自动化测试基础
一、 软件测试分类
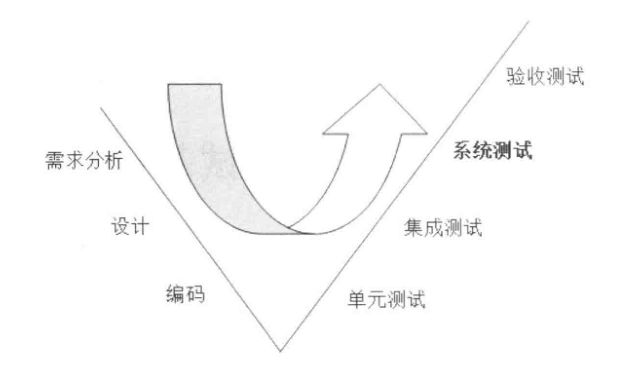
1.1 根据项目流程阶段划分软件测试
1.1.1 单元测试
单元测试(或模块测试)是对程序中的单个子程序或具有独立功能的代码段进行测试的过程。
1.1.2 集成测试
集成测试是在单元测试的基础上,先通过单元模块组装成系统或子系统,再进行测试。重点是检查模块之间的接口是否正确。
1.1.3 系统测试
系统测试是针对整个产品系统进行的测试,验证系统是否满足需求规格的定义,以及软件系统的正确性和性能等是否满足其需求规格的要求。
1.1.4 验收测试
验收测试是部署软件之前的最后一个测试阶段。验收测试的目的是确保软件准备就绪,向软件购买者展示该软件系统能够满足用户的需求。
1.2 白盒测试、黑盒测试、灰盒测试
白盒测试与黑盒测试,主要是根据软件测试工作中对软件代码的可见程度进行的划分。这也是软件测试领域中最基本的概念之一。
1.2.1 黑盒测试
黑盒测试,指的是把被测的软件看做一个黑盒子,我们不去关心盒子里面的结构是什么样子的,只关心软件的输入数据和输出结果。
它只检查程序呈现给用户的功能是否按照需求规格说明书的规定正常使用、程序是否能接受输入数据并产生正确的输出信息。黑盒测试着眼于程序外部结构,不考虑内部逻辑结构,主要针对软件界面和软件功能进行测试。
1.2.2 白盒测试
白盒测试,指的是把盒子打开,去研究里面的源代码和程序执行结果。
它是按照程序内部的结构测试程序,通过测试来检验产品内部动作是否按照设计规格说明书的规定正常进行,检验程序中的每条逻辑路径是否都能按预定要求正确工作。
1.2.3 灰盒测试
灰盒测试介于黑盒测试和白盒测试之间。
可以这样理解,灰盒测试既关注输出对于输入的正确性,同时也关注内部表现。但这种关注不像白盒测试那样详细、完整,它只是通过一些表征性的现象、事件、标志来判断内部的运行状态。有时候输出是正确的,但内部其实已经错误了,这种情况非常多。如果每次都通过白盒测试来操作,效率会很低,因此需要采取灰盒测试的方法。
1.3 功能测试与性能测试
从软件的不同测试面可以划分为功能测试与性能测试
1.3.1 功能测试
功能测试主要检查世纪功能是否符合用户的需求,因此测试的大部分工作也是围绕软件的功能进行。设计软件的目的就是满足用户对其功能的需求,如果偏离了这个目的,则任何测试工作都是没有意义的。
功能测试又可以细分为很多种:逻辑功能测试,界面测试、易用性测试、安装测试、兼容性测试等。
1.3.2 性能测试
性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行的测试。
软件的性能包括很多方面,主要有时间性能和空间性能两种。
- 时间性能:主要是指软件的一个具体的响应时间。例如一个登陆所需要的时间,一个商品交易所需要的时间等。当然,抛开具体的测试环境,来分析一次事务的响应时间是没有任何意义的,它需要在搭建好的一个具体且独立的测试环境下进行。
- 空间性能:主要指软件运行时所消耗的系统资源,例如硬件资源,CPU、内存、网络宽带消耗等。
1.4 手工测试与自动化测试
从对软件测试工作的自动化程度可以划分为手工测试与自动化测试。
1.4.1 手工测试
手工测试就是由测试人员一个一个地去执行测试用例,通过键盘鼠标等输入一些参数,并查看返回结果是否符合预期结果。
手工测试并非专业术语,手工测试通常是指我们在系统测试阶段所进行的功能测试,为了更明显地与自动化测试进行区分,这里使用了手工测试这种说法。
1.4.2 自动化测试
自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程。通常,在设计测试用例并通过评审之后,由测试人员根据测试用例中描述的规则流程一步步执行测试,把得到的世纪结果与期望结果进行比较。在此过程中,为了节省人力、时间和硬件资源,提高测试效率,便引入了自动化测试的概念。
自动化测试又可分为:功能自动化测试与性能自动化测试。
- 功能自动化测试:是把以人为驱动的测试行为转化为机器执行的一种过程。通过测试工具(或框架)录制/编写测试脚本,对软件的功能进行测试,并验证测试结果是否正确,从而代替部分的手工测试工作,达到节约人力成本和时间成本的目的。
- 性能自动化测试:通过性能功能来模拟成千上万的虚拟用户向系统发送请求,从而验证系统的处理能力。
1.5 冒烟测试、回归测试、随机测试、探索性测试和安全测试
这几种测试出现在软件测试的周期中,既不算具体明确的测试阶段,也不是具体的测试方法。
1.5.1 冒烟测试
是指在对一个新版本进行大规模的系统测试之前,先验证一下软件的基本功能是否实现,是否具备可测性。
引入到软件测试中,就是指测试小组在正是测试一个新版本之前,先投入较少的人力和时间验证一个软件的主要功能,如果主要功能都没有运行通过,则打回开发组重新开发。这样做的好处是可以节省时间和人力投入到不可测的项目中。
1.5.2 回归测试
回归测试是指修改了旧代码后,重新进行测试以确认修改后没有引入新的错误或导致其他代码产生错误。
回归测试一般是在进行第二轮软件测试时开始的,验证第一轮软件测试中发现的问题是否得到修复。当然,回归也是一个循环的过程,如果回归的问题通不过,则需要开发人员修改后再次进行回归,直到所有问题回归通过为止。
1.5.3 随机测试
是指测试中的所有输入数据都是随机生成的,其目的是模拟用户的真实操作,并发现一些边缘性的错误。
随机测试可以发现一些隐蔽的错误,但是也有很多缺点,例如测试不系统,无法统计代码覆盖率和需求覆盖率、发现的问题难以重现等。一般是放在测试的最后执行。随机测试更专业的升级版叫做探索性测试。
1.5.4 探索性测试
探索性测试可以说是一种测试思维技术,它没有很多实际的测试方法、技术和工具,但却是所有测试人员多应该掌握的一种测试思维方式。探索性测试强调测试人员的主观能动性,抛弃繁杂的测试计划和测试用例设计过程,强调在碰到问题时及时改变测试策略。
1.5.5 安全测试
安全测试在IT软件产品的生命周期中,特别是产品开发基本完成至发布阶段,对产品进行检验以验证产品符合安全需求定义和产品质量标准的过程。
安全测试现在越来越受到企业的关注和重视,因为由于安全性问题造成的后果是不可估量的,尤其是互联网产品,最容易遭受各种安全攻击。
二、分层的自动化测试
我们应该有更多的低级别的单元测试,而不仅仅是通过用户界面运行的高层的端到端的测试。
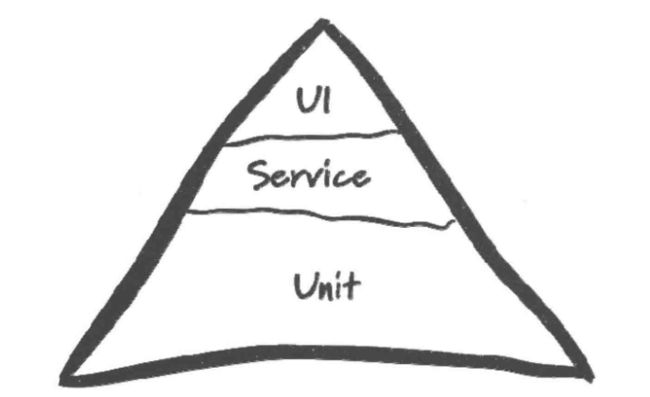
传统的自动化测试我们可以理解为基于产品UI层的自动化测试,它是将黑盒功能测试转化为由程序或工具执行的一种自动化测试。
但是在目前的大多数研发组织当中,都存在开发与测试团队割裂(部门墙)、质量职责错配(测试主要对质量负责)的问题,在这种状态下,测试团队的一个“正常”反应就是试图在测试团队能够掌握的黑盒测试环节进行尽可能全面的覆盖,甚至是尽可能全面的 UI 自动化测试。
这可能会导致两个恶果:一是测试团队规模的急剧膨胀;二是所谓的全面UI自动化测试运动。因为UI是非常易变得,所以UI自动化测试维护成本相对高昂。
分层自动化测试倡导的是从黑盒(UI)单层到黑白盒多层的自动化测试体系,从全面黑盒自动化测试到对系统的不同层次进行自动化测试。
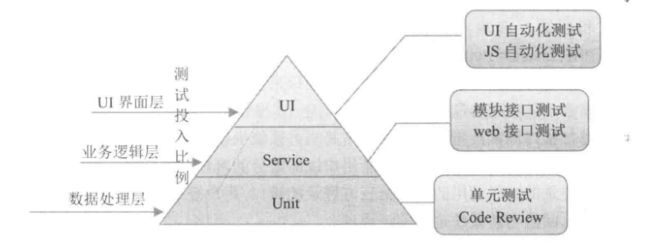
2.1 单元自动化测试
单元自动化测试是指对软件中的最小可测试单元进行检查和验证。对于单元测试中单元的含义,一般来说,要根据实际情况去判断其具体含义,如C语言中单元是指一个函数,Java中单元是指一个类,图形化的软件中单元是指一个窗口或一个菜单等。总的来说,单元就是人为规定的最小的被测功能模块。规范的进行单元测试需要借助单元测试框架,如Java语言的Junit、TextNG,C#语言的NUnit,以及Python语言的unittest、pytest等,目前几乎所有的主流语言都有其相应的单元测试框架。
Code Review中文翻译为代码评审或diamante审查,是指在软件开发过程中,通过对源代码进行系统性检查的过程。通常的目的是查找系统缺陷、保证软件总体质量以及提高开发者自身水平。与Code Review 相关的插件和工具有很多,例如Java语言中基于Eclipse的ReviewClipse和Jupiter、主要针对Python语言的Review Board等。
2.2 接口自动化测试
Web应用的接口自动化测试大体分为两类:模块接口测试和Web接口测试。
2.2.1 模块接口测试
主要测试模块之间的调用与返回。当然,我们也可以将其看做是单元测试的基础。它主要强调对一个类方法或函数的调用,并对返回结果的验证,所用到的测试工具与单元自动化测试相同。
2.2.2 Web接口测试
Web接口测试又可以分为两类:服务器接口测试和外部接口测试。
- 服务器接口测试:指测试浏览器与服务器的接口。我们知道Web开发一般分前端和后端,前端开发人员用HTML/CSS/JavaScript等技术,后端开发人员用PHP/Java/C#/Python/Ruby等各种语言。用户的操作是在前端页面上,需要后端提供服务器接口,前端通过调用这些接口来获取需要的数据,通过HTTP协议实现前后端的数据传递。
- 外部接口测试:指调用的接口由第三方系统提供。典型的例子就是第三方登录,例如新上线的产品为了免于新用户注册账号的麻烦会提供第三方登录,纳闷用户在登录的时候调用的就是第三方登录的接口,用户登录信息的验证由第三方完成,并返回给当前系统是否验证通过。
