题目:Fully-Convolutional Siamese Networks for Object Tracking
来源:CVPR2016
论文主页(有matlab代码):http://www.robots.ox.ac.uk/~luca/siamese-fc.html
贡献:网络虽然很简单,但达到了实时性。
Siamese缺点:
1、因为Siamese属于模板匹配类的算法,对于突然变化和超出边界框(图像)的目标跟踪会失败哟
2、对于背景杂斑较多,即有太多相似性物体的时候,跟踪效果不好。
摘要:在进行目标跟踪时,往往是通过使用训练的视频集来学习一个物体的外观模型来实现的。尽管这些方法很成功,但他们这种只进行在线的方式所学到的模型丰富度不够。最近,为了提高学到的模型的丰富度,深度卷积网络进入了视线。然而,在跟踪的物体在先前是不太确定的时候,那就有必要在线使用随机梯度下降来调整网络的参数,当然了,系统的速度不是很好。
In this paper we equip a basic tracking algorithm with a novel fully-convolutional Siamese network trained end-to-end on the ILSVRC15 dataset for object detection in video.Our tracker operates at frame-rates beyond real-time and, despite its extreme simplicity, achieves state-of-the-art performance in multiple benchmarks.
1 Introduction
在进行单目标跟踪的时候,因为跟踪算法可能被要求跟踪任意的一个物体,所以拥有早已收集好的数据且训练一个专门的探测器几乎是不可能的。多年以来,最成功的方法基本上就是在线学习物体的外观模型,方法有TLD,Struck,KCF。然而,一个最大的缺陷就是所学习的模型太简单了。而使用deep conv-nets 的话,由于一些问题,使用上有困难。
这些问题有2个,训练数据集的稀缺和实时性的操作约束
当然了,有问题就有解决方法。为了解决这2个局限,有一些工作出现了。这些工作主要使用一个预训练deep conv-net,这个网络是为一种不同但是相关的工作而学习到的。工作有2种。
1、shallow methods
using the network’s internal representation as features,e.g. correlation filters
2、SGD
perform SGD (stochastic gradient descent) to fine-tune multiple layers of the network
二者各自的不足:
While the use of shallow methods does not take full advantage of the benefits of end-to-end learning, methods that apply SGD during tracking to achieve state-of-the-art results have not been able to operate in real-time.
那么,我们采取什么方法呢?
a deep conv-net is trained to address a more general similarity learning problem in an initial offline phase,and then this function is simply evaluated online during tracking.
本文的贡献点在于
The key contribution of this paper is to demonstrate that this approach achieves very competitive performance in modern tracking benchmarks at speeds that far exceed the frame-rate requirement.Specifically, we train a Siamese network to locate an exemplar image within a larger search image.
A further contribution is a novel Siamese architecture that is fully-convolutional with respect to the search image: dense and efficient sliding-window evaluation is achieved with a bilinear layer that computes the cross-correlation of its two inputs.
2 Deep similarity learning for tracking
用相似性学习的方法来跟踪任意的物体。
We propose to learn a function f (z, x) that compares an exemplar image z to a candidate image x of the same size and returns a high score if the two images depict the same object and a low score otherwise.To find the position of the object in a new image, we can then exhaustively test all possible locations and choose the candidate with the maximum similarity to the past appearance of the object. In experiments, we will simply use the initial appearance of the object as the exemplar. The function f will be learnt from a dataset of videos with labelled object trajectories.
我们用的function f就是deep conv-net。而用deep conv-nets进行相似学习往往可以通过使用Siamese architectures(体系结构)来进行解决。这个是网络设计的核心。
那么,孪生网络是怎么回事儿呢?
Siamese networks apply an identical transformation(对2个输入图像而言相同的变换φ) φ to both inputs and then combine their representations using another function g according to f (z, x) = g(φ(z), φ(x)). When the function g is a simple distance or similarity metric, the function φ can be considered an embedding.
上图
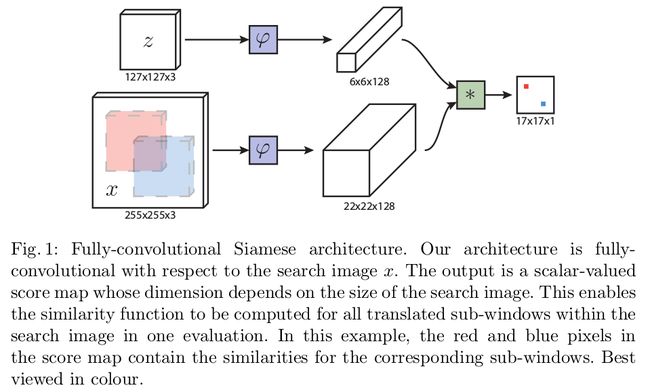
2.1 Fully-convolutional Siamese architecture
深度卷积网络的相似性学习是通过孪生体系结构体现的。接下来介绍全卷积体系结构。
函数是完全卷积的定义:
1、We say that a function is fully-convolutional if it commutes with translation.
2、To give a more precise definition, introducing L τ to denote the translation operator
(L τ x)[u] = x[u − τ ], a function h that maps signals to signals is fully-convolutional with integer stride k if
h(L kτ x) = L τ h(x) (1)
for any translation τ . (When x is a finite signal, this only need hold for the valid region of the output.)
完全卷积网络的优点:
提供更大的搜索图像作为网络的Input,而不是相同大小的候选图像。并且,在单次评估的时候,可以计算基于密集网格的所有变换子窗口的相似度。
要充分实现这一优点的话,可以:
use a convolutional embedding function φ and combine the resulting feature maps using a cross-correlation layer
f (z, x) = φ(z) ∗ φ(x) + b 1 , (2)
where b 1 denotes a signal which takes value b ∈ R in every location. The output of this network is not a single score but rather a score map defined on a finite grid D ⊂ Z 2 as illustrated in Figure 1. Note that the output of the embedding function is a feature map with spatial support as opposed to a plain vector.
在跟踪期间,我们使用以目标的上一个位置为中心的搜索图像。最大得分的位置与得分图的中心有关,乘上网络的stride,就可以得出从帧到帧的目标的位移。在单次前进中,多个尺度通过组装小批量的尺度变化图像而被搜索到。
使用互相关的方法联合特征图和在更大的图像上评估网络在数学上相当于combining feature maps using the inner product and evaluating the network on each translated sub-window independently.这种方法在training and testing的时候都是有用的。
2.2 Training with large search images
采用判别式的方法。


