BS-1python基础知识-1.9 面向对象
面向对象
- 面向对象
- 抛开代码,从分析实际问题去理解面向对象
- 封装、继承、多态是面向对象的三个典型特征
- 封装
- 继承
- 多态
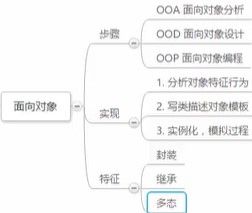
- OOA(Object-Oriented Analysis)面向对象分析
- 分析对象
- OOP 面向对象设计
- 写类:class,描述对象模板
- OOP 面向对象编程
- 实例化(内存对象),模拟过程
- 面向对象三个步骤
- 举例说明1
- 上面的例子,问题细化一下
- 举例说明2,类的属性
- 举例说明3,类间的关系:继承和包含
面向对象
抛开代码,从分析实际问题去理解面向对象
1.面向对象的优势代码的扩展和维护
2.尽量以符合人的思维习惯去分析问题、分解问题、解决问题
算法和数据结构重要,但不是最重要的东西
3.什么是对象?万物皆对象, 对象有特征,有行为,
先关注两个东西:他的特征,他的行为。特征和行为,分析。即:有什么,能做什么
没有最好的分析,只有相对合理的分析。
对象之间有什么关系?
把平时分析的这些东西融入到项目中,面向对象编程就是水到渠成的。面向对象编程的代码是为我们的分析服务的。
4.举例说明,引出问题:
建立一个图书管理系统:
先抛开代码
系统里可能会参与哪些角色?哪些对象?
这些对象有什么特征,属性,识别
分析这些对象之间有什么关系,组织好他们之间的关系
用代码去实现
第一步,新建一个项目,将其定位到一个目录。
第二步,在目录中新建一个.py文件,在文件中写入内容
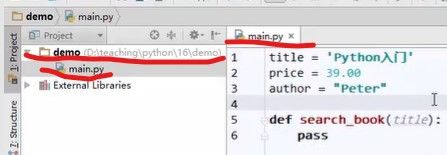
提出问题:
上面.py文件中定义出来的title,price,author,search这些信息都是图书的一些特征/行为,但是这样写不能把他们当作一个整体去对待,只是面向过程的声明的一些函数或者变量。要想办法将他们封装起来:
封装、继承、多态是面向对象的三个典型特征
封装
封装是最简单的一个,
就是把松散的这些字段(我们认为这些字段是有联系的,属于同一个对象的不同成员)封装到一个对象中。比如把一些行为定义到函数中也称之为封装。
或者,把某一个对象所具备的行为能力写到方法里面,或者是写到函数里面,以便于重用和扩展,或者,把分析出来的对象写成类,也是封装。
封装的主要目的是封装逻辑单元,提高代码的重用性,可扩展性,降低代码冗余。
1.方法一:使用python内置好的数据类型
接上面的例子:
第三步,把信息都塞到列表中,定义列表,
列表中什么都能装,字符串、数值都能装。
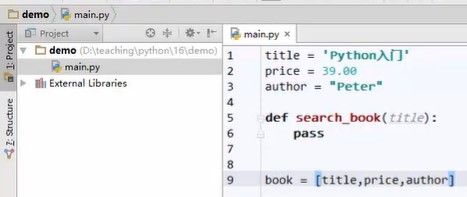
但是,用起来麻烦,比如要遍历时,找出其中的元素做进一步处理时,列表中的类型不一致,title只能支持字符串的操作,price只支持数值操作,
第四步,用字典表封装。

在python里面,先把对象分析出来,面向对象分析OOA(Object-Oriented Analysis),
继承
提高代码重用
两个或两个以上的类之间有一些重叠的部分, 又继承的关系,通过代码在一定程度上实现,利用代码重用。
多态
属于同一类型的不同实例,对同一个消息做出不同的响应能力。
OOA(Object-Oriented Analysis)面向对象分析

面向对象分析涉及到那些东西?
分析对象
从日常人的思维习惯去分析对象及其特征(包括行为特征),对象之间的关系
把你所关心的信息列出来,
万物皆对象,有实体,也有感觉到的非实体(一个想法),
分析对象的特征,行为。
统计完对象的特征之后,再去分析对象之间的关系
从编程角度看,这些关系是特定的,python中总结出来了
构成关系:车门和车轮组成公交车
包括:复合和聚合
扩展:UML类图关系
OOP 面向对象设计
写类:class,描述对象模板
目的就是把分析出来的对象写成代码
类定义对象代码模板(蓝图)
类:class
将上面的对象的特征定义成类的成员:
举例说明:
将分析的“书”这个对象的特征“标题,定价,作者”写成“class book”:title,price…
class只是一个模板,蓝图:只是知道用途时一个对象,我关心什么?想要表示一本实实在在的书,怎么办?就要创建对象,即:实例化
OOP 面向对象编程
实例化(内存对象),模拟过程
描述一个具体的,实实在在的
附上值,
定义类的成员
1.举例说明
类的命名,与python语言其他命名不同,用帕斯卡命名法大写字母开头,
有多个单词组成,不用加下划线,就连着写
内部成员变量,都是小写,以下划线分隔。
第一步, 定义一个类

