2019-11-29-learnForp2p
About Ethereum p2p
p2p通信协议族的结构设计

分为三层结构:
- 1.第一层,pkg eth中:eth.peer代表了远端通信对象和其所有的通信操作,它封装了更底层的p2p.Peer对象以及读写通道。eth.peerSet:是peer的集合类型。被eth.Ethereum,eth.ProtocolManager等顶层管理模块使用。
- 2.第二层,pkg p2p中,可认为是泛化的p2p通信结构。p2p.Peer{}代表远端通信对象,封装自更底层的连接对象的conn{},通信用通信用的通道对象protoRW{},以及启动监听、处理新加入连接或断开连接的p2p.Server{}。p2p.Protocol{},针对上层应用特意开辟的类型,主要作用是包括容纳上层应用程序所要求的回调函数等,并通过p2p.Server{}在新连接建立后,将其产地给通信对象peer。
- 第三层,是golang自带的网络代码包,分为两部分:1.pkg net,包括代表网络连接的接口,代表网络地址的以及他们的实现类,2.pkg syscall,包括更底层的网络相关系统调用类等,可视为封装了网络层(IP)和传输层(TCP)协议的系统实现。
从逻辑应用分类的角度也可以分成三层:
1.基于udp的邻居发现层;
基于udp的邻居发现层使用Kad (Kademlia p2p网络协议)节点发现机制,与网络中的其他节点进行ping pong握手、交换邻居的方式发现邻居,计算节点之间的距离,动态维护邻居表。
2.基于tcp的加密通信层;
基于tcp的加密通信层与节点发现层发现的节点进行握手建立安全加密连接,负责对核心层协议提供的数据进行编解码与加解密、安全传输,rlpx为该层实际使用的协议。
3.核心协议层。
核心协议层负责将需要发送的业务数据传入加密通信层,并处理从加密通信层收到的业务数据。
理论上,无论是tcp还是udp通信,只要知道了ip地址和端口号就可以进行通行了。为了找到通信对方的地址,可以从两种方式入手:1.初始连接(种子节点)2.地址传播发现(泛洪、分布式哈希表)。
c/s模式
c/s模式上,client通过server来获取服务,server上的服务也丰富多彩,但是弊病也是十分的明显,即中心化,可以说信息的安全全都在于server上。他的网络拓扑结构为:

理论上,无论是tcp还是udp通信,只要知道了ip地址和端口号就可以进行通行了。以聊天软件为例,一般来说,你是与server建立连接的,而不是直接和聊天对象建立连接的,所以其实你自己是不用知道对方的ip地址和端口号的,server知道就可以了,无论做什么都得经过server端。
区块链p2p网络分类:中心化p2p网络,全分布式非结构化 P2P 网络,全分布式结构化 P2P 网络,半分布式 P2P 网络。
根据网络拓扑结构,c/s很像p2p的中心化模型(网络拓扑图如下)
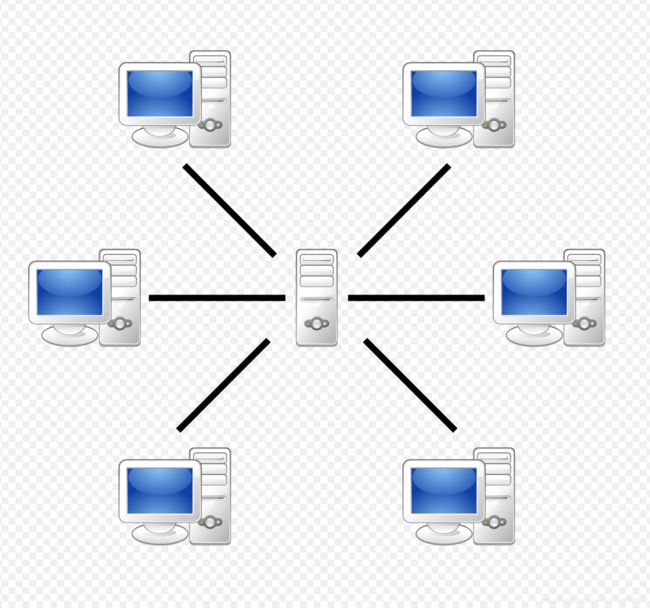
不同点在于,这里是peer to peer,即双方是对等的,双方即可以为对方提供服务也可以享受对方的服务,这里的p2p的中心服务器区别于c/s的中心服务器在于p2p中心服务器只提供索引,而传统server提供全服务。他的一个通讯过程是:中心服务器的ip和端口是已知的,新的节点加入网络,报告给中心服务器自己的ip和端口号,这样就可以被别的节点查询到了,进行p2p通信。
全分布式模型,其网络拓扑结构如下。这个模式是真正的去中心化,节点可以自由的加入和退出。但是这就涉及到一个问题,如何获取目标地址呢?通过初始连接——种子节点,通过地址传播发现:非结构式——泛洪,结构式——分布式哈希表的解决办法来获取对方地址。