图解:当一个子窗口的延伸超过图像的范围,缺失的部分用平均RGB值来填充。
在上图Fig2中,上下的图像对儿是从一个视频的两帧中提取出来的,都包含目标,最多以T帧作为间隔。
物体的class在training的过程中是不考虑的。每个图像中物体的尺寸在不破坏图像的纵横比的情况下被 normalized(归一化)。
接着上图。

score map中,正负examples的loss,为了消除类的不均衡性是要进行加权的。
Note that since the network is symmetric f (z, x) = f (x, z), it is in fact also fully-convolutional in the exemplar.This allows us to use different size exemplar images for different objects in theory。
2.3 ImageNet Video for tracking
It can safely be used to train a deep model for tracking without over-fitting.
2.4 Practical considerations
出于实际考虑(practical consideration),有以下几个方面的内容,都是实战干货啊。
Dataset curation

Network architecture
The dimensions of the parameters and activations are given in Table 1. Max-pooling is employed after the first two convolutional layers. ReLU non-linearities follow every convolutional layer except for conv5, the final layer. During training, batch normalization is inserted immediately after every linear layer.The stride of the final representation is eight. An important aspect of the design is that no padding(填充) is introduced within the network. Although this is common practice in image classification, it violates (违反了)the fully-convolutional property of eq. 1.

Tracking algorithm
Since our purpose is to prove the efficacy of our fully-convolutional Siamese network and its generalization capability when trained on ImageNet Video, we use an extremely simplistic algorithm to perform tracking.
Unlike more sophisticated trackers, we do not update a model or maintain a memory of past appearances, we do not incorporate additional cues such as optical flow(光流) or colour histograms, and we do not refine our prediction with bounding box regression.
Yet, despite its simplicity, the tracking algorithm achieves surprisingly good results when equipped with our offline-learnt similarity metric.
Online, we do incorporate some elementary temporal constraints(纳入一些基本的时间约束): we only search for the object within a region of approximately four times its previous size, and a cosine window is added to the score map to penalize large displacements.
Tracking through scale space is achieved by processing several scaled versions of the search image.(通过处理几个缩放版本的搜索图像来实现缩放空间的跟踪) Any change in scale is penalized and updates of the current scale are damped.(任何尺度上的变化都会受到惩罚,当前尺度的更新也会受到阻碍)
这部分内容的一个整体效果如下。(部分截图啦)