第二步:写下实在的一本书,指定书的信息
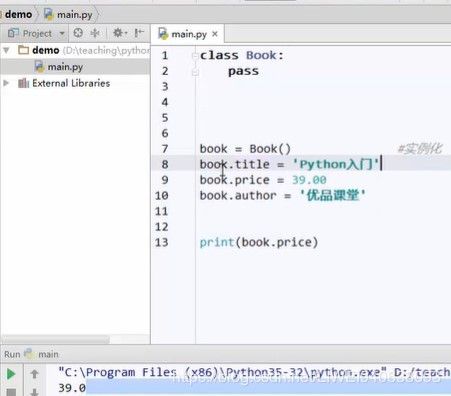
class Book()中什么都没写,只是在下面依附于Book类定义了函数,也依然可以运行。
但是这样还是比较松散
第三步:想要看起来更舒服,将定义的那些函数塞到类里面,一看就可知道有哪些信息要填写。
3.1.python中有一类函数,双下划线开头,双下划线结尾,def,称之为预定义的,predefined,python里面事先准备好的,有特定意义和功能的。
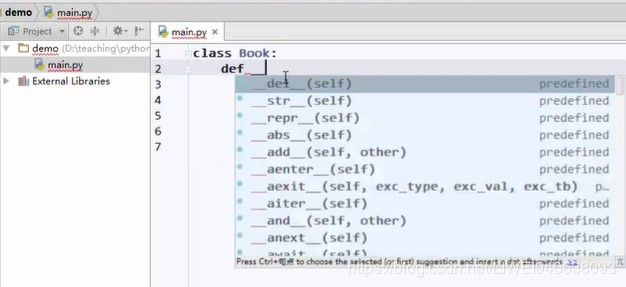
3.2 先定义初始化函数,又叫初始化器。init(self)
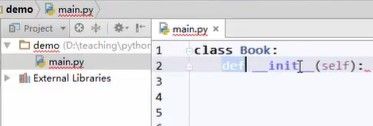
**为什么会有初始化器?
是构造函数,给具体的对象实例赋值用的,
self表示不同的实例,实例化时,在book1上去调用self时就表示book1,在book2上去调用self时就表示book2。**写self是因为写名称时不知道具体调用的是什么
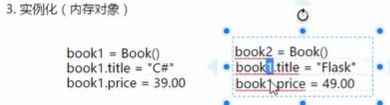
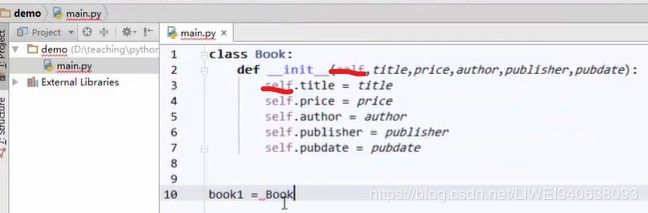
如上图:定义了book的许多特征,封装在了class Book中。定义了对象的特征,他有什么。
book这本书有许许多多不同的实例,
3.3 实际调用

pubdate,时间这里,需要调用一个datetime模块,其中有一个datetime.date函数,

这样就创建了book1这个实例,self就表示book1,
book1 = Book()这样写,就相当于调用(执行)了前面的__init__函数,
3.4. 定义了Class Book有什么(特征)之后,再去定义Class Book能做什么(函数)
在类里面定义函数,默认情况下加上(self)
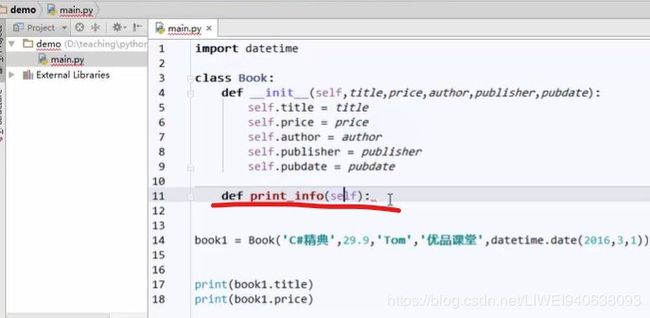
定义的函数不用再在前后加下划线
def print_info(self)的意思是:这个方法以后如何去调用?通过这个实例book1去调用。
def print_info(self)中的self 可以去掉/更改,后面在不同场景下有区别地去改。
写类的时候不会知道这本书的标题是什么,只有在创建实例的时候才具体知道,因而定义函数时候只能从宏观上去说

调用时直接用:book1.print_info()
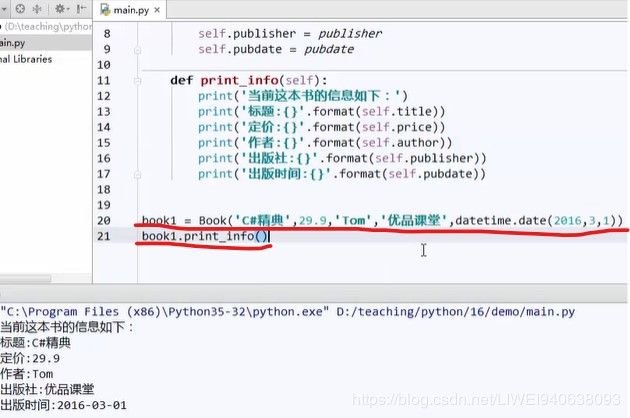
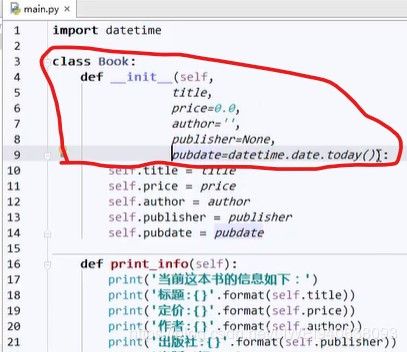
类中的初始化函数具备函数的特征,可以在函数的参数中定义默认值,因而类的函数就可以不填,用初始化函数的默认值:

再定义类的新函数:这个函数中只给了title值,其他的前面初始化函数给了默认值,这里不给也不会报错。
后面要打印出来,要加上book2.print_info()

