TF2.0深度学习实战(六):搭建GoogLeNet卷积神经网络
写在前面:大家好!我是【AI 菌】,一枚爱弹吉他的程序员。我
热爱AI、热爱分享、热爱开源! 这博客是我对学习的一点总结与记录。如果您也对深度学习、机器视觉、算法、Python、C++感兴趣,可以关注我的动态,我们一起学习,一起进步~
我的博客地址为:【AI 菌】的博客
我的Github项目地址是:【AI 菌】的Github
本教程会持续更新,如果对您有帮助的话,欢迎star收藏~
前言:
本专栏将分享我从零开始搭建神经网络的学习过程,注重理论与实战相结合,力争打造最易上手的小白教程。在这过程中,我将使用谷歌TensorFlow2.0框架逐一复现经典的卷积神经网络:LeNet、AlexNet、VGG系列、GooLeNet、ResNet 系列、DenseNet 系列,以及现在比较流行的:RCNN系列、SSD、YOLO系列等。
这一次我将复现非常经典的GooLeNet卷积神经网络。首先在理论部分,我会依据论文对GooLeNet进行一个简要的讲解。然后在实战部分,我会对自定义数据集进行加载、搭建GooLeNet网络、迭代训练,最终完成图片分类和识别任务。
系列教程:
深度学习环境搭建:Anaconda3+tensorflow2.0+PyCharm
TF2.0深度学习实战(一):分类问题之手写数字识别
TF2.0深度学习实战(二):用compile()和fit()快速搭建卷积神经网络
TF2.0深度学习实战(三):搭建LeNet-5卷积神经网络
TF2.0深度学习实战(四):搭建AlexNet卷积神经网络
TF2.0深度学习实战(五):搭建VGG系列卷积神经网络
资源传送门:
论文地址:《Going deeper with convolutions》
论文翻译:GoogLeNet 原文翻译:《Going deeper with convolutions》
github项目地址:【AI 菌】的Github
数据集下载:花分类数据集, 提取码:9ao5
文章目录
- 一、浅谈GoogLeNet
- 1.1 GoogLeNet 简介
- 1.2 GoogLeNet 的创新点
- 1.3 GoogLeNet 网络结构
- (1) Inception模块
- (2) 1x1卷积核降维
- (3) 辅助分类器
- (4) GoogLeNet整体结构
- 1.4 GoogLeNet 的性能
- 二、TensorFlow2.0搭建GoogLeNet实战
- 2.1 数据集准备
- (1) 数据集简介
- (2) 加载数据集
- 2.2 网络搭建
- (1) Inception模块
- (2) 辅助分类器InceptionAux
- (3) GooLeNet整体结构
- 2.3 模型的装配与训练
- 2.4 训练集/验证集上测试结果
- 2.5 加载模型,对单张图片预测
一、浅谈GoogLeNet
1.1 GoogLeNet 简介
GoogLeNet卷积神经网络出自于《Going deeper with convolutions》这篇论文,是由谷歌公司Christian Szegedy、Yangqing Jia等人联合发表。其研究成果在2014年 ILSVRC 挑战赛 ImageNet 分类任务上获得冠军,而当时的亚军就是上一篇文中讲到的VGG系列。
很有意思的是,GoogLeNet名字是由Google的前缀Goog与LeNet的组合而来,这其实是对Yann LeCuns开拓性的LeNet-5网络的致敬。
GoogLeNet卷积神经网络的最大贡献在于,提出了非常经典的Inception模块。该网络结构的最大特点是网络内部计算资源的利用率很高。因此该设计允许在保持计算资源预算不变的情况下增加网络的深度和宽度,使得GoogLeNet网络层数达到了更深的22层,但是网络参数仅为AlexNet的1/12。