先介绍全分布非结构式模型,比较成功的案例是gnutella产品,采用的是泛洪(flooding)技术实现发现其他节点和随机转发机制,采用TTL(time to live)的减值来实现控制消息通信有限次数传播。但是这个技术是在网络中的节点已经累积到一定的时候可以采用泛洪来暴力查找节点,那么网络刚开始建立起来的时候,新节点如何得知网络节点的信息呢?Gnutella也使用了目录服务器来方便寻找其他节点的地址。
全分布式非结构模型,采用种子节点,比特币中就采用了这种解决方案。这些节点在初 始启动时,提供最初接入网络的入口节点。新节点通过这些稳定节点作为中介连接其他节点,并且可以持续获取区块链网络 节点地址列表,所以这些节点也称之为种子节点。介入新节点后,就可以以这个节点为中介,获取网络其 他节点地址,这种方式被称为地址广播。a)主动广播(推)A 节点地址 比特币通过 Net. AdvertiseLocal( )方法,将自身节点信息推 送给其他节点。这是一个主动单向过程,B 节点 接收后只保存在本地,并不做回应。同样,B 节点与其他节点 间,也可以通过推送自身地址传递给其他连接的节点,通过推 的方式使得连接节点获得自身节点的地址信息。 b)主动获取(拉)其他节点地址 仅仅推送自身地址,只局限于自身连接的节点并不足以将 地址广播出去,比特币还有另外一种地址广播机制,通过 Net.GetAddresses( )方法主动拉取地址。A 节点请 求地址后获取 B 节点,B 节点返回 B 节点收录的地址信息。一 次请求一次响应,以避免对网络资源的浪费。B 节点也可以通 过向其他节点请求地址,以扩充自身地址库。3)地址数据库 为避免种子节点连接数及带宽限制,比特币节点接入网络 后通过广播获取其他节点信息,并将结果保存,以便下次使用 时接入网络。比特币客户端将获取的节点信息保存在 peers.dat 本地文件中,使用的是 levelDB 格式储存数据。