觉得函数太长,还可以换行:
book2 = Book('Flask入门到精通‘),book2这个函数定义之后,还可以在函数中更改添加。再打印出来就是最新信息。
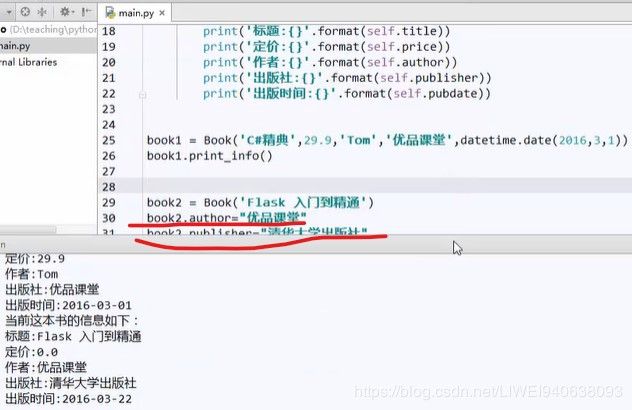
3.5.python中一些没有明确表达出来的数据类型,打印出来不像明确的数据类型一样

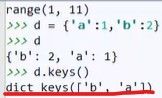
而在类中,接上面的例子:构建好类和类的内容(特征和函数)后,
在console中,定义Book类的新内容book3:

就写一个book3,后面什么都不写,出现上面那个结果:
main.Book object at 0x03003199: main模块中的Book 对象在 0x03003199这个位置。
print(book3)的结果,也是 main.Book object at 0x03003199,
3.6 改造一下:在定义这个Book类的时候,就决定了在交互式提示符上,打印一个实例,而不是打印属性/字段时候该怎么呈现:用函数__repr__(self),英文时represention,表现:定义了这个对象,如果在交互式提示符下来显示的话,该怎么显示,返回一个字符串就可以:return ’<图书 {}>’.format(self.title)
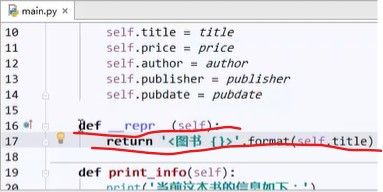
更改Book类的内容后,更新一下:

import.reload(main)
import main:导入整个模块

book = Book('ASP.NET')#这样导入就没说清楚导入模块main的什么内容
book = main.Book('ASP.NET') #正确

# 写入book,呈现<图书 ASP.NET>
也可以改造,将print_info(self)的内容整个当作字符串返回。
面向对象三个步骤
1分析2设计3编码
实操过程:
分析对象特征行为,写class来定义它,class的成员通过__init__写到里面,通过构造函数传一些参数交给他实际成员的值。
举例说明1
1.创建一个项目:(分析对象)
假设做一个图书管理系统,先抛开代码。从思想上分析出来,从简单到复杂,先分析可能会涉及到哪些对象?
可能会有图书,作者,出版社。图书,要关注他的标题,定价,出版时间,
代码层面:
2.写类:Class Book (写类去描述并实例化)
class类下面都缩进,是类的成员。
类的成员:python是动态类型,数据类型不是由变量类型决定(即声明时候)。声明变量时,不赋值意义也不大,所以先写一个构造函数:双下划线开头,双下划线结尾(predefined—预定义的,有特殊功能)。
构造函数:初始化器,init(self):initialize
Class Book: #第2部分:Class下面都缩进,缩进部分就是类的成员
def __init__(self,title,price=0.0,author=none): # 1.类下面要声明变量,声明变量时不赋值意义不大,所以先写一个构造函数。构造函数:__init__(self),initializer,初始化器.在下面写上类自己的成员,函数内容要缩进.2.__init__构造函数里面,self后面,要初始化的值直接传递过来,title,price,author.3.然后将这些传递过来的值交给类的内容去赋值,4.值的内容不填的话,可以给一个默认值,比如price=0,5.带有默认值的参数必须放在命名参数的后面,即author没有默认值,那就移到price的前面,6.
self.title = title #1.自己的名,2.传递过来的值交给交给类的内容去赋值,3.当前的标题等于传过来的标题
self.price = price #自己的定价,类的成员可以随意增减
self.author = author
# 第4部分,加上类的行为——函数.比如说打印信息,就是print。写print_info,避免与地下的print冲突.这样就具备行为了。
def print_info(self.title,self.price,self.author)#这样,如果在想显示,就不用自己写print了,直接写刚才实例的print_info()
print(self.title,self.price,self.author)
# 第3部分.将类的内容写到main方法中,去创建实例。
if __name__ == '__main__':
book = Book('python经典’) # 1.第一本书就来于前面那个模板把他变出来的,2.之前定义时候,有三个参数,所以至少没有给默认值的参数要填,3.填上参数:title=python经典,这就有了一个实例,真正把他实例化了,4.这时可以随意看,price是什么,5.从这里看,与字典表没啥区别,就是封装了一些字段
print(book.price)
book.print_info() #上面的print(book.price)就不用了。
- 定义好一个类,类中有三个成员要关心,这时候的类只是一个模板,不代表具体的一本书。
将其写到main方法中,创建实例。
4.从这里看,类与字典表没啥区别,就是封装了一些字段。
加上行为——函数

