
R与SparkR

Weka
• WEKA的全名是怀卡托智能分析环境(Waikato Environment for
Knowledge Analysis),同时weka也是新西兰的一种鸟名,而
WEKA的主要开发者来自新西兰。
• WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据
挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、
聚类、关联规则以及在新的交互式界面上的可视化。
• 如果想自己实现数据挖掘算法的话,可以看一看weka的接口文档。
在weka中集成自己的算法甚至借鉴它的方法自己实现可视化工具并
不是件很困难的事情。
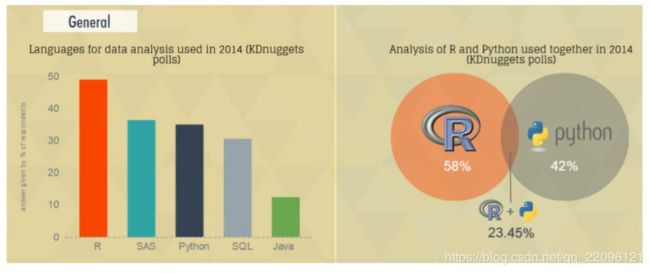
8.关于R和Python之争?
9.总结与回顾:
