强化学习课程学习(4)——基于Q表格的方式求解RL之Model-Based类型的方法
经过初始了解强化学习的基本要素后,单单地凭借着这些要素还是无法构建强化学习模型来帮助我们解决实际问题,那么最初地模型是基于Q表格的方式来解决问题,常见的模型可以分成model-based和model-free两大类别,model-based常见的有MDP、DP;model-free常见的有MC、SARSA、Q-learning。
在本小章主要是阐述Model-based类型的常见方法。
基于Q表格的算法的思维导图

马尔可夫决策过程求解
有了这些基本要素,仍旧无法构建强化学习模型来帮助我们解决实际问题,在此过程中,模型的简化显得特别重要。为此,引入了马尔可夫决策过程(MDP)来简化强化学习模型并求解强化学习问题。
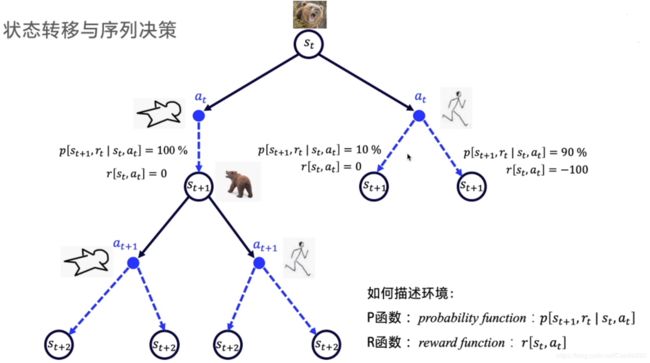
首先对于马尔科夫性,这些在机器学习算法中的隐马尔科夫模型、条件随机场、马尔科夫链等中都学习到,在这里,我们也需要对于环境的状态转化和个体的策略做马尔科夫性,即在状态 s s s时采取动作 a a a的概率仅仅与当前的状态 s s s有关,与其他要素无关,其公式为:
π ( a ∣ s ) = P ( A t = a ∣ S t = s ) \pi(a|s) = P(A_t = a | S_t = s) π(a∣s)=P(At=a∣St=s)
同样的,对于价值函数 v π ( s ) v_{\pi}(s) vπ(s)也需要做马尔科夫性假设,仅仅依赖于当前状态,价值函数可以表示为:
v π ( s ) = E π ( G t ∣ S t = s ) = E π ( R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋅ ⋅ ⋅ ∣ S t = s ) v_{\pi}(s) = E_{\pi}(G_t|S_t=s) = E_{\pi}(R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+ \cdot \cdot \cdot | S_t=s) vπ(s)=Eπ(Gt∣St=s)=Eπ(Rt+1+γRt+2+γ2Rt+3+⋅⋅⋅∣St=s)
其中, G t G_t Gt表示收获,是在一个MDP中从某一个状态 S t S_t St开始采样直到终止状态时所有奖励的有衰减之和。
每个状态转移到下一个状态的概率都是已知的,此时求解问题时概率模型也是可以求解出来的。
贝克曼方程
所谓贝克曼方程,在这里是指一个状态的价值由状态的奖励以及后续状态价值按照一定比例衰减联合而成的式子。
价值函数除了状态价值函数,还有动作价值函数 q π ( t , a ) q_{\pi}(t,a) qπ(t,a),即:
q π ( s , a ) = E π ( G t ∣ S t = s , A t = a ) = E π ( R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋅ ⋅ ⋅ ∣ S t = s , A t = a ) q_{\pi}(s,a) = E_{\pi}(G_t|S_t=s,A_t=a)\\ = E_{\pi}(R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+ \cdot \cdot \cdot | S_t=s,A_t=a) qπ(s,a)=Eπ(Gt∣St=s,At=a)=Eπ(Rt+1+γRt+2+γ2Rt+3+⋅⋅⋅∣St=s,At=a)
由此,根据价值函数的递推关系逻辑,我们也可以推导出基于动作的递推关系——贝克曼方程
q π ( s , a ) = E π ( G t ∣ S t = s , A t = a ) = E π ( R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋅ ⋅ ⋅ ∣ S t = s , A t = a ) = E π ( R t + 1 + γ ( R t + 2 + γ R t + 3 + ⋅ ⋅ ⋅ ) ∣ S t = s , A t = a ) = E π ( R t + 1 + γ G t + 1 ∣ S t = s , A t = a ) = E π ( R t + 1 + γ q π ( S t + 1 , A t + 1 ) ∣ S t = s , A t = a ) q_{\pi}(s,a) = E_{\pi}(G_t|S_t=s,A_t=a) \\ = E_{\pi}(R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+ \cdot \cdot \cdot | S_t=s,A_t=a) \\ = E_{\pi}(R_{t+1} + \gamma(R_{t+2} + \gamma R_{t+3} + \cdot \cdot \cdot)|S_t=s,A_t=a) \\ = E_{\pi}(R_{t+1} + \gamma G_{t+1}|S_t=s,A_t=a) \\ = E_{\pi}(R_{t+1} + \gamma q_{\pi}(S_{t+1},A_{t+1})|S_t=s,A_t=a) qπ(s,a)=Eπ(Gt∣St=s,At=a)=Eπ(Rt+1+γRt+2+γ2Rt+3+⋅⋅⋅∣St=s,At=a)=Eπ(Rt+1+γ(Rt+2+γRt+3+⋅⋅⋅)∣St=s,At=a)=Eπ(Rt+1+γGt+1∣St=s,At=a)=Eπ(Rt+1+γqπ(St+1,At+1)∣St=s,At=a)
而基于状态的价值函数的贝克曼方程为:
v π ( s ) = E π ( R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ) v_{\pi}(s) = E_{\pi}(R_{t+1}+\gamma v_{\pi}(S_{t+1})| S_t=s) vπ(s)=Eπ(Rt+1+γvπ(St+1)∣St=s)
因此,两者之间的关系式是:
v π ( s ) = ∑ a ∈ A v π ( s ) q π ( s , a ) v_{\pi}(s) = \sum_{a \in A}v_{\pi}(s)q_{\pi}(s,a) vπ(s)=a∈A∑vπ(s)qπ(s,a)
也就是说,状态价值函数是所有动作价值函数基于策略 π \pi π的期望。通俗说就是某状态下所有状态动作价值乘以该动作出现的概率,最后求和,就得到了对应的状态价值。
动态规划(DP)求解强化学习
除了马尔科夫决策过程,除此之外还可以使用动态规划来求解问题。动态规划的关键点有两个:一是问题的最优解可以由若干小问题的最优解构成,即通过寻找子问题的最优解来得到问题的最优解。第二是可以找到子问题状态之间的递推关系,通过较小的子问题状态递推出较大的子问题的状态。而强化学习的问题恰好是满足这两个条件的。
那么我们先来看看强化学习的两个基本问题,从而可以分析如何使用动态规划求解强化学习问题———————
-
预测问题。即给定强化学习的6个要素:状态集 S S S,动作集 A A A,模型状态转化概率矩阵 P P P, 即时奖励 R R R,衰减因子 γ \gamma γ, 给定策略 π \pi π, 求解该策略的状态价值函数 v ( π ) v(\pi) v(π)
-
控制问题。即给定强化学习5个要素,状态集 S S S,动作集 A A A,模型状态转化概率矩阵 P P P, 即时奖励 R R R,衰减因子 γ \gamma γ, 求解该策略的状态价值函数 v ∗ v_{*} v∗和最优策略 π ∗ \pi_{*} π∗
而马尔科夫决策过程中的状态价值函数的贝尔曼方程为:
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ‘ i n S P s s ‘ a v π ( s ‘ ) ) v_{\pi}(s) = \sum_{a \in A}\pi(a|s)(R^a_s + \gamma \sum_{s` in S}P^a_{ss`}v_{\pi}(s`)) vπ(s)=a∈A∑π(a∣s)(Rsa+γs‘inS∑Pss‘avπ(s‘))
通过以上的两个基本问题,可以看出我们可以将当前整个状态分解成每个小状态,也就是每个子问题,我们可以定义出子问题的求解每个状态的状态价值函数,同时这个以上式子又存在递推关系,利用它,我们可以使用上一个迭代周期内的状态价值来计算更新当前迭代周期某状态 s s s的状态价值。可见,使用动态规划来求解强化学习问题是比较自然的。动态规划算法使用全宽度(full-width)的回溯机制来进行状态价值的更新,也就是说,无论是同步还是异步动态规划,在每一次回溯更新某一个状态的价值时,都要回溯到该状态的所有可能的后续状态,并利用贝尔曼方程更新该状态的价值。这种全宽度的价值更新方式对于状态数较少的强化学习问题还是比较有效的,但是当问题规模很大的时候,动态规划算法将会因
贝尔曼维度灾难而无法使用。基于Q表格的方法的实际应用
交通灯

股票投资

感谢百度AI studio提供学习资料和平台,感谢科科老师的讲解!