5.以上为最简单的类。接下来考虑一些问题:
Class定义的 Book相当于一个数据类型(python把所有东西都以面向对象形式封装了).
在控制台console,重新导入当前的模块。注释掉__main__方法,去掉实例。
在console:
import main #导入模块
b = main.Book('Python') #创建实例,构造一个函数,main.Book(),声明一本书,叫做python。
b.price #price有默认值,所以不用写参数就会有值。
b #直接输入b,出现结果如下图,显示。但是显示这个没用,要显示出有用信息构造一下,用__repr__()函数,(英文representation表现),
直接输入b的结果图:

class Book:
def __init__(self,title,price=0.0,author=None):
self.title = title
self.price = price
self.author = author
#直接输入b,显示信息没用。要显示出有用信息须构造一下,用__repr__()函数,(英文representation表现)
def __repr__(self): #在里面返回一个字符串
return '<图书:{}>'.format(self.title)
#想显示位置信息
def __repr__(self):
return '<图书:{} at 0x{}>'.format(self.title,id(self))
def print_info(self):
print(self.title,self.price,self.author)
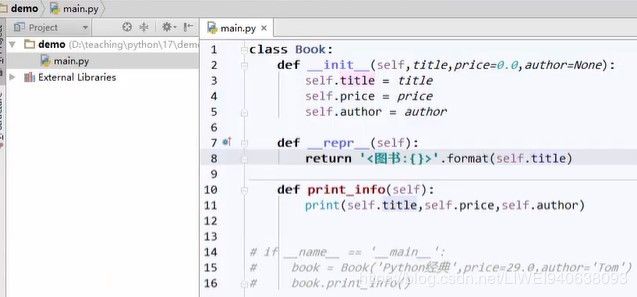
更改之后,在console中调用:
# 用importlib包的reload函数更新main模块更新后的内容,重新载入
import importlib
importlib.reload(main)
b = main.Book('ASP.net') #重新构造一个Book函数,显示出有用信息

实际开发中,__repr__函数是有用的,在console上测试时,想看到某个集合中某本书的信息。
__repr__给开发人员用的,调试时用的,
print(b))的结果和上面一样,原因是没有写str函数,写了str函数,显示的就是str函数的内容。
![]()
写入str函数
class Book:
def __init__(self,title,price=0.0,author=None):
self.title = title
self.price = price
self.author = author
def __repr__(self):
return '<图书:{} at 0x{}>'.format(self.title,id(self))
# 写入str函数
def __str__(self):
return '[图书:{},定价{}]'.format(self.title,self.price)
def print_info(self):
print(self.title,self.price,self.author)
控制台上调用print(b),显示结果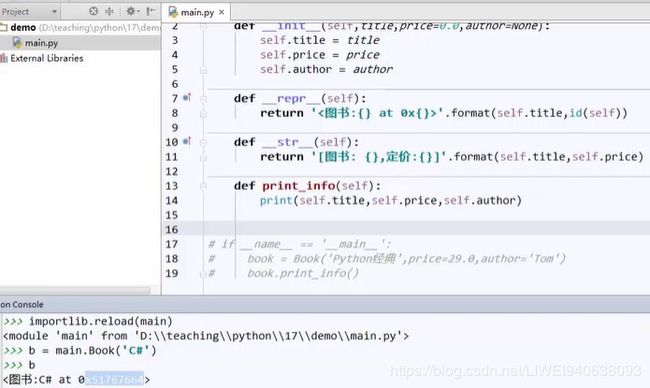
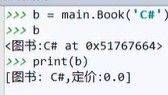
print(b)和对应的__str__是给普通用户看的。b和对应的__repr__与是给开发人员用的,他们两者本质相同。
上面的例子,问题细化一下
1.self是实例化的具体对象,因而在调用时候直接传值。self是指实例化的对象,即具体化的书book,而不是定义的那个类Book。

2.假定图书要创建很多实例,再创建book2,book3,然后统计共有多少本书
class Book:
def __init__(self,title,price=0.0,author=None):
self.title = title
self.price = price
self.author = author
def __repr__(self):
return '<图书:{} at 0x{}>'.format(self.title,id(self))
def __str__(self):
return '[图书:{},定价{}]'.format(self.title,self.price)
def print_info(self):
print(self.title,self.price,self.author)
if __name__ == '__main__':
book = Book('Python经典',price=29.0,author='Tom')
book2 = Book('Flask')
book3 = Book('ASP.net')
加上一个字段成员,描述有几本书:(这里的操作不正确)
class Book:
def __init__(self,title,price=0.0,author=None,count=0): #在初始化函数中加count参数
self.title = title
self.price = price
self.author = author
self.count = count # 图书的数量等于传递过来的参数count。在创建一本书的实例时候,要统计,就要加上1
def __repr__(self):
return '<图书:{} at 0x{}>'.format(self.title,id(self))
def __str__(self):
return '[图书:{},定价{}]'.format(self.title,self.price)
def print_info(self):
print(self.title,self.price,self.author)
if __name__ == '__main__':
book = Book('Python经典',price=29.0,author='Tom')
book.count += 1 # 创建了一本书的实例,统计加上1
book2 = Book('Flask')
book2.count += 1
book3 = Book('ASP.net')
book3.count += 1
print('图书数量:{}'.format(book3.count))
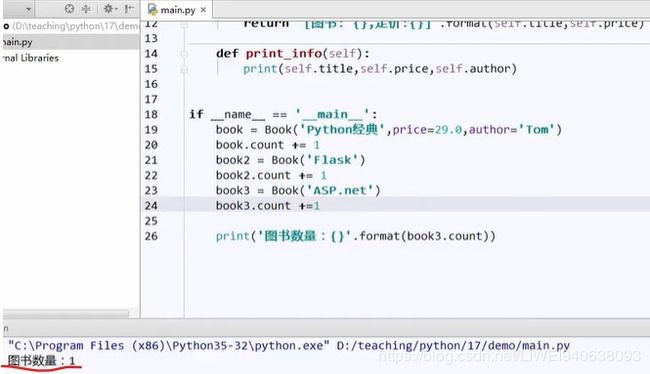
有三本书,最后统计结果只有1本书,从宏观角度分析:
将count写进类中的初始化函数后,每次实例化就会把count作为每个实例的自己的特征,就是每个实例都会有自己的count,所以统计的都是每个实例自己的数量,不能统计总体数量。想办法将count做成全局的,不依附于一个实例化对象。