1.2 GoogLeNet 的创新点
- 引入了非常经典的
Inception模块。 - 采用了
模块化设计的思想。通过大量堆叠Inception模块,形成了更深更复杂的网络结构。 - 采用了
大量的1×1卷积核。主要是用作降维以消除计算瓶颈。 - 在网络中间层设计了
两个辅助分类器。 - 采用
平均池化层替代了原来的全连接层,使得模型参数大大减少。
1.3 GoogLeNet 网络结构
GoogLeNet 网络结构较为复杂,我将分以下四个部分讲解:
- Inception模块
- 1x1卷积核降维
- 辅助分类器
- GoogLeNet整体结构
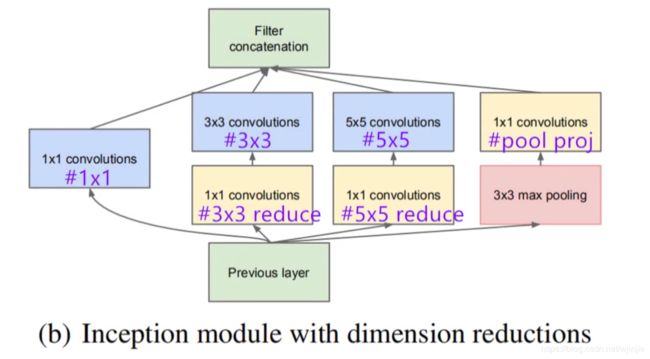
(1) Inception模块
在论文中,重点研究了名为Inception的高效的用于计算机视觉的深度神经网络结构,该结构的名称源自Lin等提出的论文《Network in Network》。在这种方法中,“深层”一词有两种不同的含义:首先,在某种意义上,我们以“Inception模块”的形式引入了新的组织层次,在更直接的意义上是网络深度的增加。Inception模块结构如下:
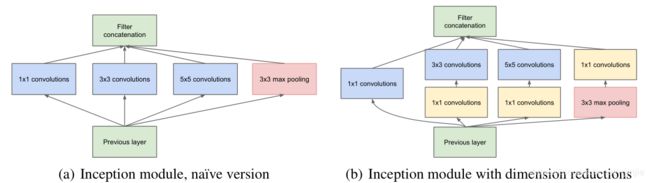
图(a)是原始的Inception模块结构。图(b)是改进后的Inception模块结构。
图(b)在(a)的基础上,在3×3和5×5的卷积核之前,添加1×1的卷积核来缩减计算量,实质上是一个降维的过程。
实验中最后采用的是图(b)所示的加入降维模块的Inception模块,因此这里以(b)为例进行讲解:
Inception模块的输入,通过4 个分支网络得到 4 个网络输出,在通道轴上面进行拼接,形成 Inception 模块的输出。这四个分支网络分别是:
- 1x1 卷积层,步长为1,padding=‘same’
- 1x1 卷积层,再通过一个 3x3 卷积层,步长为1,padding=‘same’
- 1x1 卷积层,再通过一个 5x5 卷积层,步长为1,padding=‘same’
- 3x3 最大池化城,再通过 1x1 卷积层,步长为1,padding=‘same’
Inception 模块的优点:
- 在每个3×3和5×5的卷积核之前,添加了1×1的卷积核进行降维,大大减少了参数量。
- 融合不同尺度的特征信息。
- 并行结构,结构稀疏,局部最优。
(2) 1x1卷积核降维
前面Inception模块中提到,使用1x1卷积核来进行降维。所谓降维,就是通过降低卷积核的数量,从而大大减少模型参数。那下面我们就来演示一下,1x1卷积核具体是如何进行降维的。
如下图所示,对于同样的通道数为512的输入特征图,分别使用1x1卷积核和不使用1x1卷积核进行了一组对比实验。
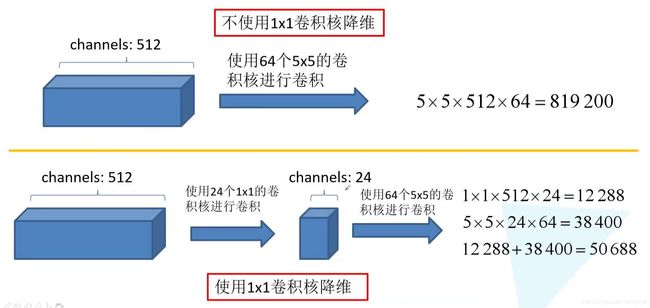
不使用1x1卷积核降维。由卷积规则(卷积核通道数=输入特征图通道数)可知,5x5卷积核的通道数(维度)为512。因此64个5x5卷积核的参数一共是:5x5x512x64=819200使用1x1卷积核进行降维。若采用24个1x1卷积核进行降维,由卷积规则可知,中间层特征图的维度为24。因此,当再用5x5卷积核对中间层特征图进行卷积时,维度就降为了24,也就是说这时候64个5x5卷积核的通道数降为了24。因此总的参数量是:1x1x512x64+5x5x24x64=50688
对比可知:没有进行降维的模型参数有819200个,经过1x1卷积核降维之后的模型参数仅有50688个,参数量减少了16倍多!