全分布式结构模型,这是为了解决非结构模型中,节点地址管理困难,节点间没有固定 规则约束,无法精确定位节点信息,只能通过洪泛查询方式进 行查找,对网络的消耗很大的问题。结构化网络采用分布式哈希表 (distributed Hash table, DHT),通过如 Hash 函数一类的加 密散列函数,将不同节点地址规范为标准长度数据。比较成功 的案例有 Chord 、Pastry等。网络结构同非结构化相同, 都是随机形式,无固定结构,但节点管理有固定结构图。以太坊将节点椭圆加密算法的公钥转换为 64 Byte 长度的 NodeID 作 为唯一标志符来区分节点,使得以太坊可以在没有中心服务器 的情况下实现节点地址精确查找。DHT 将 P2P 网络节点通过 Hash 算法散列为 标准长度数据,整个网络构成一个巨大的散列表。每个参与节 点都有一部分的散列表,并储存维护自身数据,散列表分布在 P2P 网络各个节点上。任何接入 P2P 网络的节点都有自身位于 散列表中位置的 ID,可以通过 DHT 寻找更多节点,也可以被其 他节点根据 ID 值精确查找。虽然 DHT 支持节点自由地加入或 退出,但 DHT 的复杂维护机制,使其无法适应高频的节点变 化。以太坊使用的是 Kadenlia协议。Kad 是 DHT 协议 的一种,使用该协议,可以快速准确地查找地址。
kad算法的介绍
与传统的 DHT 比较, Kad 有如下优点:
a)Kad 的查询请求是并行、异步的,可以避免节点退出或 故障导致的查询失败情况。
b)Kad 简化了节点间为了了解彼此而必须发送的配置消息 数量,并且在查找时自动交换配置信息。
c)Kad 采用二叉树节点分为多个 Kad 桶,简化查询结构。 使用单向性异或算法(XOR)计算距离,保证对同一个 TargetID 所有查询都会收敛到同一个路径,以减轻节点间查询网络消耗, 提升查询效率。
d)节点在记录其他节点是否可用时所采用的算法可以阻止 一些常见的拒绝服务(denial of service,DoS)攻击。
以太坊 Kad 与传统 Kad 相比,收敛方式不同。传统的 Kad 是以自身 selfID 作为收敛目标,而以太坊不仅以自身 selfID 为 收敛目标,还通过随机生成的 TargetID 作为收敛目标,以生成 较大范围的散列表。
如何实现地址的准确查询的呢?
NodeID=节点标志符(节点椭圆加密后的公钥长度/8)=64位长度数据,规范每个节点长度信息。
Nbuckets=Kad桶(common.hash{} * 8/15)=32 * 8/15=17个,节点自身维护路由表的数量,k桶越多,查找速度越快,消耗资源越多。
bucketMinDistance=common.hash{} * 8 - Nbuckets = 239,这是kad标准节点间的距离。
bucketsize=16,每个桶包含16个节点,每个路由表包含的节点数量越多,查找速度越快,耗费资源就越多
refreshInterval 刷新 timer=30 * time.Minute,设定刷新频率。
revalidateInterval 验证 timer = 10 * time.Second,设定验证 节点频率。
copyNodesInterval 持久化 timer = 30 * time.Second,设定 持久化频率。
kad算法是如何精确地找到目标节点的呢?
为每一个节点维护一个id,这个id就可以唯一标识该节点。有标志物后,如何查找。这个算法最要的一点就是使用了异或运算来得到他们之间的逻辑上的距离,targetID与selfID进行异或计算,得到的结果存在1所在的最高位是他们之间距离的一个量级,称为kad桶,这是异或的特性得到的,天然就是一个二叉树结构。因为从左往右,从高位到低位,最后一个相同的位异或的结果都为0,之后出现不同,结果肯定为1,之后可以出现分叉,要么是0要么是1,两种结果,所以天然为二叉树。


只要约定好,id号和“通讯记录”中排序是对应的,那么必然是可以找到的。定位到对应的bucket后,让距离这个targetID的点(你的“通讯录”中存在的)最近的帮助你寻找,也是采用相同的方式,若找到了则返回targetID的“联系方式”。采用这种定位方式,可以比较快的找到目标节点,最多只需要查询log2n次。
查询步骤:
(a)先在当前的桶里面用 closest( )方法查找,获得最近于目 标节点的临近节点。
(b)查找一遍之后没找到就在周边的节点中,使用 Lookup( ) 方法再搜索一遍。
©Lookup ( )会要求已知节点查找邻居节点,查找的邻居节点又递归的找它最近的 alpha(3)个节点 findnode()。
参考:
- 《区块链 P2P 网络协议演进过程 》
- https://keeganlee.me/post/blockchain/20180313/
- https://www.jianshu.com/p/f2c31e632f1d
- https://blog.csdn.net/teaspring/article/details/78455046