结论:我们的方法不执行任何的模型更新,只用第一帧来进行计算,但结果却出乎意料的在motion blur、 drastic change of appearance、 poor illumination and scale change 表现出鲁棒性。此外,我们的方法对于复杂的场景是敏感的,因为模型从未被更新,所以很容易drift。
3 Related work
对于目标跟踪问题而言,有一些工作是train RNN。比如训练RNN来预测每一帧的目标的绝对位置。再比如,使用可微的注意机制来简单的训练一个用于跟踪的RNN。这些方法结果不是很理想,但确实是值得研究的。
利用每个新的视频来训练深度卷积网络是不可行的,这个时候可以想到已经预训练好参数的微调方法。SO-DLT和MDNet都在离线阶段训练了一个用于简单探测任务的卷积网络,在测试阶段用SGD来学习一个探测器,可惜,这些方法的实时性不是很好。一种可以替代的方法是shallow methods(使用预训练的卷积网络的内在表现作为特征)。这类方法有FCNT,DeepSRDCF等。他们取得了很好的结果,但是却由于卷积网络所表现的高维性而没有实现实时性的操作。
我们的工作,当然也有其他人的一些工作,提出使用用于目标跟踪的卷积网络,这个网络会学习一个图像对的函数。就拿GOTURN来说,一个卷积网络被训练出来,主要是用于从两张图片到第一张图片所展示的物体在第二张图片的位置定位的直接回归。预测的是一个矩形而不是位置具有这样的优点:尺度的变化可以在不评估的情况下进行很好的控制。然而这种方法还是有缺点的,缺点:它不具有对第二张图像变换的内在的不变性。这意味着网络必须在所有位置显示示例,这是通过相当大的数据集实现的。
具有竞争性的方法MDNet,SINT,GOTURN,这些方法在视频序列上进行训练,用的是属于相同ALOV/OTB/VOT的训练数据,这种数据可能存在过拟合现象。所以,这篇论文中提出用于有效的目标跟踪的卷积网络,这个网络的特点是不用与测试集相同的视频数据来训练。
4 Experiments
4.1 Implementation details
Training:这个模块主要是进行参数设定,并说明相关的设定方法。
Tracking:使用简单的策略在线更新示例的特征表示。策略有线性插值,双三次插值等。可知,用后者可以进行更加精确的定位,为了处理尺度变化,我们搜索超过5个尺度(-2,-1,0,1,2)的对象,并用线性插值法更新比例。
4.2 Evaluation
两个变体:
SiamFC(Siamense Fully-Convolutional)
SiamFC-3s(搜索超过了3个尺度而不是5个尺度)
4.3 The OTB-13 benchmark
The OTB-13 benchmark 考虑到了在不同阈值下平均每帧的成功率:一个跟踪器如果估计值与真实值间的IoU(交集)超过某个阈值的话,那么在给定帧下是成功的。
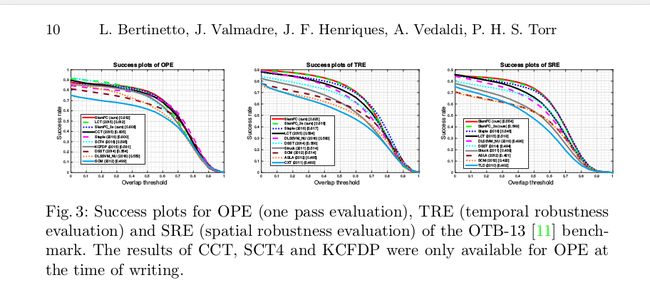
4.4 The VOT benchmarks
vot2015-final 可以在所选的356个序列中评估跟踪器,在这些序列中,很好的展现了7种不同的挑战情景。
VOT-14 results:
跟踪器的两个评价指标:accuracy and robustness
Accuracy is calculated as the average IoU.
Robustness is expressed in terms of the total number of failures.
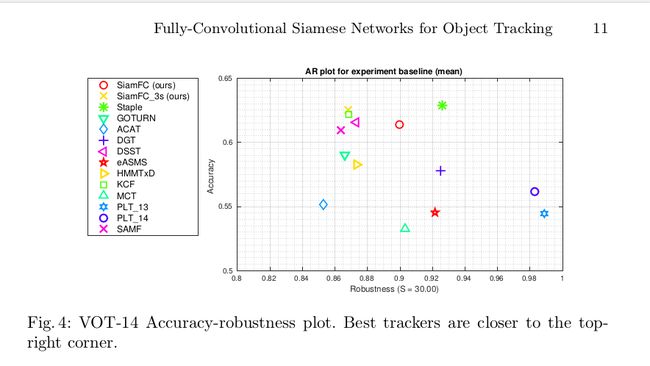
VOT-15 results:

VOT-16 results:
我们的fully-convolutional Siamese network 可以达到state-of-the-art 效果,是一款real-time的追踪器。此外,还可以采取一些方法提升性能,比如:
model update,bounding-box regression,fine-tuning,memory
4.5 Dataset size
训练卷积网络需要大量-大量-大量的数据集。

This finding suggests that using a larger video dataset could increase the performance even further.
5 Conclusion
In this work, we depart from (放弃)the traditional online learning methodology employed in tracking, and show an alternative approach that focuses on learning strong embeddings in an offline phase. Differently from their use in classification settings, we demonstrate that for tracking applications Siamese fully-convolutional deep networks have the ability to use the available data more efficiently. This is reflected both at test-time, by performing efficient spatial searches, but also at training-time, (在两大阶段都有有效的空间搜索的体验)where every sub-window effectively represents a useful sample with little extra cost. The experiments show that deep embeddings provide a naturally rich source of features for online trackers, and enable simplistic test-time strategies to perform well. We believe that this approach is complementary to more sophisticated(复杂) online tracking methodologies,and expect future work to explore this relationship more thoroughly.