对卷积规则还不太熟悉的盆友请戳这里:深度学习笔记(一):卷积层+激活函数+池化层+全连接层
(3) 辅助分类器
考虑到网络的深度较大,以有效方式将梯度传播回所有层的能力有限,可能会产生梯度弥散现象。因此在网络中间层设计了两个辅助分类器,希望以此激励网络在较低层进行分类,从而增加了被传播回的梯度信号,避免出现梯度弥散。
在训练过程中,它们的损失将以折扣权重添加到网络的总损失中(辅助分类器的损失加权为0.3)。 在测试过程中,这些辅助网络将被丢弃。其网络结构如下:
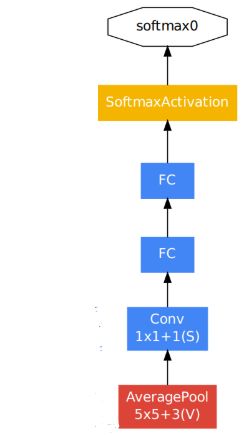
设计了完全相同的两个辅助分类器,这些分类器采用较小的卷积网络的形式,位于Inception(4a)和(4d)模块的输出之上。
如上图所示,具体结构与参数如下:
- 第一层是一个平均池化下采样层,池化核大小为5x5,步长为3
- 第二层是卷积层,卷积核大小为1x1,步长为1,卷积核个数是128
- 第三层是全连接层,节点个数是1024
- 第四层是全连接层,节点个数是1000,进行1000分类。
- 最后经过Softmax激活函数,将模型输出转化为预测的类别概率输出
(4) GoogLeNet整体结构
下表是原论文中给出的参数列表,描述了GoogLeNet每个卷积层的卷积核个数、卷积核大小等信息。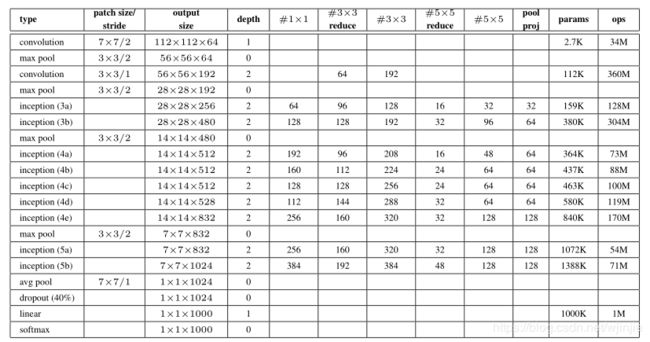
- 在该网络中,输入大小为224×224的RGB颜色通道图片。
- 所有卷积层,包括Inception模块内部的那些卷积,均使用ReLU激活函数。
- 对于我们搭建的Inception模块,需要关注的是#1x1, #3x3reduce, #3x3, #5x5reduce, #5x5, poolproj这六列,分别对应着
Inception模块内置卷积层所使用的卷积核个数。具体对应关系可参见下图:
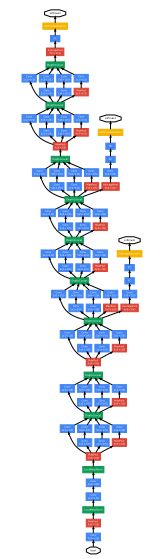
GoogLeNet的完整结构图如下,由于原图放大后很长,为了排版更紧凑美观,这里只插入了论文原图。想看大图的盆友,可以戳这里,在文章中有:GoogLeNet 原文翻译:《Going deeper with convolutions》
1.4 GoogLeNet 的性能
在2014年 ILSVRC 挑战赛 ImageNet 分类任务上获得冠军,测试结果如下表:
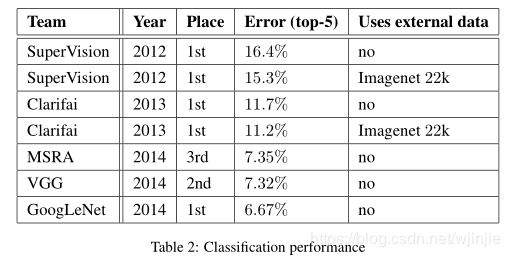
GoogLeNet最终在验证和测试数据集上均获得6.67%的Top-5错误率,排名第一。 与2012年的SuperVision方法相比,相对减少了56.5%,与上一年的最佳方法(Clarifai)相比,减少了约40%。
Top-5错误率,是将真实类别与排名前5个的预测类进行比较:如果真实类别位于前五名预测类之中,则无论其排名如何,图像被视为正确分类 。 该挑战赛使用Top-5错误率进行排名。
当然,GoogLeNet的检测效果也很不错,这里暂时只对分类效果进行评价。
二、TensorFlow2.0搭建GoogLeNet实战
2.1 数据集准备
(1) 数据集简介
这次我采用的是花分类数据集,该数据集一共有5个类别,分别是:daisy、dandelion、roses、sunflowers、tulips,一共有3670张图片。按9:1划分数据集,其中训练集train中有3306张、验证集val中有364张图片。
数据集下载地址:花分类数据集, 提取码:9ao5
大家下载完,将文件解压后直接放在工程根目录下,就像我这样:

(2) 加载数据集
这里我采用的方式是,使用keras底层模块图像生成器对数据集进行加载和预处理。需要说明一点的是:原来的类别标签是daisy、dandelion、roses、sunflowers、tulips,不能直接喂入神经网络,要将其转化为数字标签。并将创建好的数字标签字典写入了class_indices.json文件。
主要代码如下:
# 定义训练集图像生成器,并对图像进行预处理
train_image_generator = ImageDataGenerator(preprocessing_function=pre_function,
horizontal_flip=True) # 水平翻转
# 使用图像生成器从文件夹train_dir中读取样本,默认对标签进行了one-hot编码
train_data_gen = train_image_generator.flow_from_directory(directory=train_dir,
batch_size=batch_size,
shuffle=True,
