用正则表达式爬取猫眼电影TOP100排行榜
要求
爬取猫眼电影TOP100排行榜电影信息(排名/影片名称/上映时间/评分)
爬取过程
1.找出每一页url的变化规律是参数offset,写for循环
for i in range(2):
url = 'https://maoyan.com/board/4?offset={}'.format(i*10)
response = requests.get(url,headers).text
2.查看第一页源代码,找出需要爬取信息的位置,并找出规律
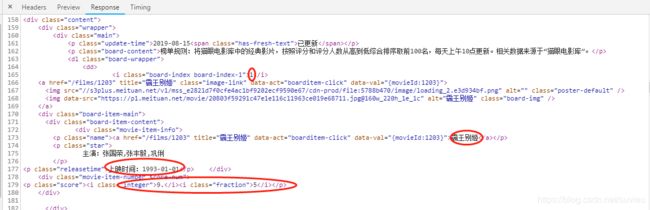
排名信息在
对应正则表达式为:
电影名称在class为name的a节点内,
对应正则表达式为.*?name">
上映时间在class为releasetime的p节点内
对应正则表达式为: .*?releasetime">(.*?)
评分在class为integer和fraction的p节点内
对应正则表达式为:.*?integer">(.*?).*?fraction">(.*?).*?
所以整段表达式为:
pattern = re.compile(r'.*?board-index.*?>(\d+).*?name">(.*?).*?releasetime">(.*?).*?integer">(.*?).*?fraction">(.*?).*? ',re.S)
items = re.findall(pattern,response)
3.这里的items 变量是一个列表,列表中的元素是十个元组(十部电影),每一个元组分别包含了最新一页中一部电影的信息(排名/名称/上映时间/评分);因为items在for循环里,所以每次循环都会被覆盖
![]()
再写一个代码,把每次循环后 得到的items里的元组放进一个列表中,
for item in items:
movie.append(item)
4.最后把movie列表用pandas导入,再导出为excel
title = ['RANK','NAME','RELEASE TIME','INTEGER','FRACTION']
movie_info=pd.DataFrame(movie,columns=title)
movie_info.to_excel('MAOYAN.xlsx')
附完整代码
import requests
import re
import pandas as pd
import time
movie = []
title = ['RANK','NAME','RELEASE TIME','INTEGER','FRACTION']
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Mobile Safari/537.36'}
for i in range(10):
url = 'https://maoyan.com/board/4?offset={}'.format(i*10)
response = requests.get(url,headers).text
pattern = re.compile(r'.*?board-index.*?>(\d+).*?data-src=".*?".*?name">(.*?).*?star">.*?.*?releasetime">(.*?).*?integer">(.*?).*?fraction">(.*?).*? ',re.S)
items = re.findall(pattern,response)
time.sleep(1)
for item in items:
movie.append(item)
movie_info=pd.DataFrame(movie,columns=title)
movie_info.to_excel('MAOYAN.xlsx')
疑问
1.正则表达式太长,如何换行?
待改进
1.如何用xpath解析?