python爬虫之Beautifulsoup模块用法详解
什么是beautifulsoup:
是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。(官方)
beautifulsoup是一个解析器,可以特定的解析出内容,省去了我们编写正则表达式的麻烦。
这里我们用的是bs4:
1、导入模块:
from bs4 import beautifulsoup
2、选择解析器解析指定内容:
soup=beautifulsoup(解析内容,解析器)
常用解析器:html.parser,lxml,xml,html5lib
有时候需要安装安装解析器:比如pip3 install lxml
BeautifulSoup默认支持Python的标准HTML解析库,但是它也支持一些第三方的解析库:
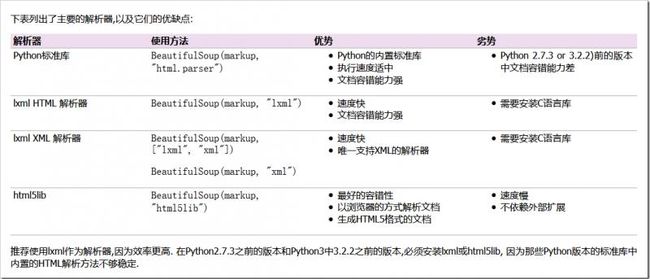
解析器之间的区别(此处摘自官方文档)
Beautiful Soup为不同的解析器提供了相同的接口,但解析器本身时有区别的。同一篇文档被不同的解析器解析后可能会生成不同结构的树型文档。
区别最大的是HTML解析器和XML解析器,看下面片段被解析成HTML结构:
BeautifulSoup("")
# 因为空标签 不符合HTML标准,所以解析器把它解析成
同样的文档使用XML解析如下(解析XML需要安装lxml库)。注意,空标签依然被保留,并且文档前添加了XML头,而不是被包含在标签内:
BeautifulSoup("", "xml")
#
# HTML解析器之间也有区别,如果被解析的HTML文档是标准格式,那么解析器之间没有任何差别,只是解析速度不同,结果都会返回正确的文档树。
但是如果被解析文档不是标准格式,那么不同的解析器返回结果可能不同。下面例子中,使用lxml解析错误格式的文档,结果
BeautifulSoup("", "lxml")
# 使用html5lib库解析相同文档会得到不同的结果:
BeautifulSoup("", "html5lib")
# html5lib库没有忽略掉
使用pyhton内置库解析结果如下:
BeautifulSoup("", "html.parser")
# 与lxml [7] 库类似的,Python内置库忽略掉了
不同的解析器可能影响代码执行结果,如果在分发给别人的代码中使用了 BeautifulSoup ,那么最好注明使用了哪种解析器,以减少不必要的麻烦。
3、操作
约定soup是beautifulsoup(解析内容,解析器)返回的解析对象。
3.1 使用标签名查找
- 使用标签名来获取结点:
soup.标签名
- 使用标签名来获取结点标签名(这个重点是name,主要用于非标签名式筛选时,获取结果的标签名):
soup.标签.name
- 使用标签名来获取结点属性:
soup.标签.attrs(获取全部属性)
soup.标签.attrs[属性名](获取指定属性)
soup.标签[属性名](获取指定属性)
soup.标签.get(属性名)
- 使用标签名来获取结点的文本内容:
soup.标签.text
soup.标签.string
soup.标签.get_text()
补充1:
上面的筛选方式可以使用嵌套:
print(soup.p.a)#p标签下的a标签
补充2:
以上的name,text,string,attrs等方法都可以使用在当结果是一个bs4.element.Tag对象的时候:
from bs4 import BeautifulSoup
html = """
this is a title
123
456
advertisements
"""
soup = BeautifulSoup(html,'lxml')
print("获取结点".center(50,'-'))
print(soup.head)#获取head标签
print(soup.p)#返回第一个p标签
#获取结点名
print("获取结点名".center(50,'-'))
print(soup.head.name)
print(soup.find(id='i1').name)
#获取文本内容
print("获取文本内容".center(50,'-'))
print(soup.title.string)#返回title的内容
print(soup.title.text)#返回title的内容
print(soup.title.get_text())
#获取属性
print("-----获取属性-----")
print(soup.p.attrs)#以字典形式返回标签的内容
print(soup.p.attrs['class'])#以列表形式返回标签的值
print(soup.p['class'])#以列表形式返回标签的值
print(soup.p.get('class'))
#############
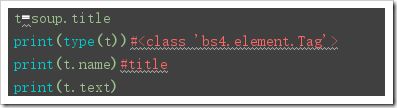
t=soup.title
print(type(t))#
print(t.name)#title
print(t.text)
#嵌套选择:
print(soup.head.title.string) - 获取子结点(直接获取也会获取到'\n',会认为'\n'也是一个标签):
soup.标签.contents(返回值是一个列表)
soup.标签.children(返回值是一个可迭代对象,获取实际子结点需要迭代)

- 获取子孙结点:
soup.标签.descendants(返回值也是一个可迭代对象,实际子结点需要迭代)
- 获取父结点:
soup.标签.parent
- 获取祖先结点[父结点,祖父结点,曾祖父结点…]:
soup.标签.parents
- 获取兄弟结点:
soup.next_sibling(获取后面的一个兄弟结点) soup.next_siblings(获取后面所有的兄弟结点)(返回值是一个可迭代对象) soup.previous_sibling(获取前一兄弟结点) soup.previous_siblings(获取前面所有的兄弟结点)(返回值是一个可迭代对象)
补充3:
与补充2一样,上面的函数都可以使用在当结果是一个bs4.element.Tag对象的时候。
from bs4 import BeautifulSoup
html = """
Title
advertisements
aspan
"""
soup = BeautifulSoup(html, 'lxml')
#获取子结点
print("获取子结点".center(50,'-'))