target_size=(im_height, im_width),
class_mode='categorical') # 分类方式
total_train = train_data_gen.n # 训练集样本数
class_indices = train_data_gen.class_indices # 数字编码标签字典:{类别名称:索引}
inverse_dict = dict((val, key) for key, val in class_indices.items()) # 转换字典中键与值的位置
json_str = json.dumps(inverse_dict, indent=4) # 将转换后的字典写入文件class_indices.json
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
2.2 网络搭建
由于GooLeNet网络结构较为复杂,这里我按论文中的各个主要结构:Inception模块、辅助分类器、完整结构,将它们用函数或类的形式进行封装。主要代码如下:
(1) Inception模块
class Inception(layers.Layer):
# ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj分别对应Inception中各个卷积核的个数,**kwargs可变长度字典变量,存层名称
def __init__(self, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj, **kwargs):
super(Inception, self).__init__(**kwargs)
# 分支1
self.branch1 = layers.Conv2D(ch1x1, kernel_size=1, activation="relu")
# 分支2
self.branch2 = Sequential([
layers.Conv2D(ch3x3red, kernel_size=1, activation="relu"),
layers.Conv2D(ch3x3, kernel_size=3, padding="SAME", activation="relu")])
# 分支3
self.branch3 = Sequential([
layers.Conv2D(ch5x5red, kernel_size=1, activation="relu"),
layers.Conv2D(ch5x5, kernel_size=5, padding="SAME", activation="relu")])
# 分支4
self.branch4 = Sequential([
layers.MaxPool2D(pool_size=3, strides=1, padding="SAME"),
layers.Conv2D(pool_proj, kernel_size=1, activation="relu")])
def call(self, inputs, **kwargs):
branch1 = self.branch1(inputs)
branch2 = self.branch2(inputs)
branch3 = self.branch3(inputs)
branch4 = self.branch4(inputs)
# 将4个分支输出按通道连接
outputs = layers.concatenate([branch1, branch2, branch3, branch4])
return outputs
(2) 辅助分类器InceptionAux
class InceptionAux(layers.Layer):
# num_classes表示输出分类节点数,**kwargs存放每层名称
def __init__(self, num_classes, **kwargs):
super(InceptionAux, self).__init__(**kwargs)
self.averagePool = layers.AvgPool2D(pool_size=5, strides=3) # 平均池化
self.conv = layers.Conv2D(128, kernel_size=1, activation="relu")
self.fc1 = layers.Dense(1024, activation="relu") # 全连接层1
self.fc2 = layers.Dense(num_classes) # 全连接层2
self.softmax = layers.Softmax() # softmax激活函数
