springboot 集成 elasticsearch实战
1. 首先版本要求

2.下载对应的 压缩包
下载地址: https://www.elastic.co/cn/downloads/elasticsearch

3.解压我这对应的是2.4.6版本 (window)
config 文件修改
cluster.name: es-pdf
node.name: node-pdf
network.host: 0.0.0.0
http.port: 9200
4. bin>elasticsearch.bat双击,然后访问http://localhost:9200/ 出现以下就代表成功

5,安装head插件, 首先node环境,这里网上一大批,成功后访问http://localhost:9100/可查看数据,
记着先起es服务,后起grunt server,
接下来就是代码实战
1.我的springboot1.5.9为例,先添加依赖
org.springframework.boot
spring-boot-starter-data-elasticsearch
spring:
data:
elasticsearch:
cluster-name: es-pdf
cluster-nodes: 192.168.110.109:9300
repositories:
enabled: true
2,创建索引
package com.**.p**.elasticsearch.model;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldIndex;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
import java.util.Date;
/**
* @author chong
* @create 2020/4/7
* Desc:
*/
@Data
@Document(indexName = "demo",type = "customer", shards = 1, replicas = 0, refreshInterval = "-1")
public class Demo implements Serializable {
/**
* 唯一标识符
*/
@Id
@Field(type = FieldType.Long,index = FieldIndex.not_analyzed, store = true)
private Long id;
/**
* 添加时间
*/
@Field(type = FieldType.Date, index = FieldIndex.not_analyzed, store = true)
private Date addDateTime;
/**
* 修改时间
*/
@Field(type = FieldType.Date, index = FieldIndex.not_analyzed, store = true)
private Date updateDateTime = new Date();
/**
* 名称
*/
@Field(type = FieldType.String,analyzer = "ik", searchAnalyzer = "ik" , store = true)
private String name;
/**
* 描述
*/
@Field(type = FieldType.String,analyzer = "ik", searchAnalyzer = "ik" , store = true)
private String desc;
/**
* 删除标志位(0:未删除;1:删除)
*/
@Field(type = FieldType.Integer, index = FieldIndex.not_analyzed, store = true)
private Integer ifDelete = 0;
/**
* 启用禁用状态(0:禁用;1:启用)
*/
@Field(type = FieldType.Integer, index = FieldIndex.not_analyzed, store = true)
private Integer useMark;
/**
* 浏览次数
*/
@Field(type = FieldType.Integer, index = FieldIndex.not_analyzed, store = true)
private Integer viewingTimes = 0;
}
3.创建repository 类似于jpa,使用简单
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
/**
* @author chong
* @create 2020/4/7
* Desc: es
*/
@Repository
public interface DemoRepository extends ElasticsearchRepository {
}
4,实现简单的保存 , 分页 , 高亮显示搜索条件 以及返回前台时报错处理,中间遇到不少的坑,希望可以帮助大家
实现的方法很多,我这列举一两种
@Service
public class DemoServiceImpl{
@Autowired
private DemoRepository demoRepository;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Override
public Demo save(Demo demo) {
demoRepository.save(demo);
}
/**
* es分页查询
*
* @param pageAndSortDto
* @return
*/
@Override
public Page getPageList(PageAndSortDto pageAndSortDto) throws Exception{
Pageable pageable = null;
if (pageAndSortDto.getPage() != null) {
List sorts = pageAndSortDto.getSorts();
Sort sort = null;
if (sorts.size() > 0) {
Sort.Direction dir = sorts.get(0).getDir().toLowerCase().equals("desc") ? Sort.Direction.DESC : Sort.Direction.ASC;