print(soup.p.contents)
print("\n")
c=soup.p.children#返回的是一个可迭代对象
for i,child in enumerate(c):
print(i,child)
print("获取子孙结点".center(50,'-'))
print(soup.p.descendants)
c2=soup.p.descendants
for i,child in enumerate(c2):
print(i,child)
print("获取父结点".center(50,'-'))
c3=soup.title.parent
print(c3)
print("获取父,祖先结点".center(50,'-'))
c4=soup.title.parents
print(c4)
for i,child in enumerate(c4):
print(i,child)
print("获取兄弟结点".center(50,'-'))
print(soup.p.next_sibling)
print(soup.p.previous_sibling)
for i,child in enumerate(soup.p.next_siblings):
print(i,child,end='\t')
for i,child in enumerate(soup.p.previous_siblings):
print(i,child,end='\t')3.2 使用find\find_all方式
- find( name , attrs , recursive , text , **kwargs )
根据参数来找出对应的标签,但只返回第一个符合条件的结果。
- find_all( name , attrs , recursive , text , **kwargs )
根据参数来找出对应的标签,但只返回所有符合条件的结果。
- 筛选条件参数介绍:
name:为标签名,根据标签名来筛选标签
attrs:为属性,,根据属性键值对来筛选标签,赋值方式可以为:属性名=值,attrs={属性名:值}(但由于class是python关键字,需要使用class_)

text:为文本内容,根据指定文本内容来筛选出标签,单独使用text作为筛选条件,只会返回text,所以一般与其他条件配合使用。
recursive:指定筛选是否递归,当为False时,不会在子结点的后代结点中查找,只会查找子结点。
获取到结点后的结果是一个bs4.element.Tag对象,所以对于获取属性、文本内容、标签名等操作可以参考前面“使用标签筛选结果”时涉及的方法
from bs4 import BeautifulSoup
html = """
Title
advertisements
aspan
"""
soup = BeautifulSoup(html, 'lxml')
print("---------------------")
print(soup.find_all('a'),end='\n\n')
print(soup.find_all('a')[0])
print(soup.find_all(attrs={'id':'i1'}),end='\n\n')
print(soup.find_all(class_='news'),end='\n\n')
print(soup.find_all('a',text='123456'))#
print(soup.find_all(id='i2',recursive=False),end='\n\n')#
a=soup.find_all('a')
print(a[0].name)
print(a[0].text)
print(a[0].attrs)3.3 使用select筛选(select使用CSS选择规则)
soup.select(‘标签名'),代表根据标签来筛选出指定标签。
CSS中#xxx代表筛选id,soup.select(‘#xxx')代表根据id筛选出指定标签,返回值是一个列表。
CSS中.###代表筛选class,soup.select('.xxx')代表根据class筛选出指定标签,返回值是一个列表。
嵌套select: soup.select(“#xxx .xxxx”),如(“#id2 .news”)就是id=”id2”标签下class=”news的标签,返回值是一个列表。
获取到结点后的结果是一个bs4.element.Tag对象,所以对于获取属性、文本内容、标签名等操作可以参考前面“使用标签筛选结果”时涉及的方法。
from bs4 import BeautifulSoup
html = """
Title
advertisements
aspan
"""
soup = BeautifulSoup(html, 'lxml')
sp1=soup.select('span')#返回结果是一个列表,列表的元素是bs4元素标签对象
print(soup.select("#i2"),end='\n\n')
print(soup.select(".news"),end='\n\n')
print(soup.select(".news #i2"),end='\n\n')
print(type(sp1),type(sp1[0]))
print(sp1[0].name)#列表里面的元素才是bs4元素标签对象
print(sp1[0].attrs)
print(sp1[0]['class'])补充4:
对于代码不齐全的情况下,可以使用soup.prettify()来自动补全,一般情况下建议使用,以避免代码不齐。
from bs4 import BeautifulSoup
html = """
Title
advertisements
aspan
"""
soup = BeautifulSoup(html, 'lxml')
c=soup.prettify()#上述html字符串中末尾缺少 和
print(c)如果想要获得更详细的介绍,可以参考官方文档,令人高兴的是,有了比较简易的中文版:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
文源网络,仅供学习之用,如有侵权,联系删除。
我将优质的技术文章和经验总结都汇集在了我的公众号【Python圈子】里。
在学习Python的道路上肯定会遇见困难,别慌,我这里有一套学习资料,包含40+本电子书,600+个教学视频,涉及Python基础、爬虫、框架、数据分析、机器学习等,不怕你学不会!还有学习交流群,一起学习进步~