def call(self, inputs, **kwargs):
x = self.averagePool(inputs)
x = self.conv(x)
x = layers.Flatten()(x) # 拉直
x = layers.Dropout(rate=0.5)(x)
x = self.fc1(x)
x = layers.Dropout(rate=0.5)(x)
x = self.fc2(x)
x = self.softmax(x)
return x
(3) GooLeNet整体结构
def GoogLeNet(im_height=224, im_width=224, class_num=1000, aux_logits=False):
# 输入224*224的3通道彩色图片
input_image = layers.Input(shape=(im_height, im_width, 3), dtype="float32")
x = layers.Conv2D(64, kernel_size=7, strides=2, padding="SAME", activation="relu", name="conv2d_1")(input_image)
x = layers.MaxPool2D(pool_size=3, strides=2, padding="SAME", name="maxpool_1")(x)
x = layers.Conv2D(64, kernel_size=1, activation="relu", name="conv2d_2")(x)
x = layers.Conv2D(192, kernel_size=3, padding="SAME", activation="relu", name="conv2d_3")(x)
x = layers.MaxPool2D(pool_size=3, strides=2, padding="SAME", name="maxpool_2")(x)
# Inception模块
x = Inception(64, 96, 128, 16, 32, 32, name="inception_3a")(x)
x = Inception(128, 128, 192, 32, 96, 64, name="inception_3b")(x)
x = layers.MaxPool2D(pool_size=3, strides=2, padding="SAME", name="maxpool_3")(x)
# Inception模块
x = Inception(192, 96, 208, 16, 48, 64, name="inception_4a")(x)
# 判断是否使用辅助分类器1。训练时使用,测试时去掉。
if aux_logits:
aux1 = InceptionAux(class_num, name="aux_1")(x)
# Inception模块
x = Inception(160, 112, 224, 24, 64, 64, name="inception_4b")(x)
x = Inception(128, 128, 256, 24, 64, 64, name="inception_4c")(x)
x = Inception(112, 144, 288, 32, 64, 64, name="inception_4d")(x)
# 判断是否使用辅助分类器2。训练时使用,测试时去掉。
if aux_logits:
aux2 = InceptionAux(class_num, name="aux_2")(x)
# Inception模块
x = Inception(256, 160, 320, 32, 128, 128, name="inception_4e")(x)
x = layers.MaxPool2D(pool_size=3, strides=2, padding="SAME", name="maxpool_4")(x)
# Inception模块
x = Inception(256, 160, 320, 32, 128, 128, name="inception_5a")(x)
x = Inception(384, 192, 384, 48, 128, 128, name="inception_5b")(x)
# 平均池化层
x = layers.AvgPool2D(pool_size=7, strides=1, name="avgpool_1")(x)
# 拉直
x = layers.Flatten(name="output_flatten")(x)
