记一次性能测试过程中遇到的问题的定位思路
1. 项目介绍
该项目是某银行的一个零售信贷的系统,主要功能是实现贷款信息的录入,和一些待办事项的查询。贷款信息的录入这块,表单很复杂,需要填写的信息特别多,包括客户的基本信息、详细信息、贷款申请信息、押品的信息等。各交易响应时间要求80用户并发时达到5-8秒,平均TPS1.5左右。
2. 压测场景介绍
2.1 基准场景
基准场景是用单个用户对需要压测的交易压测5-10分钟,初步了解下该交易的响应时间和TPS,一般此过程不会出现问题。
2.2 单场景负载测试
单场景负载测试是对需要压测的交易使用80用户并发,压测10分钟左右,考查单个交易的负载情况。这个场景容易测试出来响应时间慢或者服务器资源利用率高的问题,交易的性能问题会在这个场景中暴露很多。
2.3 混合场景容量测试
把需要压测的交易按照一定的比例混合,以客户要求的最低并发数为基准,以一定的梯度递增并发用户数压测混合交易,直至系统出现性能拐点。这个场景主要是考察系统最大的处理能力是多少。
2.4 浪涌场景
以系统最优处理能力(资源使用率接近75%-80%,响应时间和tps达标)的并发用户数为最大并发,以系统的资源使用率在20%-30%左右的并发用户数为最小并发,最小并发和最大并发交替运行,每个梯度运行10分钟,共运行一个小时。整个场景设置如下:

这个场景考察突然增大或者减少用户数,系统资源会不会上升或下降,主要是看用户数忽然减少时,资源利用率会不会下降。
2.5 稳定性测试
稳定性测试是使用最优并发用户数的80%用户,把所有需要压测的交易按照一定的比例混合,进行压测48小时,也有压测24小时的情况。主要是考察系统长时间运行的情况,有没有内存泄漏之类的问题。
3 压测中问题的定位思路和常用的命令及工具
3.1 刚开始压测报错,停了之后重新压测不报错
这种情况经常遇到,特别是重启服务之后,因为系统刚重启,需要做一些初始化的动作,如果一下上很多兵法用户数难免会报错,只要压测几次之后不再报错,就是正常的,服务器也需要“预热”一段时间。
3.2 少用户并发不报错,大用户并发报错
可能有两种情况引起这种问题,一是脚本的问题:参数设置不够或者错误;二是连接池设置的不合理。一定要先排除脚本的问题之后,再去查找其他问题,不要给开发人员带来不必要的麻烦。
3.3 服务器资源利用率高
服务器资源利用最常见的是CPU利用率高,内存利用率高常见于数据库服务器,应用服务器的内存一般会在长时间压测时出现问题。I/O一般常见磁盘被用完的情况,对于应用服务器可能是有大量的日志读写,对于数据库服务器可能是表空间增长过大,磁盘空间不足。这里主要是分析CPU利用率高的问题,分别对数据库CPU利用率高和应用服务器利用率高的情况进行说明。
3.3.1 数据库服务器CPU利用率高
数据库CPU利用率高一般是大量的逻辑读或者物理读引起的,也有可能是解析比较复杂的SQL,如果是Oracle 数据库,可以通过抓取AWR报告进行,重点看下面两项:
- SQL ordered by Gets
- SQL ordered by Physical Reads (UnOptimized)
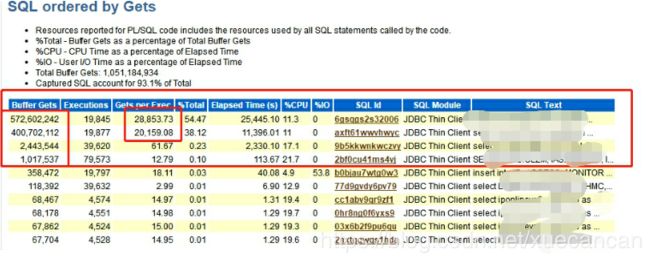
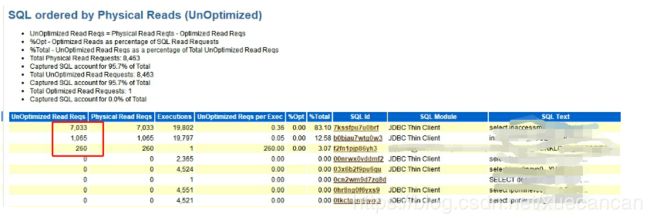
这一部分,通过Buffer Gets对SQL语句进行排序,即通过它执行了多少个逻辑I/O来排序。顶端的注释表明一个PL/SQL单元的缓存获得(Buffer Gets)包括被这个代码块执行的所有SQL语句的Buffer Gets。大量的逻辑读往往伴随着较高的CPU消耗,在这里的Buffer Gets是一个累积值,所以这个值大并不一定意味着这条语句的性能存在问题。通常我们可以通过对比该条语句的Buffer Gets和physical reads值,如果这两个比较接近,肯定这条语句是存在问题的 ,如果对比差别不大,可以关注 **gets per exec的值,这个值如果太大,表明这条语句可能使用了一个比较差的索引或者使用了不当的表连接。
另外还可以通过查看使用CPU高的进程ID,根据进程ID查找对应的SQL ID,从而找出相应的sql语句。
3.3.2 应用服务器CPU利用率高
针对应用服务器CPU利用率高有一个固定的定位问题思路:
- 使用top命令查看占用CPU最高的进程号
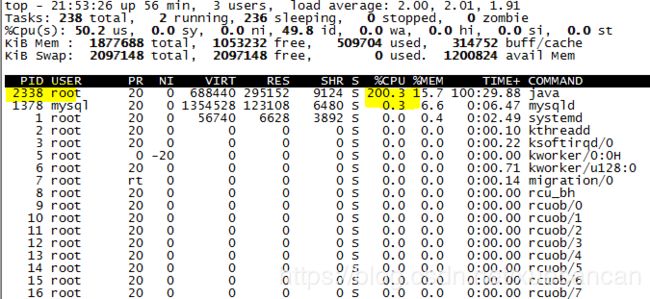
- 查看进程下所有线程信息,可以使用top,也可以使用ps命令
top -p pid -H
-p 表示进程PID
-c 显示进程的绝对路径
-H 显示进程的所有线程