当然,接口测试也有相应的类库或工具,例如测试HTTP的有HttpUnit、Postman等
2.3 UI自动化测试
UI层是用户使用该产品的入口,所有功能都通过这一层提供并展示给用户,所以测试工作大多集中在这一层进行。为了减轻这一层的测试人力和时间成本,早期的自动化测试工具主要针对该层设计。目前主流的测试工具有UFT、Watie、Robot Framework、Selenium等。
除UI层所展示的功能外,前端代码同样需要进行测试。在前端开发中最主要的莫过于JavaScript脚本语言,而QUnit就是针对JavaScript的一个强大的单元测试框架。
测试金字塔映射了不同测试阶段所投入的自动化测试的比例,UI层被放到了塔尖,这也说明UI层应该投入较少的自动化测试。如果系统只关注UI层的自动化测试并不是一种明智的做法,因为其很难从本质上保证产品的质量。如果妄图实现全面的UI层的自动化测试,那么需要投入大量的人力和时间,然而, 最终获得的收益可能远低于所投入的成本,因为对于一个系统来讲,越接近用户其越容易变化,为了适应这种变化就必须要投入更多的成本。
既然UI层的自动化测试这么劳民伤财,那么我们是不是只做单元测试与接口测试就可以了呢?答案是否定的,因为不管什么样的产品,最终呈现给用户的都是UI层的功能,所以产品才需要招聘大量的测试人员进行UI层的功能测试。也正是因为测试人员在UI层投入了大量的时间与精力,所以我们才有必要通过自动化的方式帮助测试人员解放部分重复的工作。所以,应该更多的提倡“半自动化”的开展测试工作,把可以自动化测试的工作交给工具或脚本完成,这样测试人员就可以把更多的精力放在更重要的测试工作上,例如探索性测试等。
至于在金字塔中每一层测试的投入比例则要根据实际的产品特征来划分。在《Google测试之道》一书中提到,Google对产品测试类型划分为:小测试、中测试和大测试,采用70%(小),20%(中)、10%(大)的比例,大体对应测试金字塔中的Unit、Service和 UI 层。
在进行自动化测试中最担心的是变化,因为变化会直接导致测试用例的运行失败,所以需要对自动化脚本进行不断调整。如何控制失败、降低维护成本是对自动化测试工具及人员能力的挑战。反过来讲,一份永远都运行通过的自动化测试用例已经失去了它存在的价值。
三、什么样的项目适合自动化测试
- 任务测试明确,不会频繁变动。
- 每日构建后的测试验证。
- 比较频繁的回归测试。
- 软件系统界面稳定,变动少。
- 需要在多平台上运行的相同测试案例、组合遍历型的测试,大量的重复任务。
- 软件维护周期长。
- 项目进度压力不太大。
- 被测软件系统开发较为规范,能够保证系统的可测试性。
- 具备大量的自动化测试平台。
- 测试人员具备较强的编程能力。
在我们普遍的自动化测试经验中,一般满足以下三个条件就可以对项目开展自动化测试。
1. 软件需求变动不频繁
自动化测试脚本变化的大小与频率决定了自动化测试的维护成本。如果软件需求变动过于频繁,那么测试人员就需要根据变动的需求来不断地更新自动化测试用例,从而适应新的功能。而脚本的维护本身就是一个开发代码的过程,需要扩展、修改、调试,有时还需要对架构做出调整。如果所花费的维护成本高于利用其节省的测试成本,那么自动化测试就失去了它的价值与意义。
一种折中的做法是先对系统中相对稳定的模块与功能进行自动化测试,而变动较大的部分用用工进行测试。
2. 项目周期较长
由于自动化测试需求的确定,自动化测试框架的设计、脚本的开发与调试均需要时间来完成,而这个过程本身就是一个软件的开发过程,如果项目的周期较短,没有足够的时间去支持这样一个过程的话,那么就不需要进行自动化测试了。
3. 自动化测试脚本可重复使用
自动化测试脚本的重复使用要从三个方面来考量:一是所测试的项目之间是否存在很大的差异性(如C/S系统架构与B/S系统架构的差异);二是所选择的测试技术和工具是否适应这种差异;三是测试人员是否有能力设计开发出适应这种差异的自动化测试框架。
四、自动化测试及工具简述
自动化测试的概念有广义与侠义之分:广义上来讲,所有借助工具来辅助进行软件测试的方法都可以称为自动化测试;狭义上来讲,主要指基于UI层的功能自动化测试。
目前市面上的自动化测试工具非常多,下面几款是比较常见的自动化测试工具。
1.UTF
UTF有QTP和ST合并而来,有HP公司开发。它是一个企业级的自动测试工具,提供了强大易用的录制回放功能,同时兼容对象识别模式与图像识别模式两种识别方式,支持B/S与C/S两种架构的软件测试,是目前主流的自动化测试工具。
2. Robot Framework
Robot Framework 是一款基于Python语言编写的自动化测试框架,具备良好的可扩展性,支持关键字驱动,可以同时测试多种类型的客户端或者接口,可以进行分布式测试。
3. Watir
Watir是一个基于Web模式的自动化功能测试工具。Watir是一个Ruby语言库,使用Ruby语言进行脚本开发。
4. Selenium
Selenium也是一个用于Web应用程序测试的工具,支持多平台、多浏览器、多语言去实现自动化测试。目前在Web自动化领域应用越来越广泛。
当然,除上面所列的自动化测试工具外,根据不同的应用还有很多商业的或开源的以及公司自己开发的自动化测试工具。
五、Selenium工具介绍
5.1 什么是Selenium?
Selenium主要用于Web应用程序的自动化测试,但并不局限于此,它还支持所有基于Web的管理任务自动化。
Selenium的特点如下:
- 开源、免费
- 多浏览器支持:Firefox、Chrome、IE、Opera、Edge
- 多平台支持:Linux Windows MAC
- 多语言支持:Java Python Ruby C# JavaScript C++
- 对Web页面有良好的支持
- 简单(API简单),灵活(用开发语言驱动)
- 支持分布式测试用例执行
5.2 Selenium IDE
Selenium IDE是嵌入到Firefox浏览器中的一个插件,实现简单的浏览器操作的录制与回放功能。官方定位:
快速地创建bug重现脚本,在测试人员测试过程中,发现bug之后可以通过IDE将重现的步骤录制下来,以帮助开发人员更容易地重现BUG。
IDE录制的脚本可以转换成多种语言,从而帮助我们快速地开发脚本。关于这个功能在后面的章节中我们会着重介绍。
5.3 Selenium Grid
Selenium Grid是一种自动化的测试辅助工具,Gird通过利用现有的计算机基础设施,能加快Web-App的功能测试。利用Grid可以很方便地实现在多台机器上和异构环境中运行测试用例。
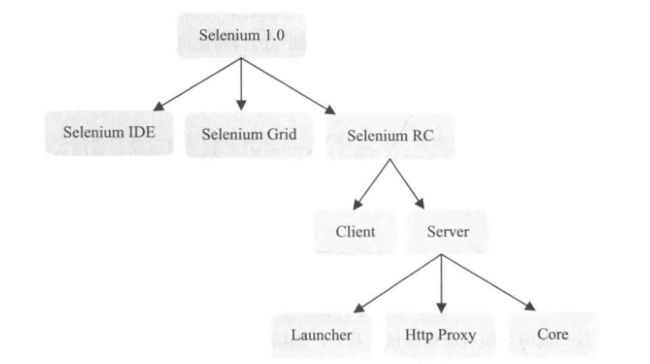
5.4 Selenium RC
Selenium RC是Selenium家族的核心部分。Selenium RC支持多种不同语言编写的自动化测试脚本,通过Selenium RC的服务器作为代理服务器去访问应用,从而达到测试的目的。
Selenium RC分为Client Libraries和Selenium Server。Client Libraries库主要用于编写测试脚本,用来控制Selenium Server的库。Selenium Server负责控制浏览器行为。总的来说,Selenium Server主要包括三部分,Launcher/Http Proxy和Core。其中,Selenium Core是被Selenium Server 嵌入到浏览器页面中的。其实Selenium Core就是一堆JavaScript函数的集合,即通过这些JavaScript函数,我们才可以实现用程序对浏览器进行操作。Launcher用于启动浏览器,把Selenium Core加载到浏览器页面当中,并把浏览器的代理设置为Selenium Server的Http Proxy。
5.5 Selenium 2.0
搞清了Selenium 1.0的家族关系,再来看看Selenium 2.0。Selenium 2.0就是把 WevDriver 加入到了这个家族中,简单用公式表示为:
Selenium 2.0 = Selenium1.0 + WebDriver
需要强调的是,在Selenium 2.0中主推的是WebDriver,可以将其看做Selenium RC 的替代品。因为Selenium为了保持向下的兼容性,所以在Selenium 2.0中并没有彻底地抛弃Selenium RC。如果是初次使用Selenium开发一个新的自动化测试项目,那么可以直接使用WebDriver。
Selenium RC与WebDriver的区别?
Selenium RC是在浏览器中运行JavaScript应用,使用浏览器内置的JavaScript翻译器来翻译和执行selenese命令(selenese是Selenium命令集合)。
WebDriver是通过原生浏览器支持或者浏览器扩展来直接控制浏览器。WebDriver针对各个浏览器而开发,取代了嵌入到被测Web应用中的JavaScript,与浏览器紧密集成,因此支持创建更高级的测试,避免了JavaScript安全模型导致的限制。除了来自浏览器厂商的支持之外,WebDriver还利用操作系统级的调用,模拟用户输入。
Selenium 与 WebDriver 合并原因?
