[TOC]
https://blog.csdn.net/wlmnzf/article/details/79319509
Spectre以及meltdown漏洞是前段时间,十分热门的两个漏洞,它们之所以广受重视,是因为它们根据的是体系结构的设计漏洞,而非针对某个系统或者某个软件,因此它几乎可以遍及大多数近代的CPU。
这里主要有三个漏洞:
- Variant 1: bounds check bypass (CVE-2017-5753)【绕过边界检查】
- Variant 2: branch target injection (CVE-2017-5715)【分支目标注入】
- Variant 3: rogue data cache load (CVE-2017-5754)【恶意数据缓存载入】
Spectre 主要利用前两个漏洞进行攻击,而meltdown则主要利用第三个漏洞进行攻击。
1 内存映射
Linux和Windows的内存映射方法是不同的,在linux中,虚拟空间地址有4G,0~3G为用户空间,3~4G为内核空间

其中内核空间都相同,准确的讲是每个进程共享同一个内核空间

Linux在启动时会初始化一个进程,然后通过fork()生成子进程,Linux的fork机制会把父进程的页表和堆栈等一模一样地复制一份,然后在运行时,子进程通过缺页异常等操作来改变用户空间,如果内核空间部分也改变了,则只修改初始化进程的内核空间(!!!),其它子进程访问该页时,再通过缺页中断将这部分内容从父进程更新过来。
一般来讲,当进程进行系统调用进入内核态的时候,它应该能够访问整个地址空间的,但是在这里只能访问自己的1G的地址空间,于是我们需要通过地址的映射,来使他可以访问整个空间,内核空间分为:ZONE_DMA(内存开始的16MB) 、ZONE_NORMAL(16MB~896MB)、ZONE_HIGHMEM(896MB ~ 结束)三个区域,其中0~896M是直接映射的,其余部分会进行非线性映射。

2 Tomasulo算法

原始的Tomasulo算法是为了寄存器重命名以便消除指令的数据相关,数据一到就可以执行指令。
-
指令首先存在于指令队列(L1 Instruction cache)之中。
-
指令一条一条地从队列中取出来,进行译码,然后放到对应的操作保留站中,比如加法指令放到加法保留站中。乘法指令放到乘除法保留站中。Vj和Vk中是用来存储源操作数的(已经就绪的源操作数值取自于浮点寄存器),若源操作数还没有准备好,则通过Qj和Qk指向操作数的保留站号,等到被指向的保留站中的操作计算出了结果,则结果可以通过结果总线传回到保留站中需要的指令,然后将其Qj和Qk中的值改为0(表示已经准备好)。
-
当Qj和Qk都为0时,那一条指令就可以送到乘/除器中执行。
3 乱序执行
最早期CPU都是顺序执行的,前一条指令未执行完毕,则后一条指令必须等待着,就像我们烧水,必须洗茶壶,烧水,洗茶杯,倒水必须按照顺序来做,但是事实上烧水和洗茶杯可以同时执行,其实有很多指令也是如此,调整它们的顺序可以加快程序执行的速度
可能会造成乱序执行的原因:
- 编译器为了优化而实现指令重排(静态调度)
- CPU实现指令的多发射,以及并行执行,并为了优化实现指令的重排(动态调度)
程序的乱序执行并不意味着在所有步骤中,指令的顺序都是混乱的,事实上,指令在发射时和提交时依然是顺序的,只是在执行的过程中会打乱顺序。
为了支持乱序执行