也可以用下面的命令将 cpu 占用率高的线程找出来:
ps H -eo user,pid,ppid,tid,time,%cpu,cmd --sort=%cpu

- 找到了占用cpu最高的两个线程,要查看线程的信息, 把上面的进程信息dump下来,然后在文件查找线程信息,不是直接dump线程信息。线程对应的是栈,在栈中可以看到线程操作了哪些数据。

注意,有时候需要把线程号转成16进制,因为dunmp的线程号可能是以16进程显示的,比如:nid=0xc46e,0x表示是16进制的数据,c46e是线程号,转成十进制是142156,则对应的线程号是142156。
3.3.3 响应时间慢
响应时间慢可以从两个方面来分析,一是查看AWR报告,或者在数据库中搜索慢的sql,在AWR报告中需要关注下面两项:
- SQL ordered by Elapsed Time
- SQL ordered by CPU Time
一般sql的慢是没加索引或者索引失效引起的,也有可能是查询方式过于复杂,表的关联关系不对,小表驱动大表,或者在sql语句中进行了大量的计算,具体的问题需要DBA或者开发人员进行分析。
如果不是慢sql引起的,则需要查找程序的问题,可以通过压测工具定位到具体方法,也可以dump进程,查看是否有锁争用、死锁或者资源等待的情况。在本次压测中出现了大量dubbo服务等待数据库响应的线程,数据库的CPU利用率达到90%,导致应用的大部分进程是sleeping状态,通过查看dump下来的线程发现大部分处于Runable状态,而他们都在等待锁住同一资源(数据库)。增加数据库CPU之后,响应时间慢的问题得到解决。
如何详细查看dump的线程信息,参考:(待完成。。。。。。)
3.3.4 稳定性压测出现内存泄露
本次稳定性压测过程中出现了内存泄露的情况,具体引起的原因还在分析,但问题已经定位到。稳定压测的前20小时之内,系统很稳定,20小时之后,出现了大量的报错,并且报错信息一直增加,部分交易响应时间达到二十几秒,数据库服务器几乎没有压力,查看weblogic进程,几乎没有工作(占用的cpu资源0.5%左右),但有一个java进程CPU使用率很高:

怀疑是内存泄露,于是查看jvm内存回收情况:jstat -gcutil 10366 2000
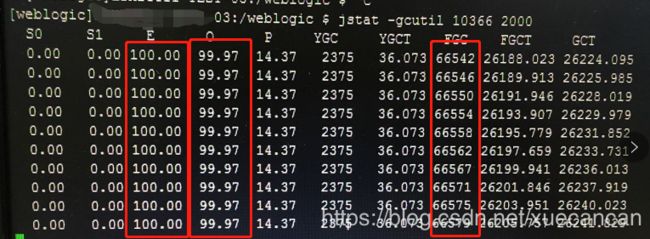
每2秒查看一次10366进程的内存回收情况,几乎是一秒2次,并且伊甸园区和年老代的内存已经使用完毕,即使1秒回收2次也不能释放,肯定有不能回收的大对象存在。下面就使用jmap工具,dump 将内存使用的详细情况输出到文件
jmap -dump:live,format=b,file=a.log pid
dump下来的文件大概2个G,使用工具(IBM HeapAnalyzer 工具 )进行分析。