部分原因是WebDriver 解决了Selenium存在的缺点(例如能够绕过JavaScript沙箱,我们有出色的API)。部分原因是 Selenium 解决了WebDriver存在的问题(例如支持广泛的浏览器),部分原因是因为Selenium的主要贡献者和WebDriver的主要贡献者都觉得合并项目是为用户提供最优秀框架的最佳途径。
WebDriver API
火狐浏览器驱动:https://github.com/mozilla/geckodriver/releases
谷歌浏览器驱动:http://npm.taobao.org/mirrors/chromedriver
Selenium 及 驱动 安装
pip install Selenium 下载浏览器驱动 http://www.seleniumhq.org/download/ 把下载的浏览器驱动即相应的exe文件放在PATH下即可。 from selenium import webdriver import time driver = webdriver.Firefox() driver.get("http://www.baidu.com") driver.find_element_by_id("kw").send_keys("Selenium2") driver.find_element_by_id("su").click() time.sleep(10) driver.quit()
一、什么是Selenium 和WebDriver?
Selenium是一个浏览器自动化操作框架。Selenium主要由三种工具组成。第一个工具SeleniumIDE,是Firefox的扩展插件,支持用户录制和回访测试。录制/回访模式存在局限性,对许多用户来说并不适合,因此第二个工具——Selenium WebDriver提供了各种语言环境的API来支持更多控制权和编写符合标准软件开发实践的应用程序。最后一个工具——SeleniumGrid帮助工程师使用Selenium API控制分布在一系列机器上的浏览器实例,支持并发运行更多测试。在项目内部,它们分别被称为“IDE”、“WebDriver”和“Grid”。
这里主要介绍它的第二个工具:WebDriver。
官网上是这么介绍它的:WebDriver is a clean, fast framework for automated testing of webapps. 但是我觉得它并不局限与进行自动化测试,完全可以用作其它用途。
WebDriver针对各个浏览器而开发,取代了嵌入到被测Web应用中的JavaScript。与浏览器的紧密集成支持创建更高级的测试,避免了JavaScript安全模型导致的限制。除了来自浏览器厂商的支持,WebDriver还利用操作系统级的调用模拟用户输入。WebDriver支持Firefox(FirefoxDriver)、IE (InternetExplorerDriver)、Opera (OperaDriver)和Chrome (ChromeDriver)。 它还支持Android (AndroidDriver)和iPhone (IPhoneDriver)的移动应用测试。它还包括一个基于HtmlUnit的无界面实现,称为HtmlUnitDriver。WebDriver API可以通过Python、Ruby、Java和C#访问,支持开发人员使用他们偏爱的编程语言来创建测试。
from selenium import webdriver b = webdriver.Firefox() b.get("http://www.baidu.com") b.find_element_by_id("kw").send_keys("火影") b.find_element_by_id("su").click() b.close()
在不同的编程语言中会有语法的差异,我们跑去这些差异,在不同的语言中实现百度搜索的自动化实例都完成了下面几个操作。
- 首先导入Selenium(WebDriver)相关模块。
- 调用Selenium的浏览器驱动,获取浏览器句柄(driver)并启动浏览器。
- 通过句柄访问百度URL。
- 通过句柄操作页面元素(百度输入框和按钮)。
- 通过句柄关闭浏览器。
所以,webDriver支持多种编程语言,也可以看作是多种语言都支持WebDriver,唯一的不同在于不同语言实现的类和方法名的命名差异性。当然,这样做的好处不言而喻:每个人都可以根据自己熟悉的语言来使用 WebDriver 编写自动化测试脚本。
二、WebDriver API
2.1 元素定位
2.1.1 id 定位
find_element_by_id("id")
2.1.2 name 定位
find_element_by_name("name")
2.1.3 class 定位
find_element_by_class_name("class")
2.1.4 tag 定位
find_element_by_tag_name("div")
# 就是标签,比如/等
2.1.5 link 定位
link 定位与前面介绍的几种定位方法有所不同,它专门用来定位文本链接。百度输入框上面的几个文本链接的代码如下:
<a class="mnav" name="tj_trnews" href="http://www.baidu.com">新闻a>
<a class="mnav" name="tj_trhao123" href="http://www.hao123.com">hao123a>
<a class="mnav" name="tj_trmap" href="http://map.baidu.com">地图a>
<a class="mnav" name="tj_trvideo" href="http://v.baidu.com">视频a>
<a class="mnav" name="tj_trtieba" href="http://tieba.baidu.com">贴吧a>
其实可以使用name属性来定位。这里演示link定位的使用
find_element_by_link_text("新闻")
find_element_by_link_text("hao123")
find_element_by_link_text("地图")
find_element_by_link_text("视频")
find_element_by_link_text("贴吧")
find_element_by_link_text("文本") 方法通过元素标签对之间的文本信息来定位元素。
2.1.6 partial link 定位
partial link 定位是对 link 定位的一种补充,有些文本链接会比较长,这个时候我们可以取文本链接的一部分定位,只要这一部分信息可以唯一地标识这个链接。
<a class="mnav" name="tj_lang" href="#">一个很长很长的文本链接a>
可以如下定位:
find_element_by_partial_link_text("一个很长的")
find_element_by_partial_link_text("文本链接")
find_element_by_partial_link_text()方法通过元素标签对之间的部分文本信息来定位元素。
前面介绍的几种定位方法相对来说比较简单,理想状态下,在一个页面当中每一个元素都有一个唯一id和name属性值,我们可以通过它们的属性值来找到它们。但在实际项目中并非想象得这般美好,有时候一个元素并没有id、name属性,或者页面上多个元素的id和name属性值相同,又或者每一次刷新页面,id值都会随机变化。怎么办?可以用Xpath与CSS定位。
2.1.7 XPath 定位
可参考:http://www.w3school.com.cn/xpath/index.asp
XPath是一种在XML文档中定位元素的语言。因为HTML可以看做XML的一种实现,所以selenium用户可以使用这种强大的语言在web应用中定位元素。
绝对路径定位
XPath 有多种定位策略,最简单直观的就是写出元素的绝对路径。
参考baidu.html前端工具所展示的代码,我们可以通过下面的方式找到百度输入框和搜索按钮。
find_element_by_xpath("/html/body/div/div[2]/div/div/div/from/span/input")
find_element_by_xpath("/html/body/div/div[2]/div/div/div/from/span[2]/input")
find_element_by_xpath()方法使用XPath语言来定位元素。XPath主要用标签名的层级关系来定位元素的绝对路径,最外层为html语言。在body文本内,一级一级往下查找,如果一个层级下有多个相同的标签名,那么就按上下顺序确定是第几个,例如,div[2]表示当前层级下的第二个div标签。
利用元素属性定位
除了使用绝对路径外,XPath 也可以使用元素的属性值来定位。同样以百度输入框和搜索按钮为例:
find_element_by_xpath("//*[@id='kw']") #注意外层 " 符号和内层 ' 符号
find_element_by_xpath("//*[@id='su']")
//表示当前页面某个目录下,input 表示定位元素的标签名,[@id="kw"]表示这个元素的 id 属性值等于 kw。下面通过name和class属性值来定位。
浏览器开发者工具F12,复制,XPath
层级与属性结合
如果一个元素本身没有可以唯一标识这个元素的属性值,name我们可以找其上一级元素,如果它的上一级元素有可以唯一标识属性的值。也可以拿来使用。
find_element_by_xpath('//[@id="cnblogs_post_body"]/p[1]/a[1]')
使用逻辑运算符
如果一个属性不能唯一地区分一个元素,我们还可以使用逻辑运算符链接多个属性来查找元素。
<input type="text" id="kw" class="su" name="ie">
<input type="text" id="kw" class="aa" name="ie">
<input type="text" id="bb" class="su" name="ie">
如上面的三行元素,假设我们现在要定位第一行元素,如果使用 id 将会与第二行元素重名,如果使用 class 将会与第三行元素重名,如果同时使用 id 和 class 就会唯一地标识这个元素,这个时候就可以通过逻辑运算符 “and” 来连接两个条件。
当然,我们也可以用“and”连接更多的属性来唯一地标识一个元素。
find_element_by_xpath('//input[@id="kw" and @class="su"]/span/input')
2.1.8 CSS 定位
CSS 是一种语言,它用来描述HTML和XML文档的表现。CSS使用选择器来为页面元素绑定属性。这些选择器可以被Selenium用作另外的定位策略。
CSS可以较为灵活地选择空间的任意属性,一般情况下定位速度要比XPath快,但对于初学者来说学习起来稍微有点难度。
(1) 通过 class 属性定位
find_element_by_css_selector(".s_ipt")
find_element_by_css_selector(".bgs_btn")
find_element_by_css_selector()方法用于CSS语言定位元素,点号(.)表示通过class属性来定位元素。
(2) 通过 id 属性定位
find_element_by_css_selector("#kw")
find_element_by_css_selector("#su")
(3) 井号(#)表示通过 id 属性来定位元素
通过标签名定位:
find_element_by_css_selector("input")
在 CSS 语言中,用标签名定位元素不需要任何符号标识,直接使用标签名即可。但我们前面已经了解到,标签名重复的概率非常大,所以通过这种方式很难找到想要的元素。
(3.1)通过父子关系定位
find_element_by_css_selector("span>input")
上面的写法表示有父亲元素,它的标签名为apan,查找它的所有标签名叫input的子元素。
(3.2)通过属性定位
find_element_by_css_selector("[autocomplete=off]")
find_element_by_css_selector("[name='kw']")
find_element_by_css_selector("[type='submit']")
在 CSS 当中也可以使用元素的任意属性,只要这些属性可以唯一标识这个元素,对于属性值来说,可加引号,也可以不加,但注意和整个字符串的引号进行区分。
(3.3)组合定位
我们当然可以把上面的定位策略组合起来使用,这就大大加强了定位元素的唯一性。
find_element_by_css_selector("span.bgs_ipt_wr>input.s_inpt")
find_element_by_css_selector("span.bgs_btn_wr>input#su")
有一个父元素,它的标签名叫 span;它有一个class属性值叫 bgs_ipt_wr;它有一个子元素,标签名叫 input,并且这个子元素的 class 属性值叫 s_ipt。
浏览器开发者工具F12,复制,selector
2.1.9 用 By 定位元素
针对前面介绍的 8 种定位方法,WebDriver 还提供了另外一套写法,即统一调用 find_element()方法,通过 By 来声明定位的方法,并且传入对应定位方法的定位参数,具体如下:
find_element(By.ID,"kw")
find_element(By.NAME,"wd")
find_element(By.CLASS_NAME,"s_ipt")
find_element(By.TAG_NAME,"input")
find_element(By.LINK_TEXT,"新闻")
find_element(By.PARTIAL_LINK_TEXT,"新")
find_element(By.XPATH,"//*[@class='bgs_btn']")
find_element(By.CSS_SELECTOR,"span.bgs_btn_wr>input#su")
find_element()方法只用于定位元素。它需要两个参数,第一个参数是定位的类型,由By提供;第二个参数是定位的具体方法,在使用By之前需要将By类导入。
from selenium.webdriver.common.by import By
通过查看 WebDriver 的底层实现代码发现它们其实是一回事儿,例如,find_element_by_id()方法的实现。
def find_elements_by_id(self, id_):
"""
Finds multiple elements by id.