如何定义count:
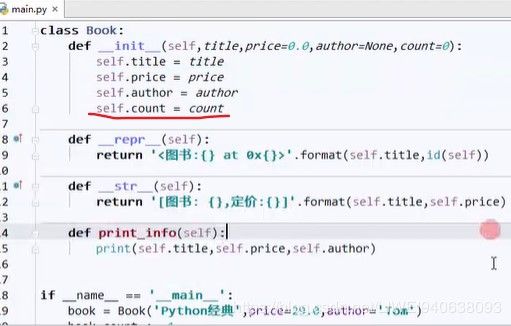
定义count时候必须定义到class里面,否则无意义。
self表示实例,加上self就会具体到每个实例,所以不能加self。
和实例无关的不要加到__init__中,前面不加self。但是要写到类里面 既是属于书的信息,但是又不是跟单个书相关。
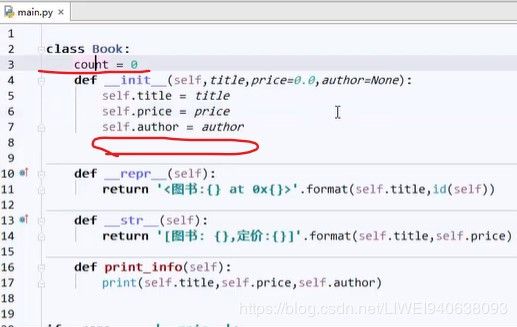
什么时候加1?注意要写成全局的count,即整个类的count,Book.count,不能写成某一本书的count,

代码呈现:
class Book:
count = 0 #和实例无关的不要加到__init__中,前面不加self。但是要写到类里面
def __init__(self,title,price=0.0,author=None):
self.title = title
self.price = price
self.author = author
def __repr__(self):
return '<图书:{} at 0x{}>'.format(self.title,id(self))
def __str__(self):
return '[图书:{},定价{}]'.format(self.title,self.price)
def print_info(self):
print(self.title,self.price,self.author)
if __name__ == '__main__':
book = Book('Python经典',price=29.0,author='Tom')
Book.count += 1 # 创建了一本书的实例,统计加上1.全局的count,即整个类的count,Book.count
book2 = Book('Flask')
Book2.count += 1
book3 = Book('ASP.net')
Book3.count += 1
print('图书数量:{}'.format(book3.count))
规划类的成员时要分清楚,1这个成员是全局的class的特征,称为全局成员,2还是具体到每个实例化对象的特征全局class的特征要拿到初始化函数外面,实例化对象的特征放到初始化函数里面。
3. 上面代码比较繁琐,改进代码。
3.1不是手动加1,让其自动加1
3.2想要销毁一个对象,python全局函数del,同时删除以后还能统计出来,需要新构造一个类的函数__del__
class Book:
count = 0
# 初始化执行
def __init__(self,title,price=0.0,author=None):
self.title = title
self.price = price
self.author = author
Book.count += 1 # 将class Book的统计放进来
# 删除对象执行
def __del__(self):
Book.count -= 1
# 在控制台上直接写对象时执行
def __repr__(self):
return '<图书:{} at 0x{}>'.format(self.title,id(self))
# 在控制台上打印时执行
def __str__(self):
return '[图书:{},定价{}]'.format(self.title,self.price)
def print_info(self):
print(self.title,self.price,self.author)
if __name__ == '__main__':
book = Book('Python经典',price=29.0,author='Tom')
book2 = Book('Flask')
book3 = Book('ASP.net')
del(book3)
print('图书数量:{}'.format(Book.count))
全局的静态变量通过全局对象调用(classBook),也可以通过实例化对象调用,但是,如果实例化调用只是用不改的话,结果值和全局对象调用的结果是一样的,如果改了的话,就不是全局的了,就是实例化对象自己的了
结果示例如下:
0
再进一步:
写一个函数,只跟class Book全局有关(全局静态函数,类函数,静态方法,跟实例化对象book无关(self,实例函数),方式:
class Book:
count = 0
def __init__(self,title,price=0.0,author=None):
self.title = title
self.price = price
self.author = author
Book.count += 1 # 将class Book的统计放进来
def __del__(self):
Book.count -= 1
def __repr__(self):
return '<图书:{} at 0x{}>'.format(self.title,id(self))
def __str__(self):
return '[图书:{},定价{}]'.format(self.title,self.price)
def print_info(self):
print(self.title,self.price,self.author)
# ()中什么都不写.写静态函数,与实例无关,()中不写self就可以
def static_method():
print('静态函数,逻辑上与实例无关')
if __name__ == '__main__':
book = Book('Python经典',price=29.0,author='Tom')
book2 = Book('Flask')
book3 = Book('ASP.net')
#del(book3)
#print('图书数量:{}'.format(Book.count))
Book.static_method()
4.实际开发中,一些信息不是填直接选的,要做过滤处理,构造一个过滤函数
举例说明:
4.1. 一个人的年龄是变化的,取得这个人的年龄需要构造一个函数,间接计算得到
import datetime #显示日期的标准库
class Student:
def __init__(self,name,birthdate):
self.name = name
self.birthdate = birthdate
# 构造一个类的函数,间接计算得到这个人的年龄
def get_age(self):
return datetime.date.today().year - self.birthdate.year
if __name__ == '__main__':
s = Student('Tom',20,datetime.date(1992.3.1))
print(s.birthdate)

