GitHub项目地址:
GitHub - KennyH33/sudoku
任务:
实现一个能够生成数独终局并且能求解数独问题的控制台程序
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| Estimate | 估计这个任务需要多少时间 | 3600 | 2670 |
| Development | 开发 | 1200 | 800 |
| Analysis | 需求分析(包括学习新技术) | 600 | 400 |
| Design Spec | 生成设计文档 | 100 | 180 |
| Design Review | 设计复审(和同事审核设计文档) | 60 | 30 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 60 | 40 |
| Design | 具体设计 | 200 | 120 |
| Coding | 具体编码 | 600 | 600 |
| Code Review | 代码复审 | 60 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 360 | 240 |
| Reporting | 报告 | 60 | 60 |
| Test Report | 测试报告 | 30 | 20 |
| Size Measurement | 计算工作量 | 15 | 10 |
| Postmortem&Process Improvement Plan | 事后总结,并提出过程改进计划 | 120 | 100 |
需求分析:
实现一个命令行程序,程序能:
1.生成不重复的数独终局至文件
2.读取文件内的数独问题,求解并将结果输出至文件
生成终局
1.在命令行中使用-c参数加数字N(1<=N<=1000000)控制生成数独终局的数量,例如下述命令将生成20个数独终局至文件中:
sudoku.exe -c 20
2.将生成的数独终局用一个文本文件(假设名字叫做sudoku.txt)的形式保存起来,每次生成的txt文件需要覆盖上次生成的txt文件,文件内的格式如下,数与数之间由空格分开,终局与终局之间空一行,行末无空格。
9 5 8 3 6 7 1 2 4
2 3 7 4 5 1 9 6 8
1 4 6 9 2 8 3 5 7
6 1 2 8 7 4 5 9 3
5 7 3 6 1 9 4 8 2
4 8 9 2 3 5 6 7 1
7 2 4 5 9 3 8 1 6
8 9 1 7 4 6 2 3 5
3 6 5 1 8 2 7 4 9
···
3.程序在处理命令行参数时,不仅能处理正确的参数,还能够处理各种异常的情况,如:
sudoku.exe -c abc
4.在生成数独矩阵时,左上角的第一个数为:(学号后两位相加)%9+1.例如学生A学号后两位是01,则该数字是(0+1)%9+1=2,那么生成的数独棋盘应如下(x表示满足数独规则的任意数字):
2 x x x x x x x x
x x x x x x x x x
x x x x x x x x x
x x x x x x x x x
x x x x x x x x x
x x x x x x x x x
x x x x x x x x x
x x x x x x x x x
求解数独
1.在命令行中使用-s参数加文件名的形式求解数独,并将结果输出至文件,如:
sudoku.exe -s absolute_path_of_puzzlefile