:Args:
- id\_ - The id of the elements to be found.
:Returns:
- list of WebElement - a list with elements if any was found. An
empty list if not
:Usage:
elements = driver.find_elements_by_id('foo')
"""
return self.find_elements(by=By.ID, value=id_)
2.2、控制浏览器
2.2.1 控制浏览器窗口大小
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://m.mail.10086.cn")
#参数数字为像素点
print("设置浏览器宽480、高800显示")
driver.set_window_size(480,800)
driver.quit()
在PC端执行自动化测试脚本大多的情况下是希望浏览器在全屏模式下执行,那么可以使用maximize_window()方法使打开的浏览器全屏显示,其用法与set-window_size() 相同,但它不需要参数。
2.2.2 控制浏览器后退、前进
在使用浏览器浏览网页时,浏览器提供了后退和前进按钮,可以方便地在浏览过的网页之间切换,WebDriver 也提供了对应的 back() 和 forward() 方法来模拟后退和前进按钮,下面通过例子来演示这两个方法的使用。
from selenium import webdriver
driver = webdriver.Firefox()
#访问百度首页
first_url="http://www.baidu.com"
print("now access %s" %(first_url))
driver.get(first_url)
#访问新闻页面
second_url="http://news.baidu.com"
print("now access %s" %(second_url))
driver.get(second_url)
#返回(后退)到百度首页
print("back to %s" %(first_url))
driver.back()
#前进到新闻页
print("forward to %s" %(second_url))
driver.forward()
driver.quit()
为了看清脚本的执行过程,下面每操作一步都通过print() 来打印当前的 URL 地址,执行结果如下:
now access http://www.baidu.com
now access http://news.baidu.com
back to http://www.baidu.com
forward to http://news.baidu.com
2.2.3 模拟浏览器刷新
driver.refresh() #刷新当前页面
2.3 简单元素操作
- clear(): 清除文本
- send_keys(*value): 模拟按键输入
- click(): 单击元素
clear() 方法用于清除文本输入框中的内容。例如,登录框内一般默认会有“账号”、“密码”等提示信息,用于引导用户输入正确的数据;但如果直接向输入框中输入数据,则可能会与输入框中的提示信息拼接,从而造成输入信息错误。这个时候可以先使用clear()方法来清除输入框中的默认提示信息。
send_keys() 方法模拟键盘向输入框里输入内容。如上面的例子中,通过这个方法向用户名和密码框中输入登录信息。当然,它的作用不仅于此,我们还可以用它发送键盘按键,甚至用它来模拟文件上传。
click() 方法可以用来单击一个元素,前提是它是可以被单击的对象,它与 send_keys() 方法是Web页面操作中最常用到的两个方法。其实 click() 方法不仅可用于单击一个按钮,它还能单击任何可以单击的文字/图片链接、复选框、单选框、下拉框等。
from selenium import webdriver b = webdriver.Chrome() b.get("https://mail.qq.com/") b.find_element_by_xpath('//*[@id="u"]').clear() b.find_element_by_xpath('//*[@id="u"]').send_keys("[email protected]") b.find_element_by_xpath('//*[@id="p"]').send_keys("*******") b.find_element_by_xpath('//*[@id="login_button"]').click() b.quit()
会报错,表示找不到元素。
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"xpath","selector":"//*[@id="u"]"}
元素找不到有好几种可能:
2.3.1 Frame/Iframe原因定位不到元素
这个是最常见的原因,首先要理解下frame的实质,frame中实际上是嵌入了另一个页面,而webdriver每次只能在一个页面识别,因此需要先定位到相应的frame,对那个页面里的元素进行定位。
from selenium import webdriver b = webdriver.Chrome() b.get("https://mail.qq.com/") b.switch_to.frame('login_frame') #需先跳转到iframe框架 b.find_element_by_xpath('//*[@id="u"]').clear() b.find_element_by_xpath('//*[@id="u"]').send_keys("[email protected]") b.find_element_by_xpath('//*[@id="p"]').send_keys("********") b.find_element_by_xpath('//*[@id="login_button"]').click() b.quit()
from selenium import webdriver b = webdriver.Chrome() b.get("https://mail.qq.com/") elementi= b.find_element_by_xpath('//*[@id="login_frame"]') b.switch_to.frame(elementi) #需先跳转到iframe框架 b.find_element_by_xpath('//*[@id="u"]').clear() b.find_element_by_xpath('//*[@id="u"]').send_keys("[email protected]") b.find_element_by_xpath('//*[@id="p"]').send_keys("********") b.find_element_by_xpath('//*[@id="login_button"]').click() b.quit()
2.3.2 Xpath描述错误原因
由于Xpath层级太复杂,容易犯错。
可以使用Firefox的firePath,复制xpath路径。该方式容易因为层级改变而需要重新编写过xpath路径,不建议使用,初学者可以先复制路径,然后尝试去修改它。
2.3.3 页面还没有加载出来,就对页面上的元素进行的操作
- 设置等待时间;缺点是需要设置较长的等待时间,案例多了测试就很慢;
- 设置等待页面的某个元素出现,比如一个文本、一个输入框都可以,一旦指定的元素出现,就可以做操作。
- 在调试的过程中可以把页面的html代码打印出来,以便分析。
2.3.4 动态id定位不到元素
2.3.5 二次定位,如弹出框登录
2.3.6 不可见元素定位
如上百度登录代码,通过名称为tj_login查找的登录元素,有些是不可见的,所以加一个循环判断,找到可见元素(is_displayed())点击登录即可。
参考:https://blog.csdn.net/apollolkj/article/details/77096547
2.3.7 WebElement 接口常用方法
submit()
submit() 方法用于提交表单。例如,在搜索框输入关键字之后的“回车”操作,就可以通过submit() 方法模拟。
from selenium import webdriver driver = webdriver.Firefox() driver.get("http://www.youdao.com") driver.find_element_by_id("translateContent").send_keys("hello") #提交输入框的内容 driver.find_element_by_id("translateContent").submit()
上面的例子,我们通过定位有道搜索框并通过submit()提交搜索框的内容,同样达到单击“搜索”按钮的效果。有时候 submit() 可以与 click() 方法互换来使用, submit() 同样可以提交一个按钮,但 submit() 的应用范围远不及 click() 广泛。
- size: 返回元素的尺寸
- text: 获取元素的文本
- get_attribute(name): 获取属性值
- is_dispalyed(): 设置该元素是否用户可见,注意,是不可见,不是不存在
from selenium import webdriver driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 获取输入框的尺寸 size = driver.find_element_by_id("kw").size print(size) # 返回百度页面底部备案信息 text = driver.find_element_by_id("cp").text print(text) # 返回元素的属性值,可以是id、name、type或其他任意属性 attribute = driver.find_element_by_id("kw").get_attribute("type") print(attribute) # 返回元素的结果是否可见,返回结果为True或False result = driver.find_element_by_id("kw").is_displayed() # 注意,是不可见,不是不存在。不存在会直接报错 print(result) driver.quit() >>> {'height': 22.0, 'width': 500.0} ©2018 Baidu 使用百度前必读 意见反馈 京ICP证030173号 京公网安备11000002000001号 text True ***Repl Closed***
2.4 鼠标事件
ActionChains 类提供了鼠标操作的常用方法:
- perform(): 执行所有ActionChains中存储的行为
- context_click(): 右击
- double_click(): 双击
- drag_and_drop(): 拖动
- move_to_element(): 鼠标悬停
2.4.1 鼠标右击操作
from selenium import webdriver # 引入 ActionChains 类 from selenium.webdriver.common.action_chains import ActionChains driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 定位到要右击的元素 right_click = driver.find_element_by_id("kw") # 对定位到的元素执行鼠标右键操作 ActionChains(driver).context_click(right_click).perform()
- from selenium.webdriver.common.action_chains import ActionChains 导入提供鼠标操作的 ActionChains 类
- ActionChains(driver) 调用 ActionChains() 类,将浏览器驱动 driver 作为参数传入
- context_click(right_click) context_click() 方法用于模拟鼠标右键操作,在调用时需要指定元素定位。
- perform() 执行所有 ActionChains 中储存的行为,可以理解成是对整个操作的提交动作。
2.4.2 鼠标悬停
from selenium import webdriver # 引入 ActionChains 类 from selenium.webdriver.common.action_chains import ActionChains driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 定位到要悬停的元素 above = driver.find_element_by_id("su") # 对定位到的元素执行悬停操作 ActionChains(driver).move_to_element(above).perform()
2.4.3 鼠标双击操作
from selenium import webdriver # 引入 ActionChains 类 from selenium.webdriver.common.action_chains import ActionChains driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 定位到要双击的元素 double_click = driver.find_element_by_id("su") # 对定位到的元素执行双击操作 ActionChains(driver).double_click(double_click).perform()
2.4.4 鼠标拖动操作
drag_and_drop(source,target)在源元素上按住鼠标左键,然后移动到目标元素上释放。
- source:鼠标拖动的源元素
- target:鼠标释放的目标元素
from selenium import webdriver # 引入 ActionChains 类 from selenium.webdriver.common.action_chains import ActionChains driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 定位元素的原位置 element = driver.find_element_by_id("su") target = driver.find_element_by_id("su") # 执行元素的拖动操作 ActionChains(driver).drag_and_drop(element,target).perform()
2.5 键盘事件
keys() 类提供了键盘上几乎所有按键的方法。前面了解到,send_keys()方法可以用来模拟键盘输入,除此之外,我们还可以用它来输入键盘上的按键,甚至是组合键,如 Ctrl + A ,Ctrl + C等。
