NLP(Natural Language Processing),也就是人们常说的「自然语言处理」,就是研究如何让计算机读懂人类语言。
其用于有如下的
从「中文分词」、「词云画像」、「词性分析」到「自动摘要」、「关系挖掘」、「情感分析」、「知识图谱」等
开源的NLP库
Apache OpenNLP:一种机器学习工具包,提供标记器,句子分段,词性标注,命名实体提取,分块,解析,共参考解析等等。
自然语言工具包(NLTK):提供用于处理文本,分类,标记化,词法分析,标记,解析等模块的Python库。
斯坦福的NLP:一套NLP工具,提供词性标注,命名实体识别器,共识解析系统,情感分析等等。
word2vec的大概流程如下:
- 分词 / 词干提取和词形还原。 中文和英文的nlp各有各的难点,中文的难点在于需要进行分词,将一个个句子分解成一个单词数组。而英文虽然不需要分词,但是要处理各种各样的时态,所以要进行词干提取和词形还原。
(2) 构造词典,统计词频。这一步需要遍历一遍所有文本,找出所有出现过的词,并统计各词的出现频率。
(3) 构造树形结构。依照出现概率构造Huffman树。如果是完全二叉树,则简单很多,后面会仔细解释。需要注意的是,所有分类都应该处于叶节点,像下图显示的那样[4]
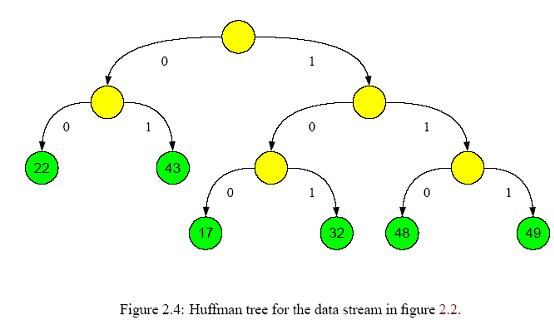
(4)生成节点所在的二进制码。拿上图举例,22对应的二进制码为00,而17对应的是100。也就是说,这个二进制码反映了节点在树中的位置,就像门牌号一样,能按照编码从根节点一步步找到对应的叶节点。
(5) 初始化各非叶节点的中间向量和叶节点中的词向量。树中的各个节点,都存储着一个长为m的向量,但叶节点和非叶结点中的向量的含义不同。叶节点中存储的是各词的词向量,是作为神经网络的输入的。而非叶结点中存储的是中间向量,对应于神经网络中隐含层的参数,与输入一起决定分类结果。
(6) 训练中间向量和词向量。对于CBOW模型,首先将词A附近的n-1个词的词向量相加作为系统的输入,并且按照词A在步骤4中生成的二进制码,一步步的进行分类并按照分类结果训练中间向量和词向量。举个栗子,对于绿17节点,我们已经知道其二进制码是100。那么在第一个中间节点应该将对应的输入分类到右边。如果分类到左边,则表明分类错误,需要对向量进行修正。第二个,第三个节点也是这样,以此类推,直到达到叶节点。因此对于单个单词来说,最多只会改动其路径上的节点的中间向量,而不会改动其他节点。
模型拆解
word2vec模型其实就是简单化的神经网络。
一般来讲,词向量主要有两种形式,分别是稀疏向量和密集向量。

稀疏向量
在word2vec出现之前,自然语言处理经常把字词转为离散的单独的符号,也就是One-Hot Encoder。[稀疏向量]
杭州 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
上海 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
比如上面的这个例子,在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。但是使用One-Hot Encoder有以下问题。一方面,城市编码是随机的,向量之间相互独立,看不出城市之间可能存在的关联关系。其次,向量维度的大小取决于语料库中字词的多少。如果将世界所有城市名称对应的向量合为一个矩阵的话,那这个矩阵过于稀疏,并且会造成维度灾难。