2.格式如下,其中0代表空格,题目与题目之间空一行,行来无空格,最后一个数独题目后无空行:
9 5 0 3 6 7 0 2 0
2 0 7 0 5 0 9 6 0
0 0 6 9 2 8 3 5 0
6 1 0 8 7 4 5 9 3
5 0 3 0 1 9 0 8 2
4 8 0 0 3 5 6 7 1
7 2 4 5 9 0 8 1 0
8 0 0 7 4 6 2 3 0
3 6 5 1 8 2 7 4 9
···
3.sudoku.txt的格式如下(与生成终局的要求相同):
9 5 8 3 6 7 1 2 4
2 3 7 4 5 1 9 6 8
1 4 6 9 2 8 3 5 7
6 1 2 8 7 4 5 9 3
5 7 3 6 1 9 4 8 2
4 8 9 2 3 5 6 7 1
7 2 4 5 9 3 8 1 6
8 9 1 7 4 6 2 3 5
3 6 5 1 8 2 7 4 9
···
4.数独题目个数N(1<=N<=1000000),以保证文件中数独格式正确。
功能建模:
这里使用DFD进行面向数据流建模
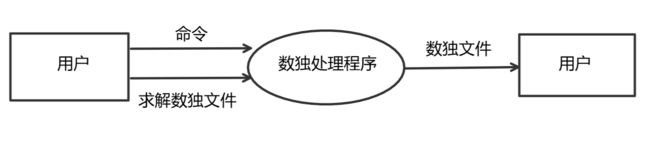
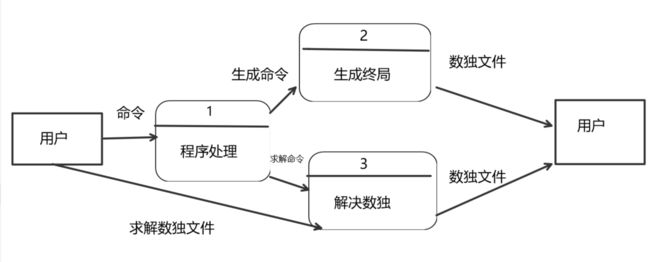
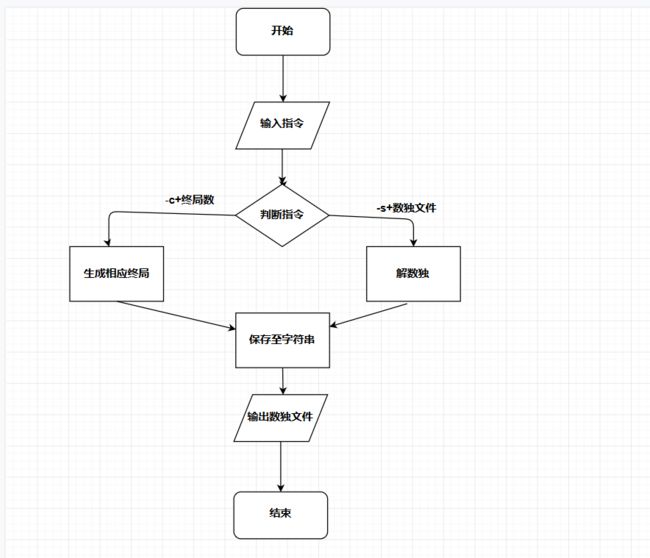
程序流程图
类图:
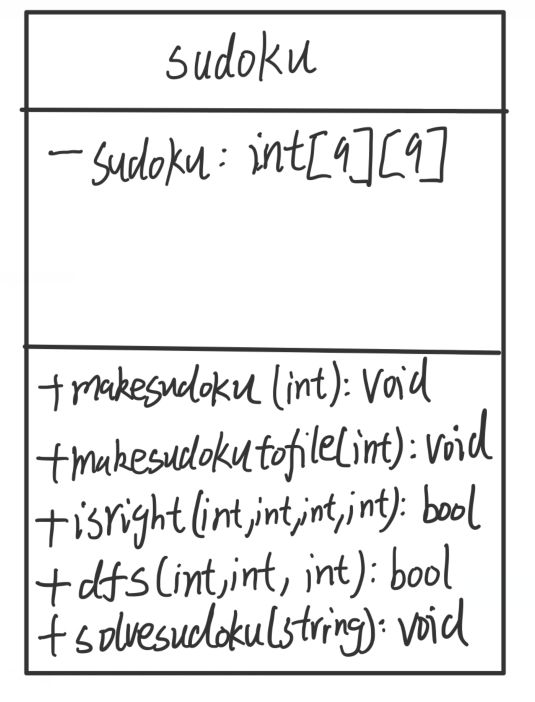
其中Private里仅有一个二维数组sudoku,用于存放单个9*9矩阵。
Public内有五个函数,makesudoku用于生成数独终局,makesudokutofile用于生成sudoku.txt文件,solvesudoku用于求解数独,因为用的是深度优先搜索算法,所以子函数是dfs,过程中需要判断数字填进去是否正确,所以需要用到判断函数isright。
| 函数名称 | 函数类型 | 函数参数 | 参数意义 | 函数作用 |
|---|---|---|---|---|
| makesudoku | void | int num | num指9*9矩阵个数 | 生成终局 |
| makesudokutofile | void | int num | num指9*9矩阵个数 | 写入数独文件 |
| isright | bool | int k,int row, int column,int num | k指当前填的空所在的矩阵数,row是行,column是列,num是要填入的数字 | 判断是否能填入该数字 |
| dfs | bool | int k,int row,int column | k指当前矩阵数,row是行,column是列 | 用于填空 |
| solvesudoku | void | string filepath | filepath指待解决的文件路径 | 解决数独难题 |
解题思路:
生成终局
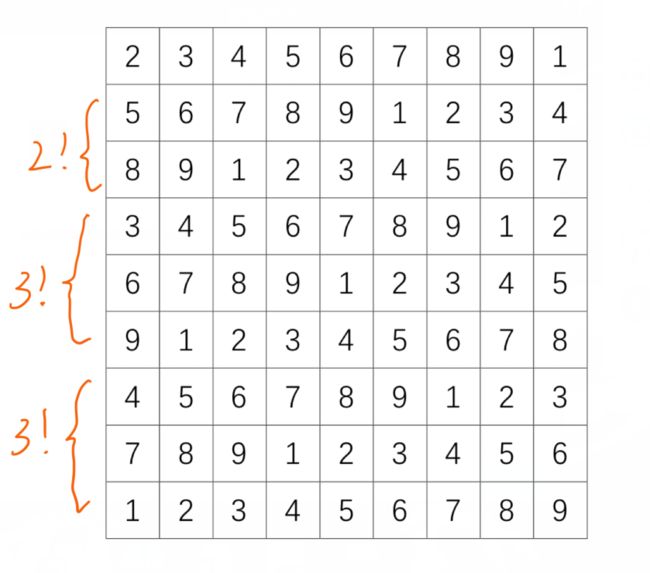
这里参考了xxrxxr的cnblogs软工博客,使用模板法生成终局,首先生成一个模板终局,因为学号后两位是01,所以第一个数字2不能动((0+1)%9+1=2),基本数独可以依靠第一行向左分别移动0,3,6,1,4,7,2,5,8位形成九行,也就是一个数独,而第一行的个数是除去2的8个数字的全排列,即8!=40320种,基本数独也是40320种,远远不足以达到题目中1000000的要求,这时候需要用到行列交换的方法,但是在这道题中,只需要交换行即可,因为第一个数字不能动,所以前三个3×3矩阵中只能第二行与第三行交换,也就是整个9×9的矩阵中的第二行与第三行互相交换,但是后面的数字没有要求,所以第4,5,6行可以进行互相交换,第7,8,9行可以进行互相交换,这样一种基本数独可以衍生出2!×3!×3!=72个数独,总个数也就是72*40320=2903040个,几乎是题目要求的3倍多,这样就达到了题目目的。
