python爬取网易云音乐
这几天学习了python爬虫后开始动手爬取网易云音乐(https://music.163.com/)。 点击自己想要爬取的歌单,右键审查元素,点击网络
点击自己想要爬取的歌单,右键审查元素,点击网络
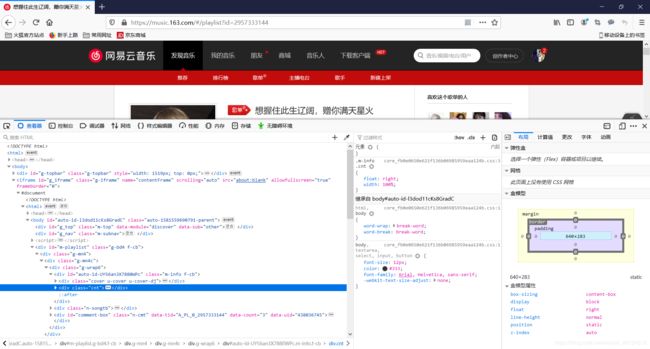
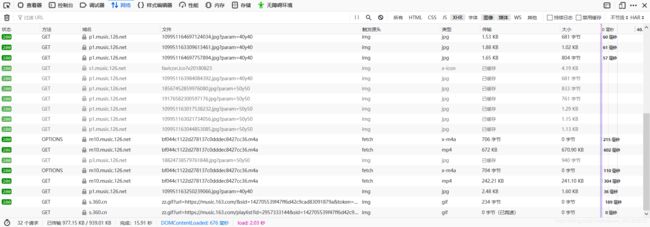 在此,状态码都是200表示通的。这里选择xhr,网易云是保存在xhr中,其他的网站有时直接在媒体中,F5刷新一下界面
在此,状态码都是200表示通的。这里选择xhr,网易云是保存在xhr中,其他的网站有时直接在媒体中,F5刷新一下界面
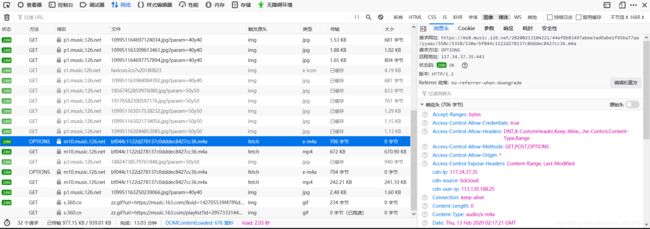
![]() 此时可以看到有一个.m4a结尾的。点击它,右侧的消息头中,出现的请求网址就是歌曲的真实网址。这个网址可以直接复制,在新的页面打开,就可以播放。
此时可以看到有一个.m4a结尾的。点击它,右侧的消息头中,出现的请求网址就是歌曲的真实网址。这个网址可以直接复制,在新的页面打开,就可以播放。
so am i
此时界面很简洁,点击右键可以保存歌曲。
使用python爬取整个歌单的歌曲才是真正解放生产力。
import requests
from lxml import etree
import re
headers = {
'Referer':'http://music.163.com/',
'Host':'music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
bass_url = 'http://link.hhtjim.com/163/'
url = 'https://music.163.com/playlist?id=481273627'
request = requests.get(url,headers=headers).text
dom = etree.HTML(request)
ids_songs = dom.xpath('//a[contains(@href,"song?")]/@href')
ids_names = dom.xpath('//a[contains(@href,"song?")]/text()')
for ids_name, ids_song in zip(ids_names, ids_songs):
count_id = ids_song.strip('/song?id=')
count_name = ids_name.strip('\/:*?"<>|')
if ('$' in count_id) == False:
print(count_id)
song_url = bass_url + '%s' % count_id + '.mp3'
mp3 = requests.get(song_url).content
print(count_name)
with open('E:\\PycharmProjects\wangyiyun./%s.mp3' % count_name, 'wb')as file:
file.write(mp3)
在写入文件名时。发现有一首歌曲叫“are you sure?”末尾带有问号。Windows系统文件命名规则中带?的为非法字符。此处需要去掉。count_name = ids_name.strip(’\ / : *?"<>|’)。或者用正则表达式。朋友还说能用base64编码来写。有兴趣的可以试试。