密集向量
至于密集向量,又称distributed representation,即分布式表示。最早由Hinton提出,可以克服one-hot representation的上述缺点,基本思路是通过训练将每个词映射成一个固定长度的短向量,所有这些向量就构成一个词向量空间,每一个向量可视为该空间上的一个点[1]。此时向量长度可以自由选择,与词典规模无关。这是非常大的优势。还是用之前的例子[“面条”,”方便面”,”狮子”],经过训练后,“面条”对应的向量可能是[1,0,1,1,0],而“方便面”对应的可能是[1,0,1,0,0],而“狮子”对应的可能是[0,1,0,0,1]。这样“面条”向量乘“方便面”=2,而“面条”向量乘“狮子”=0 。这样就体现出面条与方便面之间的关系更加紧密,而与狮子就没什么关系了。这种表示方式更精准的表现出近义词之间的关系,比之稀疏向量优势很明显。可以说这是深度学习在NLP领域的第一个运用(虽然我觉得并没深到哪里去)
回过头来看word2vec,其实word2vec做的事情很简单,大致来说,就是构建了一个多层神经网络,然后在给定文本中获取对应的输入和输出,在训练过程中不断修正神经网络中的参数,最后得到词向量。
稀疏向量到密集向量 采用神经网络模型。
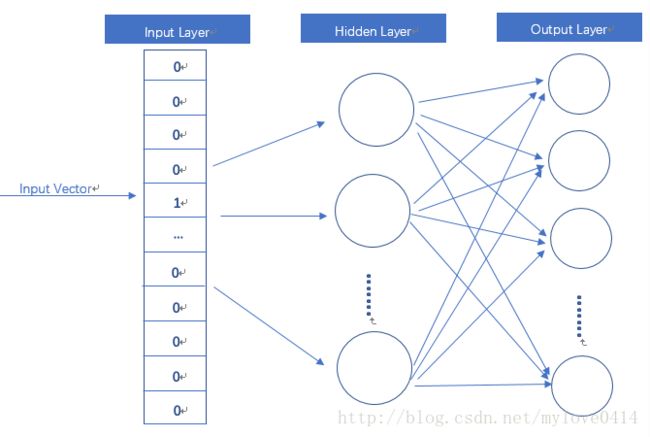
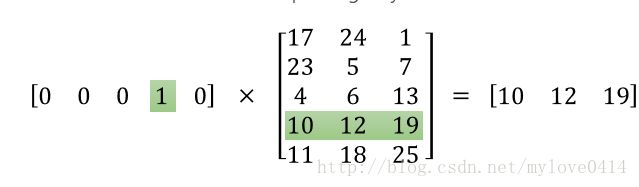
输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。我们要获取的dense vector其实就是Hidden Layer的输出单元。有的地方定为Input Layer和Hidden Layer之间的权重,其实说的是一回事。
word2vec的2种模式
word2vec的语言模型
所谓的语言模型,就是指对自然语言进行假设和建模,使得能够用计算机能够理解的方式来表达自然语言。word2vec采用的是n元语法模型(n-gram model),即假设一个词只与周围n个词有关,而与文本中的其他词无关。这种模型构建简单直接,当然也有后续的各种平滑方法[2],这里就不展开了。
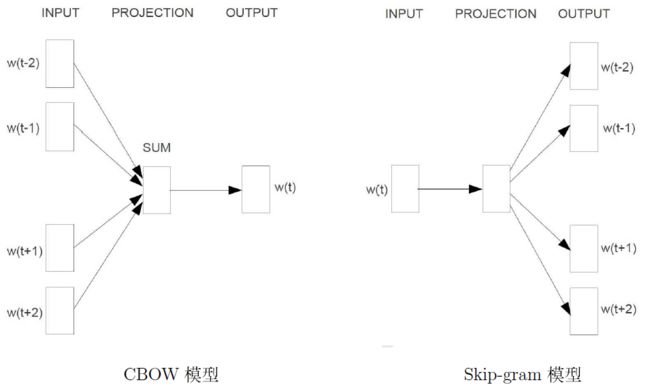
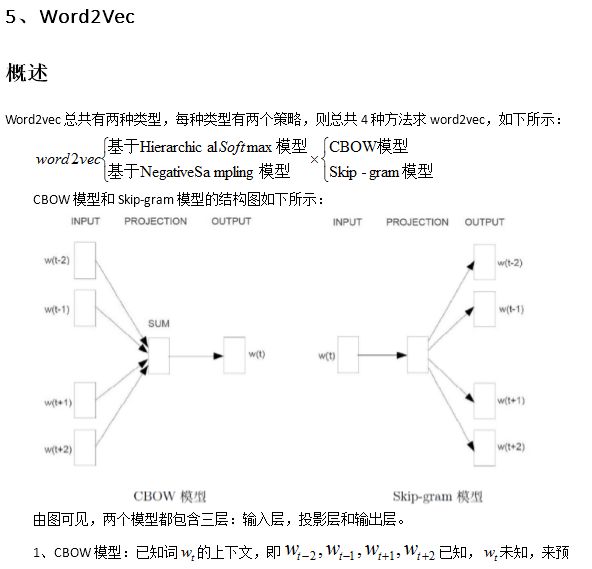
CBOW与Skip-Gram模式
word2vec主要分为CBOW(Continuous Bag of Words)和Skip-Gram两种模式。CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
对同样一个句子:Hangzhou is a nice city。我们要构造一个语境与目标词汇的映射关系,其实就是input与label的关系。
这里假设滑窗尺寸为1(滑窗尺寸……这个……不懂自己google吧-_-|||)
CBOW可以制造的映射关系为:[Hangzhou,a]—>is,[is,nice]—>a,[a,city]—>nice
Skip-Gram可以制造的映射关系为(is,Hangzhou),(is,a),(a,is), (a,nice),(nice,a),(nice,city)