求解数独
看到题目要求之后我的想法是使用回溯法,即深度优先搜索,从第一个0开始,填入1-9中可以满足需求的数字,然后继续,如果遇到9个数字都无法填入的情况则返回上一个空位用别的数字代替,以此类推,最后能得到一个解好的数独。
具体代码实现
生成终局
先定义好以2开头的默认的第一行firstline数组,而初始数独是由第一行分别向左移动0,3,6,1,4,7,2,5,8位生成的,所以这里再定义数组initmove,再使用next_permutation全排列函数生成8!个数独。
int firstline[9]={2,3,4,5,6,7,8,9,1};//基本数独的第一行,第一个数位(0+1)%9+1=2
int initmove[9]={0,3,6,1,4,7,2,5,8};//分别向左移动0,3,6,1,4,7,2,5,8位
int swap[9]={0,1,2,3,4,5,6,7,8};//交换行和列所用的数组
do
{
for(i=0;i<9;i++)
{
for(j=0;j<9;j++)
{
sudoku[i][j]=firstline[(j+initmove[i])%9];//依靠第一行的移动生成基本数独,因为第一个数不能动,所以第一行的全排列共8!个
}
}
这里的swap数组用于第二第三行,第四五六行,第七八九行的行之间的交换
do
{
do
{
do
{
for(i=0;i<9;i++)
{
for(j=0;j<9;j++)
{
result[i+9*curnum][j]=sudoku[swap[i]][j];//第2,3行交换,第4,5,6行交换,第7,8,9行交换
}
}
curnum++;
if(curnum==num)
{
return;
}
}while(next_permutation(swap+1,swap+3));
}while(next_permutation(swap+3,swap+6));
}while(next_permutation(swap+6,swap+9));
}while(next_permutation(firstline+1,firstline+9));
求解数独
读取文件中的待解数独
ifstream ReadFile;
ReadFile.open(filepath.c_str());
if(ReadFile.is_open()==FALSE)
{
printf("读取数独文件失败,请检查你的文件路径是否正确\n");
}
while(!ReadFile.eof())
{
ReadFile>>inputsudoku[n];//读取文件中的字符
n++;
}
DFS过程:
int num;
if(column==9)
{
if(row==8)
{
return true; //搜索结束,条件是行是8,列是9
}
row++;//从下一行第一列开始
column=0;
}
if(result[k*9+row][column]!=0)
{
return dfs(k,row,column+1);//如果已经有数字就跳过
}
for(num=1;num<=9;num++)
{
if(isright(k,row,column,num)==true)
