乱序字典加密解密&python基础知识综合应用
目标
-
找一段比较长的文本(文本是以.txt文件形式存在的)
NOTE:频率法适用于较大样本 -
打开文件,读取字符形成字符串( python文件函数)
处理成只包含小写字母的字符串 (用re的函数) -
统计这段字符串中的字母频率
-
将这个频率和自己查找到的频率表对照,看看差异。
-
乱序法加密这个字符串,用标准频率表中的对应次序来解密。
一般都会得到若干个正确单词,但完全碰对的可能性不大。 -
输出解密文件
找一段比较长的文本
从global times环球时报上摘取了一个报道
文件处理
由于是字符操作,字符串属于不可变对象,因此返回新的对象
dat = open('EnglishSample.txt','r')
sample = dat.read()
dat.close()
sample = sample.lower()#lower 方法返回的是一个新的字符串
sample = re.sub('[\W\d]+','',sample)
#将第一个模式替换为第二种字符串,作用在第三个变量
#同样返回一个新的字符串
清洗后不含有空格并且没有大写字母
字母频率统计&频率表
def frequencyDict(sample):
rDict = {}
strlen = len(sample)
for i in sample:
if i in rDict:
rDict[i] += 100.0/strlen#百分制词频
else:
rDict[i] = 1.0/strlen
return rDict
另一种统计方法(直接使用字符串内置方法count)
for i in alpha:
v3.append(100.0*secret.count(i)/len(secret))#统计加密后词频
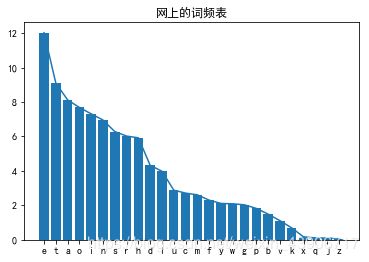
在某个网站找了频率表
然后手动录入
stdDict = {'e':12.02,'t':9.10,'a':8.12,'o':7.68,'i':7.31,'n':6.95,'s':6.28,
'r':6.02,'h':5.92,'d':4.32,'l':3.98,'u':2.88,'c':2.71,'m':2.61,
'f':2.30,'y':2.11,'w':2.09,'g':2.03,'p':1.82,'b':1.49,'v':1.11,
'k':0.69,'x':0.17,'q':0.11,'j':0.10,'z':0.07}
图表展示
一个尴尬的展示方法
如果按照值排列,就会看不明白字符顺序
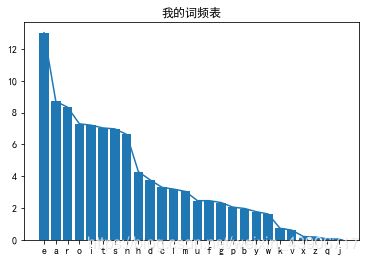
改良之后
采用字母表正常顺序,观察词频的差异
虽然图片依旧比较丑,但是可以观察到词频区别
红色为网上查到的词频
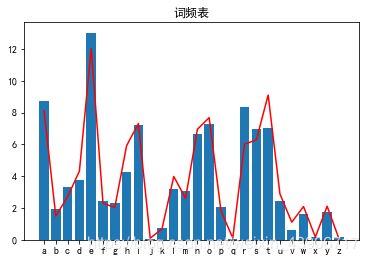
plt.rcParams['font.sans-serif']=['SimHei']
plt.title('词频表红线是网络版')
plt.plot(k1,v1,'r')
plt.bar(k1,v2)
plt.show()
加密
根据字典加密(同理可以解密)
def transfer(instr, code):
temp = []
for i in range(len(instr)):
temp.append(code[instr[i]])
outstr = ''.join(temp)
return outstr
另外为了便于排序字典(我也不知道为什么当初要研究这个)
我研究了一下sort方法和lambda表达式
将字典转换为键值对列表
sort方法
匿名函数
可以选择按照键排序或者按照值排序,返回排好的键&值两个列表
def sortDict(rDict,k,v,key=0):
raw = list(rDict.items())
raw.sort(key = lambda d:d[key])
for i in raw:
k.append(i[0])
v.append(i[1])
解密结果
Bent over a barrel, Greek microbrewer Sophocles Panagiotou lovingly draws a measure of his Septem Red Ale into a glass cylinder and expertly transfers it to a glass.
……
gernokeatgtaaeuyaeevcilaogaebeasowholueswtrtyionomuokiryupdatbs
……
惨不忍睹
总结
- 写代码之前一定先策划好变量与函数(即使python很重要的是使用库函数)
- 代码重用非常重要,不要出现复制粘贴的想法(两个函数有共同功能要再分拆)
- 变量名要不仅有代表性,而且要先策划,否则一堆encodeXX的变量名还是看不明白
- 破窗效应,如果有一段很烂的代码,会导致心态爆炸胡写下去,所以开始不要写的乱
- python编程中遇到的问题往往是有可以满足需求的函数,但是数据类型不是很方便,所以写起来总是有削足适履的感觉