4.2 单独写一个叫做属性的东西:@property,还可以做进一步过滤
import datetime #显示日期的标准库
class Student:
def __init__(self,name,birthdate):
self.name = name
self.birthdate = birthdate
# 写一个属性
@property # 写一个装饰器,表明这是一个属性。写内容时候用函数来定义
def age(self): #这个函数的功能和方法1中的函数是一样的
return datetime.date.today().year - self.birthdate.year
# 进一步过滤
@age.setter #setter设置器
def age(self,value): 虽然与上面定义的函数名一样,但是用@装饰器区分开了,用参数value来传输值
# 防止更改年龄,不允许随意赋值
raise AttributeError('禁止赋值年龄!') #用raise AttributeError来禁止他人给age赋值
# 防止删除年龄
@age.deleter #删除器
def age(self):
raise AttributeError('年龄不能删除!')
if __name__ == '__main__':
s = Student('Tom',datetime.date(1992.3.1))
print(s.birthdate)
print(s.age) # 直接写s.age,age就是s的一个属性
s.birthdate = datetime.date(1982,8,2) #更改datetime,重新赋值,打印结果见下图
del(s.name) #删除class Student的name,类的属性可以在初始化函数外面删除,使其打印不出来
print(s,name)
构造类初始化函数时候(赋予特征),只定义了name,birthdate,
后面打印age时,没有按照使用方法的形式去打印,而是按照打印属性的方式,是因为加了一个装饰器就变成了类的属性,用属性可以更严谨保证数据完整性属性就可以更改了
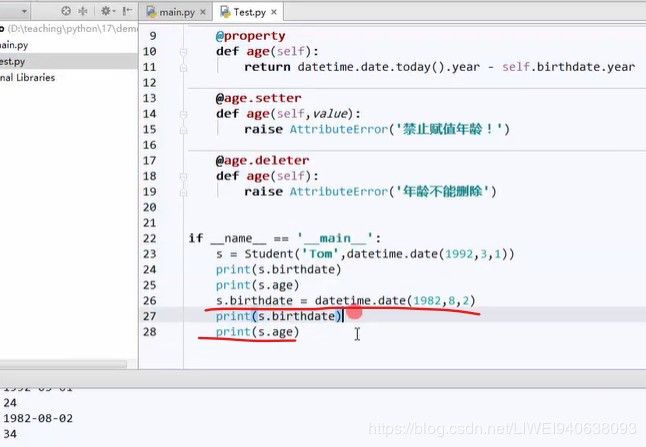
删除class Student的属性name