我们在Tomasulo 算法中加入了ROB来使得提交结果的时候能够按照顺序提交,执行的结果暂时存放于ROB而不直接写入寄存器堆,然后再按顺序提交数据。从而可以不出问题。
本次的漏洞就是利用了这一特性来实现的
4 分支预测
由于在指令中存在许多跳转和分支,为了提前访问分支中的代码以解决时间,我们加入了分支预测功能
4.1 静态分支
对于所有的跳转指令,我们都预测执行跳转或者执行不跳转,则称其为静态跳转
4.2 动态分支
动态分支将会通过历史跳转信息来预测下一次分支应该选择跳转还是选择不跳转。在intel设计中有一个称为BTB(Branch Target Buffer)的部件,当我们执行分支指令时,会将执行结果和分支指令地址记录在其中,当下次取址时,查询其中的记录,若存在,则根据历史执行记录进行预测是否跳转。
若不存在此记录,我们将会使用静态分支预测器,我们一般将向上跳转的分支指令看作循环,对于循环我们倾向于接受跳转,而对于向下跳转,我们倾向于不跳转。
5 Cache结构
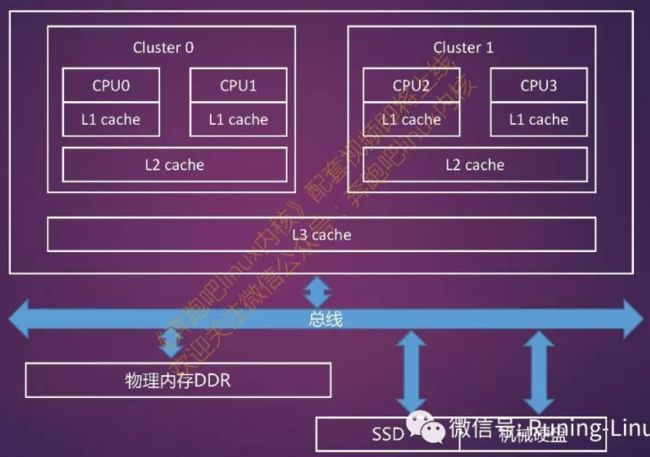
- 处理器首次访问主存上的某地址时,会将此地址所在单位大小的内容依次载入L3, L2, L1 Cache
- 短时间内,处理器再次访问这个地址时,将直接从L1 Cache读取
5 Meltdown
利用了处理器对乱序(out-of-order)执行处理不当的缺陷。现代处理器为了提高各个运算单元的利用率,不是一次执行一条指令,而是综合考虑当前指令和后续几条指令,一次批量调度多条指令到空闲的运算单元并行执行,所以代码里指令的先后关系并不一定是指令执行的先后关系。
如果用户空间一条指令读取了内核的内存地址,正常情况下该指令会导致陷入(trap),从而终止该指令的执行。但由于乱序原因,该指令后续指令可能会在trap发生之前就得到执行。如果后续是精细策划的恶意代码,就能够抓住上面提到的处理器漏洞,把“一闪而过”的内核数据“藏匿”在Cache里,偷运出去。
5.1 示例1
; flush cache
; rcx = kernel address
; rbx = probe array
retry:
mov al, byte [rcx]
shl rax, 0xc
jz retry
mov rbx, qword [rbx + rax]
; measure which of 256 cachelines were accessed首先将256条cache line清空(x86有指令),即这些cache line不包含任何内存数据。这一点有很多办法可以做到。接下来,从rcx指向的内核空间读取一个字节,存放在寄存器al里:
mov al, byte [rcx]系统会感知到你处在ring-3-level,没有权限访问内核(ring-0-level)的数据,随即抛出陷入(trap),当然al(rax的低位)的值也不会有任何敏感数据。如果没有乱序执行,一切都完美结束,一次低级的攻击企图被击破。但是乱序出英雄。由于乱序,在trap真正发生之前,处理器自作聪明地执行了后续几条指令,而且还犯了前面提到的错误,导致无可挽回的后果。
为了支持乱序执行,处理器里实际上有上百个不可见的寄存器,尽管只有16个寄存器是可见的。所以即便寄存器al(即rax)不包含内核数据,但是有一个不可见的寄存器与rax是对应的,并且处理器处理不当,把内核数据写进了这个隐藏的rax里。如果一切正常,最终这个隐藏rax会变成rax,从而完成赋值操作。但在此场景里这不会发生,因为trap的出现会终止赋值。尽管如此,在乱序执行过程中,隐藏的rax还是拥有和rax一样的地位,故后续指令里用到的rax实际上就是隐藏的rax(!!!),已经包含了内核数据(!!!)。这正是黑客梦寐以求的,接下来要做的就是在trap发生前,尽快将数据转手。
首先藏匿在Cache里:
shl rax, 0xc
mov rbx, qword [rbx + rax]所谓“藏匿”在Cache里,就是对这个字节对应的Cache Line发起一次读操作。首先将内核数据平移12位,从而指向一条Cache Line的边界(起点)。通常一条Cache Line大小是64字节,只需要平移6位就行了。平移12位是考虑到处理器的prefetch可能会一次加载进多条相邻的Cache Line,造成混淆。
后面读操作的目的是把内存里的数加载到内核数据值对应的Cache Line里,这就是个标记:Cache里其它Cache Line都是空的,唯独这个Cache Line和内存一致(up-to-date)。接下来等处理器恍然大悟,触发了trap,为时已晚,标记已经做好了,而且由于处理器的缺陷,没有清除Cache里留下的痕迹。接下来黑客可以遍历所有256根Cache Line(一个字节有256种可能性),找到刚刚做过标记的那根,比如第45根,那么刚才“窃取”的内核数据就是45。
5.2 示例2