#! /usr/bin/env python # -*- coding: utf-8 -*- # __author__ = "Q1mi" # Date: 2018/7/2 from selenium import webdriver # 引入Keys模块 from selenium.webdriver.common.keys import Keys driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 输入框输入内容 driver.find_element_by_id("kw").send_keys("seleniumm") # 删除多输入的一个m driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE) # 输入空格键 + “教程” driver.find_element_by_id("kw").send_keys(Keys.SPACE) driver.find_element_by_id("kw").send_keys("教程") # ctrl + a 全选输入框内容 driver.find_element_by_id("kw").send_keys(Keys.CONTROL,"a") # ctrl + x 剪切输入框内容 driver.find_element_by_id("kw").send_keys(Keys.CONTROL,"x") # ctrl + v 粘贴内容到输入框 driver.find_element_by_id("kw").send_keys(Keys.CONTROL,"v") # 通过回车键来代替单击操作 driver.find_element_by_id("su").send_keys(Keys.ENTER)
以下为常用的键盘操作:
send_keys(Keys.BACK_SPACE) 删除键(BackSpace) send_keys(Keys.SPACE) 空格键(Space) send_keys(Keys.TAB) 制表键(Tab) send_keys(Keys.ESCAPE) 回退键(Esc) send_keys(Keys.ENTER) 回车键(Enter) send_keys(Keys.CONTROL,"a") 全选(Ctrl+A) send_keys(Keys.CONTROL,"c") 复制(Ctrl+C) send_keys(Keys.CONTROL,"x") 剪切(Ctrl+X) send_keys(Keys.CONTROL,"v") 粘贴(Ctrl+V) send_keys(Keys.F1) 键盘F1 ...... . send_keys(Keys.F12) 键盘F12
2.6 获取验证信息
在编写功能测试用例时,会假定一个预期结果,在执行用例的过程中把得到的实际结果与预期结果进行比较,从而判断用户的通过或失败。自动化测试用例是由机器去执行的,通常机器并不像人一样有思维和判断能力,那么是不是模拟各种操作页面的动作没有报错就说明用例执行成功呢?并非如此,假如我们模拟百度搜索的用例,当新的迭代版本上线后,每一页的搜索结果少一条,但用例的执行不会报错,因此这个 bug 永远不会被自动化测试发现。
那么是不是在运行自动化测试用例时需要由测试人员盯着用例的执行来辨别执行结果呢?如果是这样的话,自动化测试就失去了“自动化”的意义。在自动化用例执行完成之后,我们可以从页面上获取一些信息来“证明“用例执行是成功还是失败。
通常用得最多的几种验证信息分别是title、URL和text。text方法在前面已经讲过,它用于获取标签对之间的文本信息。
from selenium import webdriver import time driver = webdriver.Chrome() driver.get("https://mail.qq.com/") time.sleep(2) frame_add = driver.find_element_by_xpath('//*[@id="login_frame"]') driver.switch_to_frame(frame_add) #需先跳转到iframe框架 print("Before login==========") # 打印当前页面title now_title = driver.title print(now_title) # 打印当前页面URL now_url = driver.current_url print(now_url) # 执行邮箱登录 driver.find_element_by_id("u").clear() driver.find_element_by_id("u").send_keys("[email protected]") driver.find_element_by_id("p").clear() driver.find_element_by_id("p").send_keys("*******") driver.find_element_by_id("login_button").click() time.sleep(5) print("After login==========") # 再次打印当前页面title now_title = driver.title print(now_title) # 再次打印当前页面URL now_url = driver.current_url print(now_url) # 获取登录的用户名 user = driver.find_element_by_id("useraddr").text print(user) driver.quit() >>> C:\Users\Administrator\AppData\Local\Programs\Python\Python37\python.exe C:/Users/Administrator/Desktop/py/test.py Before login========== 登录QQ邮箱 https://mail.qq.com/ After login========== QQ邮箱 https://mail.qq.com/cgi-bin/frame_html?sid=IDp2I6d3Vi8WORtA&r=b6242c8e186a9f7c4b80aab437e760f8 [email protected] Process finished with exit code 0
- title:用于获得当前页面的标题。
- current_url:用户获得当前页面的URL
通过打印结果,我们发现登录前后的title和URL明显不同。我们可以把登录之后的这些信息存放起来,作为登录是否成功的验证信息。当然,这里URL每次登录都会有所变化,是不能拿来做验证信息的。title可以拿来做验证信息,但它并不能明确地标识是哪个用户登录成功了,因此通过text获取用户文本([email protected])是很好的验证信息。
2.7 设置元素等待
如今大多数Web应用程序使用AJAX技术。当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成的,这给元素的定位增加了困难。如果因为在加载某个元素时延迟而造成ElementNotVisibleException的情况出现,那么就会降低自动化脚本的稳定性,我们可以通过设置元素等待改善这种问题造成的不稳定。
WebDriver提供了两种类型的等待:显式待和隐式等待
2.7.1 显式等待
显式等待使 WebDriver 等待某个条件成立时继续执行,否则在达到最大时长时抛弃超时等待。(TimeoutException)
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Firefox() driver.get("http://www.baidu.com") element = WebDriverWait(driver, 5, 0.5).until( EC.presence_of_element_located((By.ID,"kw")) ) element.send_keys('selenium') driver.quit()
WebDriverWait 类是由 WebDriver 提供的的等待方法。在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常。具体格式如下
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
- driver 浏览器驱动
- timeout 最长超时时间,默认以秒为单位
- poll_frequency 检测的间隔(步长)时间,默认为0.5s
- ignored_exceptions 超时后的异常信息,默认情况下抛NoSuchElementException 异常
WebDriverWait() 一般由 until() 或者 until_not() 方法配合使用,下面是 until() 和 until_not() 方法的说明。
- until(method, message=' ')
调用该方法提供的驱动程序作为一个参数,直到返回值为True
- until_not(method, message=' ')
调用该方法提供的驱动程序作为一个参数,直到返回值为False
在本例中,通过 as 关键字将 expected_conditions 重命名为 EC,并调用 presence_of_element_located() 方法判断元素是否存在。
expected_conditions 类所提供的预期条件判断的方法如下表所示。
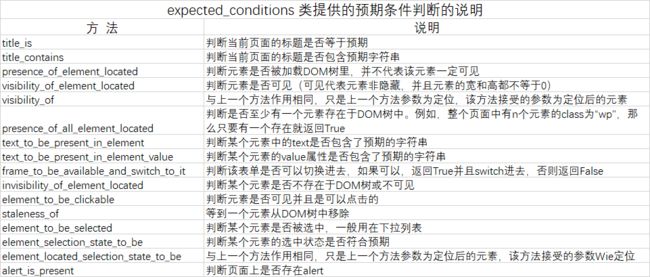
除expected_conditions 所提供的丰富的预期条件判断方法外,还可以使用前面学过的is_displayed() 方法来判断元素是否可见。
from selenium import webdriver from time import sleep, ctime driver = webdriver.Firefox() driver.get("http://www.baidu.com") print(ctime()) for i in range(10): try: el = driver.find_element_by_id("kw22") if el.is_displayed(): break except Exception as e: pass sleep(1) else: print("time out") driver.close() print(ctime()) >>> Tue Jul 3 09:41:42 2018 time out Tue Jul 3 09:41:54 2018 ***Repl Closed***
相对来说,这种方式更容易理解,通过for循环10次,每次循环判断元素的is_displayed()状态是否为True;如果为True,则break跳出循环;否则sleep(1) 后继续循环判断,直到10次循环结束后,打印“time out”信息。
2.7.2 隐式等待
隐式等待是通过一定的时长等待页面上某元素加载完成。如果超出还没有被加载,则抛出 NoSuchElementException 异常。WebDriver提供方法来实现隐式等待,默认设置为0.它的用法相对来说要简单得多。
from selenium import webdriver from selenium.common.exceptions import NoSuchElementException from time import ctime driver = webdriver.Firefox() # 设置隐式等待10秒 driver.implicitly_wait(10) driver.get("http://www.baidu.com") try: print(ctime()) driver.find_element_by_id("kw22").send_keys('selenium') except NoSuchElementException as e: print("查找元素异常 %s" %(e)) else: pass finally: print(ctime()) driver.quit() >>> Wed Jul 4 12:51:30 2018 查找元素异常 Message: Unable to locate element: [id="kw22"] Wed Jul 4 12:51:40 2018 Process finished with exit code 0
implicitly_wait() 默认参数的单位为秒,本例中设置等待时长为10秒。首先这10秒并非一个固定的等待时间,它并不影响脚本的执行速度。其次,它并不针对页面上的某一元素进行等待。当脚本执行到某个元素定位时,如果元素可以定位,则继续执行;如果元素定位不到,则它将以轮询的方式不断地判断元素是否被定位到。假设在第6秒定位到了元素则继续执行,若直到超出设置时间(10秒)还没有定位到元素,则抛出异常。
在上面的例子中,显然百度输入框的定位 id=kw22 是有误的,通过打印的两个时间可以看出,当执行度一百度输入框的操作时,超过了10秒的等待。
2.7.3 sleep 休眠方法
有时候我们希望脚本在执行到某一位置时做固定时间的休眠,尤其是在脚本调试过程中。这时可以使用sleep()方法,需要说明的是,sleep()方法由Python的time模块提供。
from selenium import webdriver from time import sleep driver = webdriver.Firefox() driver.get("http://www.baidu.com") sleep(2) driver.find_element_by_id("kw").send_keys("webdriver") driver.find_element_by_id("su").click() sleep(3) driver.quit()
当执行到sleep()方法时会固定休眠一定的时长,然后再继续执行。sleep()方法默认参数以秒为单位,如果设置时长小于1秒,则可以用小数表示,如sleep(0.5)表示休眠0.5秒。
2.8 定位一组元素
在2.4中我们已经学了8中定位方法,这8种定位方法时针对单个元素定位的,WebDriver还提供了与之对应的8种用于定位一组元素的方法。
find_elements_by_id() find_elements_by_name() find_elements_by_class_name() find_elements_by_tag_name() find_elements_by_link_text() find_elements_by_partial_link_text() find_elements_by_xpath find_elements_by_css_selector()
定位一组元素的方法与定位单个元素的方法类似,唯一的区别是在单词element后面多了一个s表示复数。定位一组元素一般用于以下场景:
- 批量操作元素,例如勾选页面上所有的复选框
- 先获取一组元素,再从这组对象中过滤出需要操作的元素。例如定位出页面上所有的checkbox然后选择其中的一个进行操作。
