GPU编程--OpenCL四大模型
本篇结构:
- 前言
- 平台模型
- 执行模型
- 内存模型
- 编程模型
- 参考资料
一、前言
“模型”是对现实世界的一个抽象,它对现实世界的进行简化,把不关心的,或者不影响所关注部分的内容,都从模型去掉。模型有助于理解它反映的那部分世界的规律。
OPenCL作为开放性的异构计算的标准,支持的平台有CPU、GPU、DSP、FPGA等。为了把各个厂家、各个平台的各种概念和术语都统一到一个标准的环境下,OpenCL定义了若干个模型。这对于OpenCL这种本来就定义在异构平台的标准尤其重要,通过这些模型,可以使用相同的语言/语义来描述不同环境下的并行计算。
OpenCL定义了平台模型(Platform Model)、执行模型(Execution Model)、内存模型(Memory Model)、编程模型(Programming Model)。
二、平台模型
不同厂商的OpenCL实施定义了不同的OpenCL平台,通过OpenCL平台,主机能够和OpenCL设备之间进行交互操作。
OpenCL使用了一种InstallableClient Driver模型,这样不同厂商的平台就能够在系统中共存(例如:在一个系统中可以既有AMD的平台和Intel的平台)。现在的OpenCL driver模型不允许不同厂商的GPU同时运行。
OpenCL平台需要包含一个主处理器和一个或多个OpenCL设备。平台模型定义了host和device的角色,并且为device提供了一种抽象的硬件模型。一个device可以被划分成一个或多个计算单元,这些计算单元在之后能被分成一个或多个“处理单元”(processing elements)。

host负责管理所有的OpenCL设备,宿主机发起计算任务,选择特定的OpenCL设备并建立计算环境,在AMD和Nvida的OpenCL平台中,一般都指x86 CPU。device主要负责数据运算操作,宿主机将计算任务和数据发送给OPenCL设备。设备调用内部计算单元进行计算,完成后将结果返还给宿主机,该次计算任务结束。
平台模型是应用开发的重点,其保证了OpenCL代码的可移植性(在具有OpenCL能力的系统间)。平台模型的API允许一个OpenCL应用能够适应和选择对应的平台和计算设备,从而在相应平台和设备上运行应用。
应用可以使用OpenCL运行时API,选择对应提供商提供的对应平台。不过,平台上能指定和互动的设备,也只限于供应商提供的那些设备。例如,如果选择了A公司的平台,那么就不能使用B公司的GPU。不过,平台硬件并不需要由供应商独家提供。例如,AMD和Intel的实现可以使用其他公司的x86 CPU作为设备。
编写OpenCL C代码时,设备架构会被抽象成平台模型。供应商只需要将抽象的架构映射到对应的物理硬件上即可。平台模型定义了具有一组计算单元的设备,且每个计算单元的功能都是独立的。计算单元也可以划分成更多个处理单元。举个例子,AMD Radeon R9 290X图形卡(device)包含44个向量处理器(计算单元)。每个计算单元都由4个16通道SIMD引擎,一共就有64个SIMD通道(处理单元)。Radeon R9 290X上每个SIMD通道都能处理一个标量指令。运行GPU设备能同时执行44x16x4=2816条指令。
三、执行模型
一个OpenCL应用由两个不同部分组成:一个宿主机程序(host program)以及一个或多个内核(kernel)组成的集合。宿主机程序在宿主机上运行,内核在OpenCL设备上执行,它们共同完成OpenCL应用的具体工作。
OpenCL是一个主从处理模型,根本是宿主机如何利用OpenCL设备上大量的计算资源进行有效计算。所以OpenCL执行模型的任务就是如何高效地调用这些计算资源。
- 宿主机将每一个处理单元(PE)分配一个索引号,这个唯一的索引号称为全局ID(Global ID),全体PE被看做一个工作空间的work-item。
- 因为可能需要处理数组、图形乃至三维图像,所以对应的工作空间也可以定义为一维、二维、三维。
- 为了更好的处理不同的数据,可以将工作空间进行粗粒度的划分,如将一部分ID划分到一组,这个组称为work-group,每一个组内也可以分配ID,不过这个ID称为局部ID(Local ID)。全局ID和局部ID存在映射关系。
- OpenCL规范中使用一个长度为N的整数数组来描述工作空间的大小(N<=3),称为NDRange。数组中的数值对应相应维度上工作点的个数。eg {2, 3}表示一个维度上工作项为2,另一个维度为3。
- 如果将我们常见的三维魔方想象成一个工作空间,那么一维即某种颜色(eg:红色)的一行,即一维个数为3,二维为相应的那个面,二维个数为9,三维即为整个工作空间,三维个数为27。
如果想更详细了解执行模型NDRange等相关内容,可以参看OpenCL编程指南,有详细的插图,讲解很细致。
3.1、上下文
计算工作主要在OpenCL设备上进行,但宿主机也扮演着非常重要的角色,内核就是在宿主机上定义的。宿主机主要通过上下文(Context)管理OpenCL设备,对内核的正确执行进行协调和内存管理。
那什么是上下文?