在第一行,我们引发了一个异常,若程序按照顺序执行,第三行的access将不会被执行,但是由于程序是乱序执行的,因此在异常引发之前,第三行的access将被执行,但是执行结果存在ROB中不会被提交,当异常触发以后,第三行的执行结果将被撤销掉,从计算机外部看来第三行的access就跟从未被执行过一样,但是事实上它只是在后期被撤销了,这会带来一个小问题,就是在执行过程中,刚才读取的数据已经被存储到高速缓存中。
我们可以通过侧信道攻击来确认刚才访问的数据是什么。

这段代码揭示了攻击的关键部分
首先我们将访问内核地址并取内容到寄存器内,若这一举动可以触发异常,则对应的寄存器清零!!!,若异常未处理,则应用程序将会被终止,并且取出的值将会存入应用程序核心转储的寄存器中。我们要做的就是通过第5行将相应的寄存器清零,从而可以判断这是一个错误的值。然后再次重试,直到遇到一个不为0的值,然后将秘密的值作为地址,去做读取操作,以便cache记录到这个地址,实现侧信道攻击。
5.3 代码分析

6 Spectre

Spectre主要利用了分支预测和乱序执行的漏洞实现的,如图所示的代码,看起来十分地正常,若x小于array1的长度的时候,循环顺利执行。但是我们假设这里有一个存储密码的变量地址为secret,并且令a=secret-array1,于是我们可以使用array1[a]来表示secret的值。当多次执行循环的时候,我们的x满足循环条件,则我们的分支预测模块会认为下一个循环也满足循环条件而去预执行这个循环,若此时我们将a的值赋值给x,则分支预测模块预测本次循环为执行(其实并不会执行),CPU会预执行这个循环体,然后将我们存储密码的secret值取出来,并将其作为地址去访问array2,但是最终发现循环不应该被执行,于是刚才取出来的值将会被作废。但是我们的这个secret值的地址已经被存入到缓存中去。我们最终可以将array2读取一遍,若读取某个地址的时候,访问的时间特别短,则说明这个地址就是那个被存入缓存的地址(即我们的密码值)。
7 参考
https://googleprojectzero.blogspot.co.at/2018/01/reading-privileged-memory-with-side.html
https://lwn.net/Articles/738975/
http://lib.csdn.net/article/linux/29085
https://bugs.chromium.org/p/project-zero/issues/detail?id=1272
http://blog.csdn.net/yiyeguzhou100/article/details/72875122
https://bbs.pediy.com/thread-61327.htm
http://blog.csdn.net/muxiqingyang/article/details/6686738