举例说明2,类的属性
用一个类来表示圆:圆作为一个对象,圆这个对象特征有半径,根据半径取面积和周长,把这些封装到一个类中
import math
class Circle:
def __init__(self,radius):
self.radius = radius
# 要计算圆的面积,可写一个方法,
def get_area(self): # 1.方法里面不用接收参数,因为pi在标准库中就有,导入math模块2.这个操作是一个行为,计算公式固定,3.得到圆的面积时能否像得到字段一样?可使用属性来声明属性的本质是一个函数,用起来像字段
return math.pi * self.radius**2
c = Circle(4.0) # 这里内置到了脚本中,这一步也可以直接在console中操作
print("圆的面积是:{}".format(c.get_area()))
更改类的行为为属性
import math
class Circle:
def __init__(self,radius):
self.radius = radius
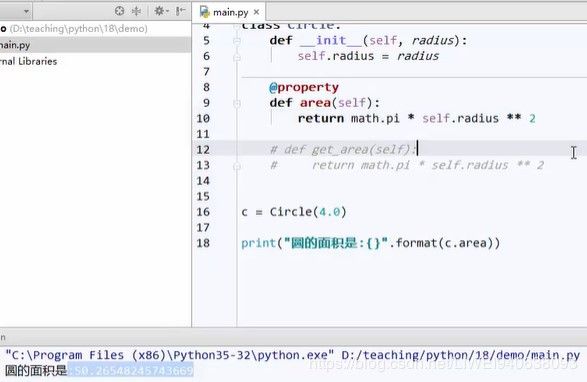
# 要计算圆的面积,可写一个属性.属性中的逻辑和类的方法中一样,但是加上@property后就可以像属性一样。本质上还是一个函数,只是加了@property。
@property
def area(self):
return math.pi * self.radius**2
c = Circle(4.0)
print("圆的面积是:{}".format(c.area)) #调用时也跟类的属性一样,调用一个字段
举例说明3,类间的关系:继承和包含
案例:模拟一个公司的内部员工工作的场景,用面向对象编写这个程序。
先抛开代码,抛开流程图
在写类本身的时候就是一个数据结构,
1.分析
假定,公司中有一些部门,不同类型不同职位的员工。
把每一个员工都用一个类来描述,写一个描述经理的类,一个程序员类,一个hr类。
写类时候要关注他们公共的信息,比如name,所属部门,薪资多少。还有一些职位所特有的,程序员会有自己掌握的语言,参与的项目等,不同职位人员有不同职业特征。
以上,可以用上继承。
2.编程
2.1 把共性的特征拿出来,单独写成一个类,就叫员工。员工的一些细节不知道,只知道其所在部门,姓名,年龄,生日,
2.2 **写派生类:子类。**比如说程序员
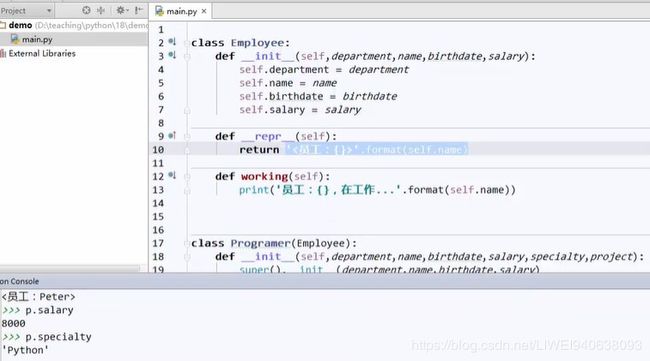
# 2.1把共性特征拿出来,单独写成一个类员工。当作基类:基本类信息
class Employee:
def __init__(self,department,name,birthdate,salary): #初始化工作
def.department = department
self.name = name
self.birthdate = birthdate
self.salary = salary #类中的成员都是跟Employee关系密切的成员,所以写到类里面,前面协商self;如果跟Employee类没啥关系,是全局性的,就写到类外面,不加self
# 接下来类的行为
#行为,console上打印时候,print,显示基本信息
def __repr__(self):
return '<员工:{}>'.format(self.name)
# 员工工作的行为
def working(self): #working是自己定义的,前后不加下划线
print('员工:{},在工作...'.format(self.name))
# 2.2接下来可写一些派生类,子类信息
# 程序员类,是员工的一种。前面员工类的信息不用写,直接继承
class Programer(Employee): #括号中写上要继承的基类,表明Programer这个类继承自Employee这个类
def __init__(self,department,name,birthdate,salary,speciality,project): #定义Programer自己的构造函数,又叫初始化器。Employee中已经有的在这里不用再构造了,但是初始化参数中还是要填。
super().__init__(department,name,birthdate,salary) # super指基类/超类。调用他自己的有一个叫__init__,把基类中写好的交给他去初始化。剩下自己特有的特征自己去构造
self.speciality = speciality
self.project = project
def working(self): Programer类中的working与基类中的working不同,体现多态。这里就不想基类中只是粗略地说在工作,工作内容就具体了。
print('程序员:{}在开发项目:{}...'.format(self.name,self.project)
在console中操作:
import main
from main import * # 这个方法,如果main中代码更改后,不能重新导入,还是用import main
import datetime #构造birthdate时须用到日期时间,所以导入datetime模块
import # 要改动代码的话,要重新导入。所以导入importlib模块
p = main.Programer('技术部','Peter','datetime.date(1990,3,1),8000,'Python','CRM') #刚才导入的是main整个模块,所以不能直接写 .在括号中填入构造函数的参数.填入参数之后就可以在console中查看各项的值了。显示如下图
以上,完成了基类和派生类的定义。
2.3 接下来,改动
在基类中加上调整工资的方法
import datetime
class Employee:
def __init__(self,department,name,birthdate,salary):
def.department = department
self.name = name
self.birthdate = birthdate
self.salary = salary
# 2.3在基类中加上调整工资的方法
def give_raise(self,percent,bonus=.0): #写上具体调整的工资比例,加入参数percent.额外奖金数额,bonus
self.salary = self.saary*(1+percent+bonus) #调用这个方法后,salary就不是class Employee传进去多少就是多少了
def __repr__(self):
return '<员工:{}>'.format(self.name)
def working(self):
print('员工:{},在工作...'.format(self.name))
# 想获得age这个属性,但是age不能直接得到,须间接计算.就须用到@property
@property 某个值需要通过计算得到,且不允许直接赋值,这就使用属性。
def age(self):
return datetime.date.today().year - self.birthdate.year
class Programer(Employee):
def __init__(self,department,name,birthdate,salary,speciality,project):
super().__init__(department,name,birthdate,salary)
self.speciality = speciality
self.project = project
def working(self):
print('程序员:{}在开发项目:{}...'.format(self.name,self.project)
# 将console中调用过程写入脚本中。运行写入main函数中。datetime模块导入
if __name__ =='__main__':# 如果当前运行的这个模块名称是等于主模块main,即脚本正在以当前模块运行的话。函数内容构造实例
p = Programer('技术部','Peter',datetime.date(1990,3,3,),8000,'Flask','CRM') # 程序就在main模块中,所以不用再调用。
print(p) # 调用str函数,这里没写,就会调用__repr__函数
print(p.department) #看某项信息,直接写
print(p.salary)
p.give_raise(.2,.1) # 调整工资
print(p.salary)
p.working()
print(p.age) # 实例化函数参数中的birthsate改变后,这里也会跟着变。
显示结果如下: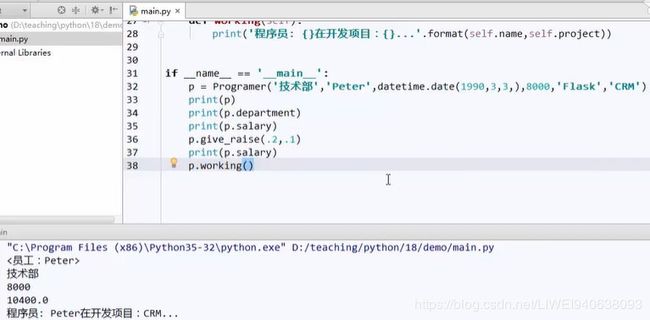
2.4.继承多类
import datetime