from selenium import webdriver import os,time driver = webdriver.Firefox() file_path = "file:///" + os.path.abspath("checkbox.html") # file:/// 换成 file: 也可以,但是这个是必须的前缀 driver.get(file_path) # 选择页面上所有的tag name 为input的元素 inputs = driver.find_elements_by_tag_name('input') # 然后从中过滤出type为checkbox的元素,单击勾选 for i in inputs: if i.get_attribute("type") == "checkbox": i.click() time.sleep(1) driver.quit()
前面提到,通过tag name的定位方式很难定位到单个元素,因为元素标签名重名的概率很高,因而在定位一组元素时,这种方式就派上用场了。在上面的例子中先通过find_elements_by_tag_name()找到一组标签名为input的元素。然后通过for循环进行遍历,在遍历过程中,通过get_attribute()方法获取元素的type属性是否为“checkbox”,如果为“checkbox”,就认为这个元素是一个复选框,对其进行勾选操作。
需要注意的是,在上面的例子中,通过浏览器打开的是一个本地的html文件,所以需要用到Python的os模块,path.abspath()方法用于获取当前路径下的文件。
除此之外,我们还可以使用XPath或CSS来直接判断属性值,从而进行单击操作。
from selenium import webdriver import os,time driver = webdriver.Firefox() file_path = "file:///" + os.path.abspath("checkbox.html") driver.get(file_path) # 通过XPath找到type=checkbox的元素 # checkboxes = driver.find_elements_by_xpath("//input[@type='checkbox']") # 通过CSS找到type=checkbox的元素 checkboxes = driver.find_elements_by_css_selector("//input[type=checkbox]") for checkbox in checkboxes: if i.get_attribute("type") == "checkbox": checkbox.click() time.sleep(1) # 打印当前页面上的type为checkbox的个数 print(len(checkboxes)) # 把页面上最后1个checkbox的钩给去掉 driver.find_element_by_css_selector("input[type=checkbox]").pop().click() driver.quit()
通过XPath或CSS来查找一组元素时,省去了判断步骤。因为定位方法已经做了判断,只需循环对这一组元素进行勾选即可。
2.9 多表单切换
在Web应用中经常会遇到frame/iframe表单嵌套页面的应用,WebDriver只能在一个页面上对元素识别与定位,对于frame/iframe表单内嵌页面上的元素无法直接定位。这时就需要通过switch_to.frame() 方法将当前定位的主体切换为frame/iframe表单的内嵌页面中。
from selenium import webdriver b = webdriver.Chrome() b.get("https://mail.qq.com/") # 切换到 iframe(id="login_frame") b.switch_to.frame('login_frame') b.find_element_by_xpath('//*[@id="u"]').clear() b.find_element_by_xpath('//*[@id="u"]').send_keys("[email protected]") b.find_element_by_xpath('//*[@id="p"]').send_keys("********") b.find_element_by_xpath('//*[@id="login_button"]').click() b.quit()
switch_to.frame() 默认可以直接取表单的 id 或 name 属性。如果 iframe 没有可用的 id 和 name 属性,则可以通过下面的方式进行定位。
from selenium import webdriver b = webdriver.Chrome() b.get("https://mail.qq.com/") # 先通过xpath定位到iframe elementi= b.find_element_by_xpath('//*[@id="login_frame"]') #再将定位对象传给switch_to.frame()方法 b.switch_to.frame(elementi) b.find_element_by_xpath('//*[@id="u"]').clear() b.find_element_by_xpath('//*[@id="u"]').send_keys("[email protected]") b.find_element_by_xpath('//*[@id="p"]').send_keys("********") b.find_element_by_xpath('//*[@id="login_button"]').click() b.switch_to.parent_frame() b.quit()
switch_to包的方法详解
在switch_to的基础上,有这么几个方法,鉴于基本上都是之前曾经讲过的,这次把等价的方法也列出来,供大家参考
1. driver.switch_to.active_element() ---------------替换-------------- driver.switch_to_active_element()
定位到当前聚焦的元素上 聚焦这部分参考:https://blog.csdn.net/huilan_same/article/details/52338073
2. driver.switch_to.alert() ---------------替换-------------- driver.switch_to_alert()
切换到alert弹窗
3. driver.switch_to.default_content() ---------------替换-------------- driver.switch_to_default_content()
切换到最上层页面
4. driver.switch_to.frame(frame_reference) ---------------替换--------------driver.switch_to_frame(frame_reference)
通过id、name、element(定位的某个元素)、索引来切换到某个frame
5. driver.switch_to.parent_frame()
这是switch_to中独有的方法,可以切换到上一层的frame,对于层层嵌套的frame很有用
6. driver.switch_to.window(window_name) 等同于 driver.switch_to_window(window_name)
切换到制定的window_name页面
注: 官方把selenium.webdriver包中的switch方法全部封装成了一个包,这样能够比较明了和方便,也符合软件编程中的高内聚低耦合的思想。
2.10 多窗口切换
在页面操作过程中有时候点击某个链接会弹出新的窗口,这时就需要主机切换到新打开的窗口上进行操作。WebDriver提供了switch_to.window() 方法,可以实现在不同的窗口之间切换。
以百度首页和百度注册页为例。
from selenium import webdriver import time driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get("http://www.baidu.com") # 获得百度搜索窗口句柄 sreach_windows = driver.current_window_handle driver.find_element_by_link_text("登录").click() driver.find_element_by_link_text("立即注册").click() # 获得当前所有打开的窗口的句柄 all_handles = driver.window_handles # 进入注册窗口 for handle in all_handles: if handle != sreach_windows: driver.switch_to.window(handle) print("now register window!") driver.find_element_by_name("userName").send_keys("username") driver.find_element_by_id("TANGRAM__PSP_3__password").send_keys("password") time.sleep(2) # 回到搜索窗口 for handle in all_handles: if handle == sreach_windows: driver.switch_to.window(handle) print("now sreach window!") # 会跳出来一个让你下载APP的弹窗,把这个弹窗给点掉 try: driver.find_element_by_id("TANGRAM__PSP_4__closeBtn") except: break else: driver.find_element_by_id("TANGRAM__PSP_4__closeBtn").click() # 弹窗消失后,再去查找 driver.find_element_by_id("kw").send_keys("selenium") driver.find_element_by_id("su").click() time.sleep(2) driver.quit()
脚本的执行过程:首先打开百度首页,通过current_window_handle 获得当前窗口的句柄,并赋值给变量sreach_handle。接着打开登录弹窗,在登录弹窗上单击“立即注册”,从而打开新的注册窗口。通过window_handles获得当前打开的所有窗口的句柄,并赋值给变量all_handles。
第一个循环遍历all_handles,如果handle不等于sreach_handle,那么一定是注册窗口,因为脚本执行过程中只打开了两个窗口。所以,通过switch_to.window()切换到注册页进行注册操作。第二个循环类似,不过这一次判断如果handle等于sreach_handle,那么切换到百度搜索页,然后进行搜索操作。
在本例中所涉及的新方法如下:
current_window_handle:获得当前窗口句柄。
window_handles:返回所有窗口的句柄到当前会话。
switch_to.window():用于切换到相应的窗口,与上一节的switch_to.frame()类似,前者用于不同窗口的切换,后者用于不同表单之间的切换。
2.11 警告框处理
在WebDriver 中处理JavaScript所生成的alert、confirm以及prompt十分简单,具体做法是使用switch_to.alert() 方法定位到 alert/confirm/prompt,然后使用text/accept/dismiss/send_keys等方法进行操作。
- text:返回 alert/confirm/prompt中的文字信息。
- accept():接受现有警告框
- dismiss():解散现有警告框
- send_keys(keysToSend):发送文本至警告框。keysToSend:将文本发送至警告框。
百度搜索设置弹出的窗口是不能通过前端工具对其进行定位的,这个时候就可以通过switch_to.alert()方法接受这个弹窗
from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains import time driver = webdriver.Chrome() driver.implicitly_wait(10) driver.get("http://www.baidu.com") # 鼠标悬停至“设置”链接 link = driver.find_element_by_link_text("设置") ActionChains(driver).move_to_element(link).perform() # 打开搜索设置 driver.find_element_by_link_text("搜索设置").click() time.sleep(0.3) # 没有这个延迟会出现问题,表现在点不到保存设置上,具体还不清楚咋回事情 # 保存设置 driver.find_element_by_link_text('保存设置').click() # 接受警告框 driver.switch_to.alert.accept() driver.quit()
2.12 上传文件
上传文件是比较常见的Web功能之一,但WebDriver并没有提供专门用于上传的方法,如何实现上传操作关键在于上传文件的思路。
一般Web页面的上传功能的操作需要单击“上传”按钮后打开本地的Window窗口,从窗口中选择本地文件进行上传。而webDriver是无法操作Windows控件,所以,对于初学者来说,一般思路会卡在如何识别Window空间这个问题上。
对于Web页面的上传功能实现一般由以下两种方式。
- 普通上传:普通的附件上传是将本地文件的路径作为一个值放在input标签中,通过form表单将这个值提交给服务器。
- 插件上传:一般是指基于Flash、JavaScript或Ajax等技术所实现的上传功能。
2.12.1 send_keys 实现上传
对于通过input标签实现的上传功能,可以将其看做是一个输入框,即通过send_keys()指定本地文件路径的方式实现文件上传。
from selenium import webdriver import os,time driver = webdriver.Chrome() file_path = "file:///" + os.path.abspath("test.html") driver.get(file_path) # 定位上传按钮,添加本地文件 driver.find_element_by_name("file").send_keys("C:\\Users\\Administrator\\Desktop\\py\\geckodriver.log") driver.quit()
2.12.2 Autolt 实现上传
autoit 目前最新版本是v3,它是一个使用类似BASIC脚本语言的免费软件,它被设计用来进行Windows GUI(图形用户界面)的自动化测试。它利用模拟键盘按键,鼠标移动和窗口/控件的组合来实现自动化任务。
具体参考《自动化测试实战 基于PYTHON语言》一书4.12.2章节。并不推荐,因为通过Python调用的exe程序并不在Python的可控范围内。换句话说,exe执行多长时间,执行是否出错,Python程序都无法得知。
pyautoit了解一下
PyAutoGUI 也了解一下
2.13 下载文件
https://blog.csdn.net/huilan_same/article/details/52789954