word2vec也使用了CBOW与Skip-Gram来训练模型与得到词向量,但是并没有使用传统的DNN模型。最先优化使用的数据结构是用霍夫曼树来代替隐藏层和输出层的神经元,霍夫曼树的叶子节点起到输出层神经元的作用,叶子节点的个数即为词汇表的小大。 而内部节点则起到隐藏层神经元的作用。
在word2vec出现之前,已经有用神经网络DNN来用训练词向量进而处理词与词之间的关系了。采用的方法一般是一个三层的神经网络结构(当然也可以多层),分为输入层,隐藏层和输出层(softmax层)。
这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。
CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。比如下面这段话,我们的上下文大小取值为4,特定的这个词是"Learning",也就是我们需要的输出词向量,上下文对应的词有8个,前后各4个,这8个词是我们模型的输入。由于CBOW使用的是词袋模型,因此这8个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。
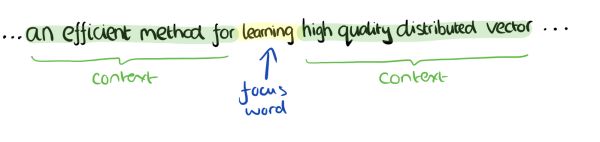
这样我们这个CBOW的例子里,我们的输入是8个词向量,输出是所有词的softmax概率(训练的目标是期望训练样本特定词对应的softmax概率最大),对应的CBOW神经网络模型输入层有8个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某8个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可。
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。还是上面的例子,我们的上下文大小取值为4, 特定的这个词"Learning"是我们的输入,而这8个上下文词是我们的输出。
这样我们这个Skip-Gram的例子里,我们的输入是特定词, 输出是softmax概率排前8的8个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。这样当我们有新的需求,要求出某1个词对应的最可能的8个上下文词时,我们可以通过一次DNN前向传播算法得到概率大小排前8的softmax概率对应的神经元所对应的词即可。
以上就是神经网络语言模型中如何用CBOW与Skip-Gram来训练模型与得到词向量的大概过程。但是这和word2vec中用CBOW与Skip-Gram来训练模型与得到词向量的过程有很多的不同。

训练优化
额,到这里,你可能会注意到,这个训练过程的参数规模非常巨大。假设语料库中有30000个不同的单词,hidden layer取128,word2vec两个权值矩阵维度都是[30000,128],在使用SGD对庞大的神经网络进行学习时,将是十分缓慢的。而且,你需要大量的训练数据来调整许多权重,避免过度拟合。数以百万计的重量数十亿倍的训练样本意味着训练这个模型将是一个野兽。
一般来说,有Hierarchical Softmax、Negative Sampling等方式来解决。
github上的相关东西。
Angel
Word2Vec
Word2Vec概述与基于Hierarchical Softmax的CBOW和Skip-gram模型公式推导