class Employee:
def __init__(self,department,name,birthdate,salary):
def.department = department
self.name = name
self.birthdate = birthdate
self.salary = salary
# 2.3在基类中加上调整工资的方法
def give_raise(self,percent,bonus=.0): #写上具体调整的工资比例,加入参数percent.额外奖金数额,bonus
self.salary = self.saary*(1+percent+bonus)
def __repr__(self):
return '<员工:{}>'.format(self.name)
def working(self):
print('员工:{},在工作...'.format(self.name))
def age(self):
return datetime.date.today().year - self.birthdate.year
class Programer(Employee):
def __init__(self,department,name,birthdate,salary,speciality,project):
super().__init__(department,name,birthdate,salary)
self.speciality = speciality
self.project = project
def working(self):
print('程序员:{}在开发项目:{}...'.format(self.name,self.project)
# 2.4继承多类。上一个子类Programer构造函数内容,使用super会出现问题:假设还有一个类,就会含糊不清,不知道继承的哪个类。调用基类构造函数时,直接明确写出来调用的基类,
class HR(Employee):
def __init__(self,department,name,birthdate,salary,qualification_level=1):
Employee.__init__(self,department,name,birthdate,salary,) # 加上self,
self.qualification_level = qualification_level
def working(self): #定义HR类自己的行为
print('人事:{}正在面试新员工...'.format(self.name))
p = Programer('技术部','Peter',datetime.date(1990,3,3,),8000,'Flask','CRM') # 程序就在main模块中,所以不用再调用。
print(p) # 调用str函数,这里没写,就会调用__repr__函数
print(p.department) #看某项信息,直接写
print(p.salary)
p.give_raise(.2,.1) # 调整工资
print(p.salary)
p.working()
print(p.age) # 实例化函数参数中的birthsate改变后,这里也会跟着变。
# 构造hr这个实例
hr = HR('人事部','Marry',datetime.date(1992,4,4),6000,qualification_level=3)
hr.give_raise(.1)
print(hr.salary)
hr.working()
一些思考
之前写的所有类,所有的成员字段都是使用框架里python内置好的数据类型。
存一些特殊的:
比如员工的考勤:一个月中,一号全勤,二号早退,三号迟到,可以用字典表来存储
并列的可用列表存储
搞不定的可以写类,类也是一种数据类型
2.5. 考虑另外一种场景,叫做有关联的。类间关系
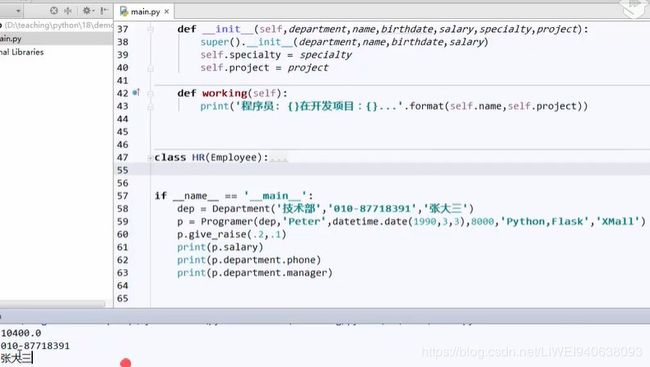
前面的例子中,有基类和派生类。基类和派生类中都有department这个特征,department中有一些信息要进一步分析,比如部门电话,房间号,可以将部门拉出来单独写一个类。
import datetime
# 2.5将员工特征department作为一个类,并将其用到员工中
class Department:
def __init__(self,department,phone,manager):
self.department = department
self.phone = phone
self.manager = manager
def __repr__(self):
return '<部门:{}>'.format(self.department)
class Employee:
def __init__(self,department:Department,name,birthdate,salary):#department:Department 就是告诉别人department这个参数从Department这个类导入
def.department = department
self.name = name
self.birthdate = birthdate
self.salary = salary
def give_raise(self,percent,bonus=.0):
self.salary = self.saary*(1+percent+bonus)
def __repr__(self):
return '<员工:{}>'.format(self.name)
def working(self):
print('员工:{},在工作...'.format(self.name))
def age(self):
return datetime.date.today().year - self.birthdate.year
class Programer(Employee):
def __init__(self,department,name,birthdate,salary,speciality,project):
super().__init__(department,name,birthdate,salary)
self.speciality = speciality
self.project = project
def working(self):
print('程序员:{}在开发项目:{}...'.format(self.name,self.project)
# 2.5 class Programer里面可能会定义一个xxx处理项目的函数,里面有一些角色,这些角色是之前已经定义好的员工类。搞清楚类间关系
def xxx(self,dev,aa,ccc)
dev.xx.start.sd # 开发人员的行为。所以看别人的代码,看到....不要糊涂,有可能就是使用了面向对象,定义好的对象相互串联,
class HR(Employee):
def __init__(self,department,name,birthdate,salary,qualification_level=1):
Employee.__init__(self,department,name,birthdate,salary,) # 加上self,
self.qualification_level = qualification_level
def working(self): #定义HR类自己的行为
print('人事:{}正在面试新员工...'.format(self.name))
# new一个department的实例,
if __name__=='__main__':
dep = Department('技术部','010-87718391','张大三’) #构造一个Department实例
p = Programer(dep,'Peter',datetime.date(1990,3,3),8000,'Python',Flask','XMall') # 构造Programer实例,并调用dep
p.give_raise(.2,.1)
print(p.salary)
print(p.department) #打印结果如下图,无用信息。原因:department本身就是一个实例,但是没有定义str,repr函数。那么想打印出来有用信息,在calss Department中定义一个__repr__函数
print(p.department.phone) #打印出这个部门的电话
print(p.department.manager)
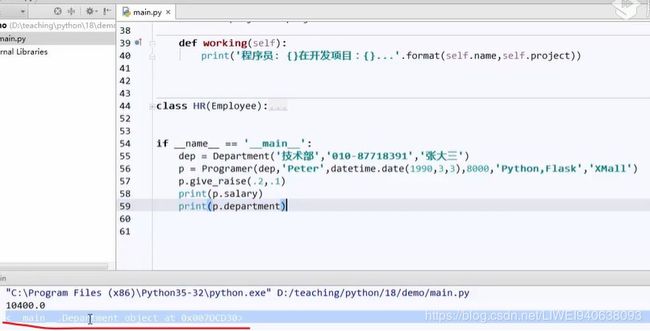
2.5 思考:
在某个员工类下面做一个项目过程的行为,项目过程中有很多角色参与进来:项目经理,产品经理,开发人员,
比如说,class Programer里面可能会定义一个xxx处理项目的函数,里面有一些角色,