WebDriver 允许我们设置默认的文件下载路径,也就是说,文件会自动下载并且存放到设置的目录中。下面以Firefox浏览器为例,执行文件的下载。
from selenium import webdriver import os fp = webdriver.FirefoxProfile() fp.set_preference("browser.download.folderList",2) fp.set_preference("browser.download.manager.showWhenStarting",False) fp.set_preference("browser.download.manager.dir",os.getcwd()) fp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/octet-stream") # 下载文件的类型 driver = webdriver.Firefox(firefox_profile=fp) driver.get("http://pypi.Python.org/pypi/selenium") driver.find_element_by_partial_link_text("selenium-2").click()
为了让Firefox浏览器能实现文件下载,我们需要通过FirefoxProfile()对其做一些设置。
browser.download.folderList
设置成0代表下载到浏览器默认下载路径,设置成2则可以保存到制定目录
browser.download.manager.showWhenStarting
是否显示开始:True为显示,Flase为不显示
browser.download.dir
用于指定所下载文件的目录。os.getcwd()函数不需要传递参数,用于返回当前的目录。
browser.helperApps.neverAsk.saveToDisk
指定要下载页面的Content_type值,“application/octet-stream”为文件的类型
HTTP Content_type常用对照表:http://tool.oschina.net/commons
这些参数的设置可以通过在Firefox浏览器地址栏输入:about:config进行设置。
将所有设置信息在调用WebDriver的Firefox()方法时作为参数传递给浏览器。Firefox浏览器在下载时就根据这些设置信息将文件下载在当前脚本的目录下。
上面例子中的设置只针对Firefox浏览器,不同浏览器设置方法不应。通用的借助 AutoIt来操作Windows空间进行下载。
2.14 操作Cookie
有时候我们需要验证浏览器中cookie是否正确,因为基于真实cookie的测试是无法通过白盒和集成测试的。WebDriver提供了操作Cookie的相关方法,可以获取、添加和删除cookie信息。
WebDriver 操作 cookie的方法:
- get_cookies(): 获得所有cookie信息
- get_cookie(name): 返回字典的key为“name”的cookie信息
- add_cookie(cookie_dict): 添加cookie。“cookie_dict”指字典对象,必须有name和value值
- delete_cookie(name,optionsString): 删除cookie信息。“name”是要删除的cookie的名称,“optionString”是该cookie的选项,目前支持的选项包括“路径”,“域”。
- delete_all_cookies(): 删除所有cookie信息
下面通过get-cookies()来获取当前浏览器的cookie信息
from selenium import webdriver driver = webdriver.Firefox() driver.get("http://www.youdao.com") # 获取cookie信息 cookie = driver.get_cookies() # 将获得cookie的信息打印 print(cookie) driver.quit() >>> [{'name': 'YOUDAO_MOBILE_ACCESS_TYPE', 'value': '1', 'path': '/', 'domain': '.youdao.com', 'expiry': 1562137504, 'secure': False, 'httpOnly': False}, {'name': 'DICT_UGC', 'value': 'be3af0da19b5c5e6aa4e17bd8d90b28a|', 'path': '/', 'domain': '.youdao.com', 'expiry': None, 'secure': False, 'httpOnly': False}, {'name': 'OUTFOX_SEARCH_USER_ID', 'value': '[email protected]', 'path': '/', 'domain': '.youdao.com', 'expiry': 2476681504, 'secure': False, 'httpOnly': False}, {'name': 'JSESSIONID', 'value': 'abcXbMI_bHumq7K2x9Erw', 'path': '/', 'domain': '.youdao.com', 'expiry': None, 'secure': False, 'httpOnly': False}, {'name': '___rl__test__cookies', 'value': '1530601505713', 'path': '/', 'domain': 'www.youdao.com', 'expiry': None, 'secure': False, 'httpOnly': False}, {'name': 'OUTFOX_SEARCH_USER_ID_NCOO', 'value': '1523083508.1908145', 'path': '/', 'domain': '.youdao.com', 'expiry': 1593673505, 'secure': False, 'httpOnly': False}]
从执行结果可以看出,cookie数据是以字典的形式进行存放的。知道了cookie的存放形式,接下来我们就可以按照这种形式向浏览器中写入cookie信息。
from selenium import webdriver driver = webdriver.Firefox() driver.get("http://www.youdao.com") # 向cookie的name和value中添加会话信息 driver.add_cookie({"name":"key-aaaa","value":"value-bbbb"}) # 遍历cookies中的name和value信息并打印,当然还有上面添加的信息。 for cookie in driver.get_cookies(): print("%s -> %s" %(cookie["name"],cookie["value"])) driver.quit() >>> YOUDAO_MOBILE_ACCESS_TYPE -> 1 DICT_UGC -> be3af0da19b5c5e6aa4e17bd8d90b28a| OUTFOX_SEARCH_USER_ID -> [email protected] JSESSIONID -> abcq80IlD53H4bj3V_Erw ___rl__test__cookies -> 1530601866047 OUTFOX_SEARCH_USER_ID_NCOO -> 2091021681.247173 key-aaaa -> value-bbbb
从执行结果可以看到,最后一条cookie信息是在脚本执行过程中通过 add_cookie() 方法添加的。通过遍历得到所有的cookie信息,从而找到key为“name”和“value”的特定cookie的value。
那么在什么情况下会用到cookie的操作呢?例如开发人员开发一个功能,当用户登录后,会将用户的用户名写入浏览器cookie,指定的key为“username”,那么我们就可以通过 get_cookies()找到username,打印value。如果找不到username或对应的value为空,那么说明cookie没有成功地保存到浏览器中。
delete_cookie()和delete_all_cookies() 的使用也很简单,前者通过name删除一个特定的cookie信息,后者直接删除浏览器中的所有cookies()信息。
2.15 调用JavaScript
虽然WebDriver提供了操作浏览器的前进和后退方法,但对于浏览器滚动条并没有提供相应的操作方法。在这种情况下,就可以借助JavaScript来控制浏览器的滚动条。WebDriver提供了 execute_script() 方法来执行JavaScript代码。
一般我们想到的必须使用滚动条的场景是:注册时的法律条文的阅读。判断用户是否阅读完的标准是,滚动条是否拉到页面底部。当然,有时候为了使操作更接近用户行为也会使用滚动条,例如用户要操作的元素在页面的第二屏,一般用户不会对看不到的元素进行操作,那么就需要先将滚动条拖到页面的第二屏再进行操作。
用于调整浏览器滚动条位置的JavaScript代码如下:
...... window.scrollTo(0,450) ......
window.scrollTo() 方法用于设置浏览器窗口滚动条的水平和垂直位置。方法的第一个参数表示水平的左间距,第二个参数表示垂直的上边距。其代码如下:
from selenium import webdriver from time import sleep # 访问百度 driver = webdriver.Firefox() driver.get("http://www.baidu.com") # 设置浏览器窗口大小 driver.set_window_size(600,600) # 搜索 driver.find_element_by_id("kw").send_keys("selenium") driver.find_element_by_id("su").click() sleep(2) # 通过javascript设置浏览器窗口的滚动条位置 js="window.scrollTo(100,450);" driver.execute_script(js) sleep(3) driver.quit()
通过浏览器打开百度进行搜索,并且提前通过 set_window_size() 方法将浏览器窗口设置为固定宽高显示,目的是让窗口出现水平和垂直滚动条。然后通过 execute_script() 方法执行 JavaScript 代码来移动滚动条的位置。
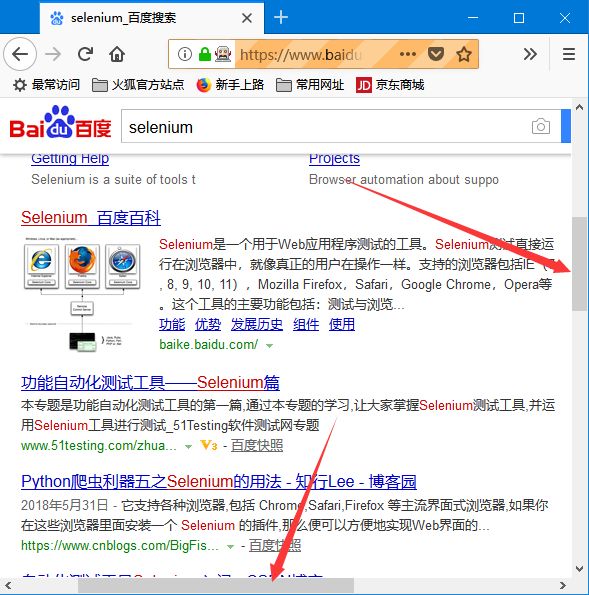
1、滚动条回到顶部:
js="var q=document.getElementById('id').scrollTop=0" driver.execute_script(js)
或者
js="var q=document.documentElement.scrollTop=0" driver.execute_script(js)
2、滚动条拉到底部:
js="var q=document.getElementById('id').scrollTop=10000" driver.execute_script(js)
或者
js="var q=document.documentElement.scrollTop=10000" driver.execute_script(js)
3、滚动条拉到指定位置(具体元素):--最常用
target = driver.find_element_by_id("id_keypair") driver.execute_script("arguments[0].scrollIntoView();", target)
4、通过模拟键盘DOWN(↓)来拖动:
driver.find_element_by_id("id").send_keys(Keys.DOWN)
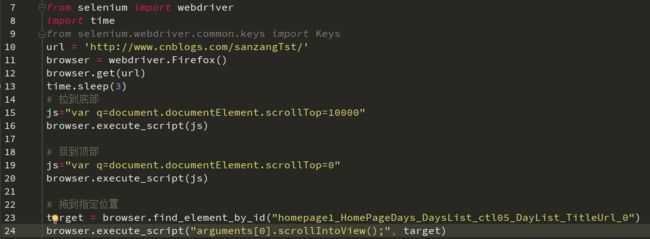
5、scrollTo函数
--scrollHeight 获取对象的滚动高度。
--scrollLeft 设置或获取位于对象左边界和窗口中目前可见内容的最左端之间的距离。
--scrollTop 设置或获取位于对象最顶端和窗口中可见内容的最顶端之间的距离。
--scrollWidth 获取对象的滚动宽度。
#滚动到底部
js = "window.scrollTo(0,document.body.scrollHeight)" driver.execute_script(js)
#滚动到顶部
js = "window.scrollTo(0,0)" driver.execute_script(js)

二、参考代码
#!/usr/bin/env python # -*- coding: utf-8 -*- # @File : jss.py # @Software: PyCharm from selenium import webdriver import time from selenium.webdriver.common.keys import Keys url = 'http://www.cnblogs.com/sanzangTst/' browser = webdriver.Firefox() browser.get(url) time.sleep(3) # 拉到底部 js="var q=document.documentElement.scrollTop=10000" browser.execute_script(js) # 回到顶部 js="var q=document.documentElement.scrollTop=0" browser.execute_script(js) # 拖到指定位置 target = browser.find_element_by_id("homepage1_HomePageDays_DaysList_ctl05_DayList_TitleUrl_0") browser.execute_script("arguments[0].scrollIntoView();", target) #滚动到底部 js = "window.scrollTo(0,document.body.scrollHeight)" browser.execute_script(js) #滚动到顶部 js = "window.scrollTo(0,0)" browser.execute_script(js)
当然,JavaScript的作用不仅仅体现在浏览器滚动条的操作上,还可以用它向页面中textarea文本框输入内容。
...... ......
虽然我们可以通过id的方式将其进行定位,但却不能通过send_keys()向文本框中输入文本信息。这种情况下,就需要借助JavaScript代码完成输入。
......
text = "input text"
js = "var sum=document.getElementById("id"); sum.value = '" + text + "';"
driver.execute_script(js)
......