sort = new Sort(dir, sorts.get(0).getProp());
}
pageable = new PageRequest(pageAndSortDto.getPage().getPageNum() - 1, pageAndSortDto.getPage().getPageSize(), sort);
}
BoolQueryBuilder builder = QueryBuilders.boolQuery();
HighlightBuilder.Field hfieldName = new HighlightBuilder.Field("name")
.preTags("")
.postTags("")
.fragmentSize(100);
HighlightBuilder.Field hfieldAns = new HighlightBuilder.Field("desc")
.preTags("")
.postTags("")
.fragmentSize(100);
for (QueryDto queryDto : pageAndSortDto.getQueryList()) {
switch (queryDto.getType()) {
case "equal":
builder.must(QueryBuilders.matchQuery(queryDto.getParam(), queryDto.getValue()[0]));
break;
case "like":
builder.must(QueryBuilders.multiMatchQuery(queryDto.getValue()[0],"name", "answer"));
break;
case "in":
Object[] obj = queryDto.getValue();
for (Object o : obj) {
builder.should(QueryBuilders.matchPhraseQuery(queryDto.getParam(), o));
}
break;
}
}
// Iterable search = demoRepository.search(builder, pageable);
// 高亮显示搜索条件
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(builder)
.withPageable(pageable)
.withHighlightFields(hfieldName,hfieldAns)
.build();
Page page = elasticsearchTemplate.queryForPage(searchQuery, Demo.class, new SearchResultMapper() {
@Override
public AggregatedPage mapResults(SearchResponse response, Class clazz, Pageable pageable) {
List chunk = new ArrayList();
for (SearchHit searchHit : response.getHits().getHits()) {
Map smap = searchHit.getSource();
Map hmap = searchHit.getHighlightFields();
chunk.add((T)createEsDoc(smap,hmap));
}
AggregatedPage result=new AggregatedPageImpl(chunk,pageable,response.getHits().getTotalHits());
return result;
}
});
return fixEmptyPage(page);
}
/**
* 返回结果高亮显示
* @param smap
* @param hmap
* @return
*/
private Demo createEsDoc(Map smap,Map hmap){
Demo ed = new Demo();
if (hmap.get("name") != null)
ed.setName(hmap.get("name").fragments()[0].toString());
if (hmap.get("desc") != null)
ed.setDesc(hmap.get("desc").fragments()[0].toString());
if (smap.get("id") != null)
ed.setId(Long.parseLong(smap.get("id").toString()));
return ed;
}
/**
* 分页返回数据json 序列化转换报错处理
*
* @param page
* @param
* @return
*/
private Page fixEmptyPage(Page page) {
AggregatedPageImpl aggregatedPage = (AggregatedPageImpl) page;
Aggregations aggregations = aggregatedPage.getAggregations();
if (aggregations == null) {
Field field = ReflectionUtils.findField(AggregatedPageImpl.class, "aggregations");
ReflectionUtils.makeAccessible(field);
ReflectionUtils.setField(field, aggregatedPage, InternalAggregations.EMPTY);
return aggregatedPage;
}
return page;
}
} 这里需要注意的是PageAndSortDto 是自定义的前台接收参数,个人可根据自己业务
5.分词,如果不装分词默认中文你会发现会吧中文分成单个,这块需要安装ik分词.根据版本下载,建议下载releases,直接解压,不需要打包
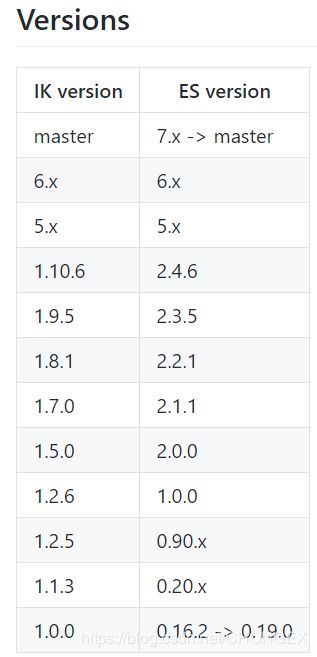
这里下载的是1.10.6,在elasticsearch里面plugins新建ik文件夹,重启就OK了