{
result[k*9+row][column]=num;//如果数字满足条件就先填上,再往后dfs
if(dfs(k,row,column+1))
{
return true;
}
}
}
result[k*9+row][column]=0;//如果无解
return false;
判断该数字是否有重复
int i,j;
for(i=0;i<9;i++)//判断列中有无相同数字
{
if(result[k*9+i][column]==num)
{
return false;
}
}
for(j=0;j<9;j++)//判断行中有无相同数字
{
if(result[k*9+row][j]==num)
{
return false;
}
}
for(i=row/3*3;i<=row/3*3+2;i++)//判断3*3矩阵中有无相同数字
{
for(j=column/3*3;j<=column/3*3+2;j++)
{
if(result[k*9+i][j]==num)
{
return false;
}
}
}
return true;
性能分析
改进前的版本
早期版本使用visual studio 2019自带的性能探查器做性能测试,发现与CMD执行的情况相比速度慢了太多太多,甚至导致生成1000000个数独的VSP文件太大(超过30G),我的C盘都没有足够空间,于是改为生成10000个数独,发现竟然需要20多秒。
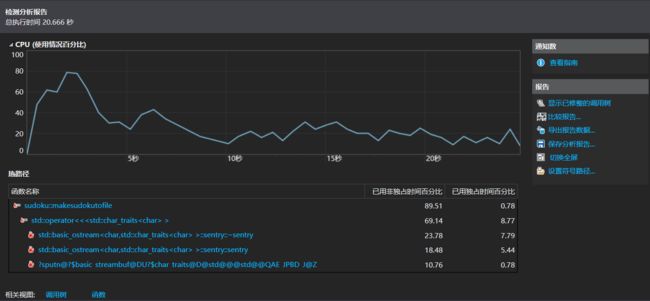
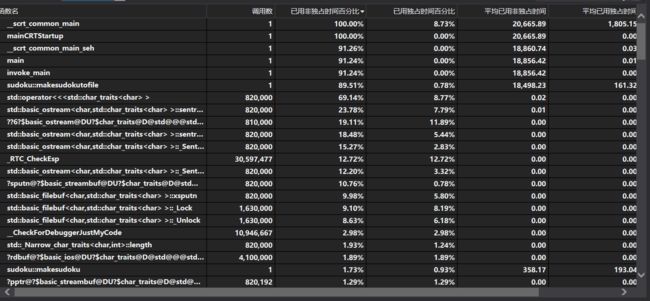
发现问题主要在写文件操作上(<<和ostream)占了太多的时间,于是我改进了写文件操作的部分代码,主要是将之前一个字符一个字符输出的方式改为存为一个char类型的大字符串将其输出,效果十分显著。
改进后的版本

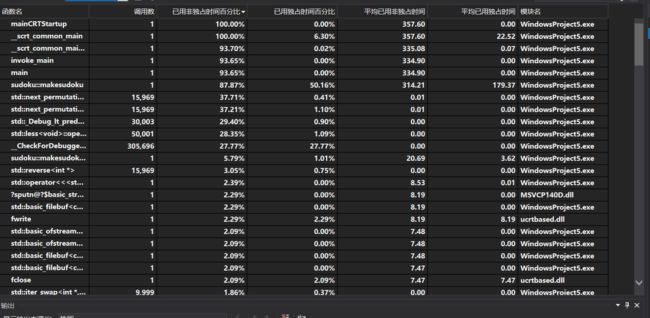
改进之后的程序生成10000个数独只需要0.358秒。
令新版本程序生成1000000个数独终局,结果如下
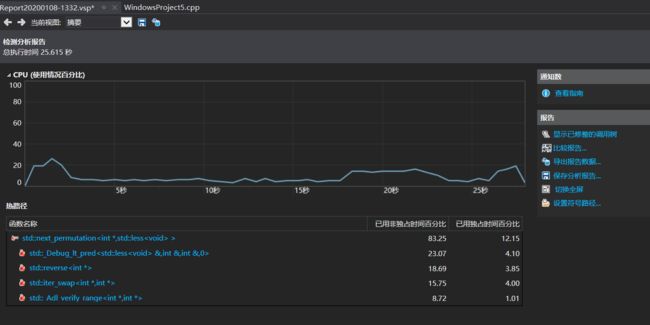

需要25秒的时间,还发现改进之后影响时间因素最重的是next_permutation全排列函数,它在生成终局时调用了相当多的次数。
代码质量分析

使用visual studio 2019自带的代码质量分析工具,结果显示无错误无警告。
心得体会
这次的大作业是我第一次运用软件工程的思想单独做一个程序项目。在之前的很多编程作业中我都是为了完成所需要的功能不顾运行时间,不顾性能需求,也没有封装类,而且都是使用dev-c来完成,但是这次的作业中需要运用面向对象的思想,需要尽量缩短程序运行时间,并且使用visual studio来做代码质量分析和性能测试改进的工作,尤其是dev-c安全性较差,所以有些语句需要在vs里再次修改才能正常运行。
而且这次作业要求更新博客和上传程序和代码到Github仓库,之前也只是在github上查看别人的程序,但是现在我更加熟悉了博客的写法(包括Markdown语句)和Github的使用。
当然不足还有很多,一个是性能改进后生成数独终局的程序运行时间依旧过长,一个是解数独的算法没有选择性能更好的算法,通过这次作业也清楚的认识到了自己在编程能力上的不足。以后还需要更加努力。
之前的文章更新:
2019年12月31日之前的博客更新
2020年1月4日的博客更新
2020年1月8日的博客更新
2020年1月15日的博客更新