x = layers.Dropout(rate=0.4, name="output_dropout")(x)
x = layers.Dense(class_num, name="output_dense")(x)
aux3 = layers.Softmax(name="aux_3")(x)
# 判断是否使用辅助分类器
if aux_logits:
model = models.Model(inputs=input_image, outputs=[aux1, aux2, aux3])
else:
model = models.Model(inputs=input_image, outputs=aux3)
return model
2.3 模型的装配与训练
部分代码如下:
# 使用keras底层api进行网络训练。
loss_object = tf.keras.losses.CategoricalCrossentropy(from_logits=False) # 定义损失函数(这种方式需要one-hot编码)
optimizer = tf.keras.optimizers.Adam(learning_rate=0.0003) # 优化器
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.CategoricalAccuracy(name='train_accuracy') # 定义平均准确率
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.CategoricalAccuracy(name='test_accuracy')
2.4 训练集/验证集上测试结果
由于不在实验室,我用的是笔记本进行训练的。大概跑1个epoch耗时15分钟,我跑了19个epochs,花了将近5个小时,训练集上准确度达到83.9%,验证集上准确率达到了83.7%。当时因为用电脑有事,我提前终止了训练。大家有时间,可以多训练下,精确度可以达到更高。下面贴出我的部分训练结果:
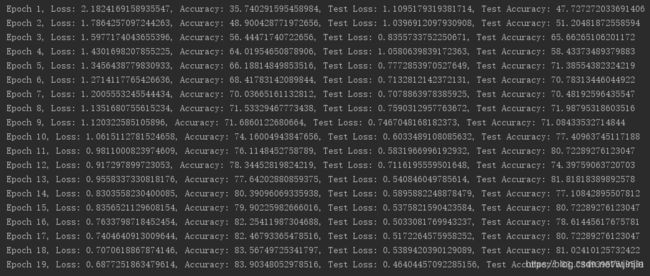
图中,打印出了每训练完一个epoch后的loss值、训练集分类准确度、测试集分类准确度。可见,网络的损失值loss在不断减小,数据集上的准确度都在稳步上升,因此模型此时是收敛的,继续训练可以得到更好的分类准确度。
2.5 加载模型,对单张图片预测
在工程根目录下,放入一张类别为daisy的图片,将其命名为daisy_test.jpg。我们读入这张图片,加载刚才已经训练好的模型,对图片进行预测。
预测代码如下:
# 读入图片
img = Image.open("E:/DeepLearning/GoogLeNet/daisy_test.jpg")
# resize成224x224的格式
img = img.resize((im_width, im_height))
plt.imshow(img)
# 对原图标准化处理
img = ((np.array(img) / 255.) - 0.5) / 0.5
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img, 0))
# 读class_indict文件
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
model = GoogLeNet(class_num=5, aux_logits=False) # 重新构建网络
model.summary()
model.load_weights("./save_weights/myGoogLenet.h5", by_name=True) # 加载模型参数
result = model.predict(img)
predict_class = np.argmax(result)
print('预测出的类别是:', class_indict[str(predict_class)]) # 打印显示出预测类别
plt.show()
输入的图片daisy_test.jpg属于daisy类,图片如下:

预测结果如下:

可见,预测结果与原图daisy_test.jpg的标签一致,预测成功!
写到这里文章就要结束了。电脑前的你是不是也想试一试呢?
为了助你能快速搭建好网络,这里奉上我的Github项目地址:【AI 菌】的Github
如果你想更深入理解GoogLeNet,建议戳戳这里:论文翻译:GoogLeNet 原文翻译:《Going deeper with convolutions》
最后就要和大家说再见啦!如果这篇文章对您有帮助的话,请点个赞支持一下呗,谢谢!