上下文是一个软硬件资源整合,它定义了一个环境,内核就在这个环境中定义和执行。由以下资源定义上下文:
- 设备:OpenCL程序调用的计算设备
- 内核:在计算设备上执行的并行程序
- 程序对象:内核程序的源代码(.cl文件)和可执行文件
- 内存对象:计算设备执行OpenCL程序所需的变量
上下文由宿主机使用API进行创建、管理、销毁。
3.2、命令队列
主机与OpenCL设备之间的交互是通过命令完成的,根据计算量的大小,计算设备并不能立刻执行完被分配的计算任务。那么宿主机只能等着计算设备把任务计算完了才能继续分配新的任务么?不是这样的,每一个计算设备都会有一个命令队列。命令队列只能管理一个计算设备。
命令队列由宿主机创建,并在定义上下文之后关联到一个OpenCL设备。宿主机将命令放入命令队列,然后调度这些命令在关联设备上执行。
OpenCL支持3种类型的命令:
- 内核执行命令(kernel execution command):在OpenCL设备的处理单元上执行内核。
- 内存命令(memory command):在宿主机与内存设备之间移动数据,或者在两者之间进行内存映射。
- 同步命令(synchronization command):对命令执行的顺序施加约束。
- 乱序执行: 命令按照在命令队列中的顺序进行发射,但不保证计算设备是按照这个顺序进行执行的。
- 有序执行: 命令按照在命令队列中的顺序进行发射和执行,上一条命令执行完成后才能发射下一条命令。
宿主机程序可以为一个计算设备创建多个命令队列—一个计算设备可以有多个命令队列。这些命令队列没有关联。这也就意味着一个计算设备可以执行多个种类的任务。
四、内存模型
一般而言,不同的平台之间有不同的存储系统。例如,CPU有高速缓存而GPU就没有。为了程序的可移植性,OpenCL定义了抽象的内存模型,程序实现的时候只需关注抽象的内存模型,具体向硬件上的映射由驱动来完成。
与通用计算程序的内存对象相似,OpenCL将设备中的存储器抽象成四层结构的存储模型:
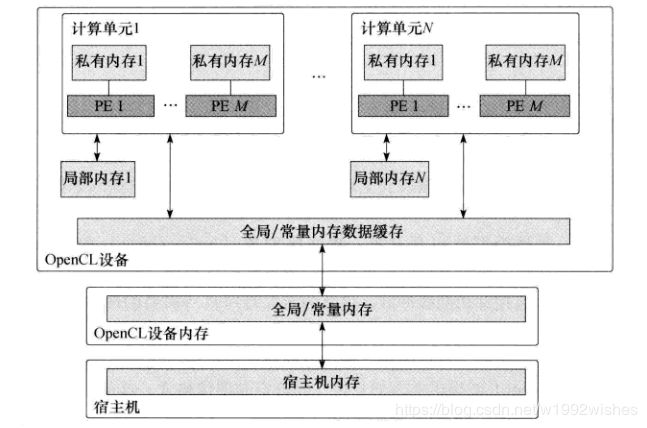
- 宿主机内存(host memory):这个内存区域只对宿主机可见。
- 全局内存(global memory):这个存储区域允许读、写所有工作组中的所有工作项。工作项可以读、写全局内存中一个内存对象的任何元素。读、写全局内存可能会缓存,这取决于设备的容量。
- 常量内存(constant memory):全局内存中的一块区域,在内核的执行过程中保持不变。宿主机负责对此中内存对象的分配和初始化。
- 局部内存(local memory):隶属于一个工作组的内存区域。它可以用来分配一些变量,这些变量由此工作组中的所有工作项共享。在OpenCL设备上,可能会将其实现成一块专有的内存区域,也可能将其映射到全局内存中。
- 私有内存(private memory):这个内存区域是一个工作项私有的区域。一个工作项私有内存中定义的变量对其他工作项不可见。
在程序运行期间,需要宿主机和计算设备进行数据交换,存在两种方式:
- 显式地复制数据:将需要的数据拷贝到工作组空间,计算完成后再拷贝出去(传形参)。
- 内存映射:将需要计算数据的地址传进去(传指针)。
五、编程模型
OpenCL执行模型定义了一个OpenCL应用如何映射到处理单元、内存区域和宿主机。这是一个“以硬件为中心”的模型。现在换个角度,介绍如何使用编程模型将并行算法映射到OpenCL。
OpenCL定义了两种不同的编程模型:任务并行和数据并行。
- 数据并行:将需要计算的数据进行等分,分配给不同的计算设备进行计算。如需要进行两个很大矩阵的求和运算,那么就可以将矩阵数据分成几份,那么理论上计算事件缩减为原来的1/N。这适用与数据想关联不大的计算任务。
- 任务并行:如计算数据量不大,但每一个步骤前后依赖,如你必须先将水烧开才能下面条,如果你需要不断的煮面条,那么就可以将这个过程分成阶段,用好几个锅同时进行。
六、参考资料
OpenCL 2.0 异构计算
OpenCL编程指南
http://coderdock.com/categories/OpenCL/