首先定义了要输入的内容text,然后将text与JavaScript代码通过 “+” 进行拼接。这样做的目的是为了使输入内容变得可自定义。最后,通过execute_script()执行JavaScript代码。
2.16 处理HTML5的视频播放
目前 HTML5 技术已渐渐成为主流,主流的浏览器都已支持 HTML5。越来越多的应用使用了 HTML5 的元素,如canvas、video等,另外网页存储功能更增加了用户的网络体验,使得越来越多的开发者在使用这样的标准,所以我们也需要学习如何使用自动化技术来测试它们。
WebDriver 支持在指定的浏览器上测试 HTML5,另外,我们还可以使用 JavaScript 来测试这些功能,这样就可以在任何浏览器上测试HTML5了。
大多数浏览器使用控件(如Flash)来播放视频,但是,不同的浏览器需要使用不同的插件。HTML5定义了一个新的元素
from selenium import webdriver from time import sleep driver = webdriver.Firefox() driver.get("http://videojs.com/") video = driver.find_element_by_xpath("body/Setion[1]/div/video") # 返回播放文件地址 url = driver.execute_script("return arguments[0].currentSrc;",video) print(url) # 播放视频 print("start") driver.execute_script("return arguments[0].play()",video) # 播放15秒钟 sleep(15) # 暂停视频 print("stop") driver.execute_script("arguments[0].pause()",video) driver.quit()
JavaScript 函数有个内置的对象叫做 arguments。arguments对象包含了函数调用的参数数组,[0]表示取对象的第1个值。
currentSrc 熟悉返回当前音频 / 视频的URL。如果未设置音频 / 视频,则返回空字符串。
load() 、play() 、pause() 、等控制着视频的加载、播放和暂停。
2.17 窗口截图
自动化用例是由程序去执行的,因此有时候打印的错误信息并不十分明确。如果在脚本执行出错的时候能对当前窗口截图保存,那么通过图片就可以非常直观地看出出错的原因。WebDriver提供了截图函数 get_screenshot_as_file() 来截取当前窗口。
driver = webdriver.Firefox() driver.get("http://www.baidu.com") driver.find_element_by_id("kw").send_keys("selenium") driver.find_element_by_id("su").click() sleep(2) # 截图当前窗口,并制定截图图片的保存位置 driver.get_screenshot_as_file("D:\\pyse\\baidu_img.png") # png格式 driver.quit()
2.18 关闭窗口
在前面的例子中我们一直使用 quit() 方法,其含义为退出相关的驱动程序和关闭所有窗口。除此之外,WebDriver还提供了close()方法,用来关闭当前窗口。在用例执行的过程中打开了多个窗口,我们想要关闭其中的某个窗口,这时就要用到 close() 方法进行关闭了。
2.19 验证码的处理
对于Web应用来说,大部分的系统在用户登录时都要求用户输入验证码。验证码的类型很多,有字母数字的,有汉字的,甚至还有需要用户输入一道算术题的答案的。对于系统来说,使用验证码可以有效地防止采用机器猜测方法对口令的刺探,在一定程度上增加了安全性。
但对测试人员来说,不管是进行性能测试还是自动化测试,都是一个比较棘手的问题。在WebDriver中并没有提供相应的方法来处理验证码,这里有几种处理验证码的常见方法。
1. 去掉验证码
这是最简单的方法,对于看法人员来说,只是把验证码的相关代码注释掉即可。如果是在测试环境,这样做可省去测试人员不少的麻烦;但如果自动化脚本是在正是环境测试,那么这种做法就给系统带来了一定的风险。
2. 设置万能验证码
去掉验证码的主要问题是安全,为了应对在线系统的安全威胁,可以在修改程序时不取消验证码,而是在程序中留一个“后门”,即设置一个“万能验证码”。只要用户输入这个“万能验证码”,程序就认为验证通过,否则就判断用户输入的验证码是否正确。
设计万能验证码的方式非常简单,只需对用户的输入信息多加一个逻辑判断。
3. 验证码识别技术
例如,可以通过Python-tesseract 来识别图片验证码。Python-tesseract是光学字符识别 Tesseract OCR 引擎的Python封装类,能够读取任何常规的图片文件(JPG/GIF/PNG/TIFF等)。不过,目前市面上的验证码形式繁多,大多验证码识别技术,识别率都很难达到100%。
4. 记录cookie
通过向浏览器中添加cookie可以绕过登录的验证码,这是比较有意思的一种解决方案。例如我们在第一次登录某网站时勾选“记住密码”的选项,当下次再访问该网站时自动就处于登陆状态了。这样自然就绕过了验证码问题。这个“记住密码”功能其实就记录在了浏览器的cookie中。前面已经学了通过WebDriver来操作浏览器的cookie,可以通过add_cookie() 方法将用户名密码写入浏览器cookie,当再次访问网站时,服务器将直接读取浏览器的cookie进行登录。
......
# 访问 xx 网站
driver.get("http://www.xx.cn")
# 将用户名密码写入浏览器 cookie
driver.add_cookie({"name":"Login_UserNumber","value":"username"})
driver.add_cookie({"name":"Login_Passwd","value":"password"})
# 再次访问xx网站,将会自动登录
driver.get("http://www.xx.cn/")
#......
driver.quit()
这种方式最大的问题是如何从浏览器的 cookie 中找到用户名和密码对应的 key 值,并传入对应的登录信息。可以用 get_cookies()方法来获取登录的所有的cookie信息,从中找到用户名和密码的key。当然,更直接的方式是询问开发人员。
4.20 WebDriver 原理
WebDriver 是按照 Server - Client 的经典设计模式设计的。
Server 端就是 Remote Server,可以是任意的浏览器。当我们的脚本启动浏览器后,该浏览器就是Remote Server,它的职业就是等待 Client 发送请求并作出响应。
Client 端简单说来就是我们的测试代码。我们测试代码中的一些行为,例如打开浏览器,转跳到特定的 URL 等操作是以 http 请求的方式发送给被测试浏览器的,也就是 Remote Server。Remote Server。Remote Server 接受请求,执行相应操作,并在 Response 中返回执行状态,返回值等信息。
WebDriver 的工作流程:
- WebDriver 启动目标浏览器,并绑定到指定端口。启动的浏览器实例将作为 WebDriver 的 Remote Server。
- Client 端通过 CommandExcuter 发送 HTTPRequest 给Remote Server 的侦听端口(通信协议:the webdriver wire protocol)
- Remote Server 需要依赖原生的浏览器组件(如IEDriverServer.exe、chromedriver.exe)来转化浏览器的 native 调用。
Python 提供了logging 模块给运行中的应用提供了一个标准的信息输出接口。它提供了basicConfig() 方法用于基本信息的定义。开启 debug 模块,就可以捕捉到客户端向服务端发送的请求。
from selenium import webdriver import logging logging.basicConfig(level = logging.DEBUG) driver = webdriver.Firefox() driver.get("http://www.baidu.com") driver.find_element_by_id("kw").send_keys("selenium") driver.find_element_by_id("su").click() driver.quit() >>> C:\Users\Administrator\AppData\Local\Programs\Python\Python37\python.exe C:/Users/Administrator/Desktop/py/test.py DEBUG:selenium.webdriver.remote.remote_connection:POST http://127.0.0.1:3633/session {"capabilities": {"firstMatch": [{}], "alwaysMatch": {"browserName": "firefox", "acceptInsecureCerts": true}}, "desiredCapabilities": {"browserName": "firefox", "acceptInsecureCerts": true, "marionette": true}} DEBUG:selenium.webdriver.remote.remote_connection:b'{"value": {"sessionId":"84ddc3fe-d7af-4d2e-a5bb-a7408100b3aa","capabilities":{"acceptInsecureCerts":true,"browserName":"firefox","browserVersion":"61.0","moz:accessibilityChecks":false,"moz:headless":false,"moz:processID":18244,"moz:profile":"C:\\\\Users\\\\Administrator\\\\AppData\\\\Local\\\\Temp\\\\rust_mozprofile.OvsTh3aeSztY","moz:useNonSpecCompliantPointerOrigin":false,"moz:webdriverClick":true,"pageLoadStrategy":"normal","platformName":"windows_nt","platformVersion":"10.0","rotatable":false,"timeouts":{"implicit":0,"pageLoad":300000,"script":30000}}}}' DEBUG:selenium.webdriver.remote.remote_connection:Finished Request DEBUG:selenium.webdriver.remote.remote_connection:POST http://127.0.0.1:3633/session/84ddc3fe-d7af-4d2e-a5bb-a7408100b3aa/url {"url": "http://www.baidu.com"} DEBUG:selenium.webdriver.remote.remote_connection:b'{"value": null}' DEBUG:selenium.webdriver.remote.remote_connection:Finished Request DEBUG:selenium.webdriver.remote.remote_connection:POST http://127.0.0.1:3633/session/84ddc3fe-d7af-4d2e-a5bb-a7408100b3aa/element {"using": "css selector", "value": "[id=\"kw\"]"} DEBUG:selenium.webdriver.remote.remote_connection:b'{"value":{"element-6066-11e4-a52e-4f735466cecf":"2f5d6f4b-81aa-425f-9a12-9b6b1b81c602"}}' DEBUG:selenium.webdriver.remote.remote_connection:Finished Request DEBUG:selenium.webdriver.remote.remote_connection:POST http://127.0.0.1:3633/session/84ddc3fe-d7af-4d2e-a5bb-a7408100b3aa/element/2f5d6f4b-81aa-425f-9a12-9b6b1b81c602/value {"text": "selenium", "value": ["s", "e", "l", "e", "n", "i", "u", "m"], "id": "2f5d6f4b-81aa-425f-9a12-9b6b1b81c602"} DEBUG:selenium.webdriver.remote.remote_connection:b'{"value": null}' DEBUG:selenium.webdriver.remote.remote_connection:Finished Request DEBUG:selenium.webdriver.remote.remote_connection:POST http://127.0.0.1:3633/session/84ddc3fe-d7af-4d2e-a5bb-a7408100b3aa/element {"using": "css selector", "value": "[id=\"su\"]"} DEBUG:selenium.webdriver.remote.remote_connection:b'{"value":{"element-6066-11e4-a52e-4f735466cecf":"d1ec924a-2bfa-4739-b3a0-e3f721319bee"}}' DEBUG:selenium.webdriver.remote.remote_connection:Finished Request DEBUG:selenium.webdriver.remote.remote_connection:POST http://127.0.0.1:3633/session/84ddc3fe-d7af-4d2e-a5bb-a7408100b3aa/element/d1ec924a-2bfa-4739-b3a0-e3f721319bee/click {"id": "d1ec924a-2bfa-4739-b3a0-e3f721319bee"} DEBUG:selenium.webdriver.remote.remote_connection:b'{"value": null}' DEBUG:selenium.webdriver.remote.remote_connection:Finished Request DEBUG:selenium.webdriver.remote.remote_connection:DELETE http://127.0.0.1:3633/session/84ddc3fe-d7af-4d2e-a5bb-a7408100b3aa {} DEBUG:selenium.webdriver.remote.remote_connection:b'{"value": null}' DEBUG:selenium.webdriver.remote.remote_connection:Finished Request Process finished with exit code 0
basicConfig 所捕捉的log信息。不过basicConfig()开启的debug模式只能捕捉到客户端向服务器发送的 POST 请求,而无法获取服务器所返回的应答信息。Selenium Server 可以获取到更详细的请求与应答信息。
可参考别人的博客:Selenium-WebDriverApi接口详解
转载于:https://www.cnblogs.com/dongye95/p/10834639.html