CVPR 2019 | 旷视研究院提出实时语义分割技术DFANet:高清虚化无需双摄

全球计算机视觉三大顶会之一 CVPR 2019 (IEEE Conference on Computer Vision and Pattern Recognition)将于 6 月 16-20 在美国洛杉矶如期而至。届时,旷视研究院将远赴盛会,助力计算机视觉技术的交流与落地。在此之前,我们将逐一对旷视研究院被 CVPR 2019 接收的论文进行解读。本文是第 4 篇解读,旷视研究院AI影像(LLCV)组提出一种实时语义分割技术——DFANet,不仅减小了 7 倍计算量,突破实时计算边界,而且无需双摄也可实现手机图像的高清虚化。

 论文名称:DFANet:Deep Feature Aggregation for Real-Time Semantic Segmentation
论文名称:DFANet:Deep Feature Aggregation for Real-Time Semantic Segmentation
论文链接:https://share.weiyun.com/5NgHbWH
导语
简介
方法
高层语义特征的充分利用
聚合让轻量级编码器受益
实验
7 倍轻量依然准确
结论
参考文献
往期解读
导语
很多手机没有双摄像头,也能实现美轮美焕的背景虚化效果,究其原因,是语义分割技术在发挥作用。目前,已有过亿用户使用搭载有旷视所提供的深度算法的个人终端产品,而旷视研究院语义分割技术的最新成果——DFANet,已为全球计算机视觉顶会 CVPR 2019 所收录。本文的解读将提前公开产品背后的“秘密”。
简介
图像的语义分割需要对标签做逐像素的预测,例如判断一个像素属于前景/背景,又或是道路/车辆/行人等。随着移动互联网、物联网、5G 等技术的到来和普及,在计算力受限的设备上进行高分辨率的语义分割就成为了一个迫切需求。
然而,当面对高分辨率输入时,深度卷积网络经受着巨大挑战:网络容量(运算量)和速度之间很难有一个 tradeoff。例如,对于移动端处理器,实际可用的计算能力可能只有数十 GFLOPs,而一但要求跟上视频计算的速度(如 30fps),每一帧分配的计算量就更少得可怜。在如此少计算量的限制下,神经网络的精度的“涨点”之路可谓举步维艰。
有没有什么方法可以在高输入分辨率、小计算量的情况下依然获得很高的分割精度呢?这正是旷视研究院最新力作 DFANet 的目标所在。
相同精度下,DFANet 可相较先前方法减少 7 倍的计算量,在 1024 像素宽度的高清图像上,最小仅需要 2.1GMAdds 的计算量,开启了在主流移动端处理器上做高清视频级应用的可能性。

基于 DFANet 技术的实时人像虚化
方法
实时语义分割技术 DFANet 是如何实现的呢?可以说是两个优点的整合:1)通过深度多层聚合(Deep Feature Aggregation)结构充分利用网络的高层特征信息,2)通过 DFA轻量级特征聚合结构让轻量级编码器大受裨益。
高层特征的充分利用
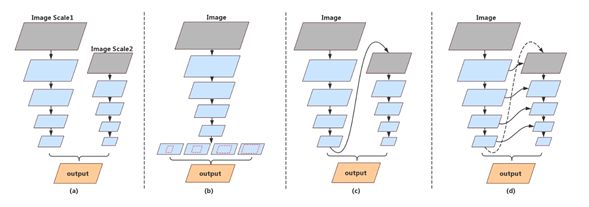
图 1:主流分割网络结构对比
神经网络的卷积操作在各个层级抽取出大量特征,充分用好这些来之不易的特征向量是设计轻量级神经网格的圭臬,而不同的部位之间特征共享是一个重要的手段。DFANet 对主流分割网络做出了这样一个观察:网络中往往存在不同输入分辨率的进行特征提取的并行的“塔”(如图 1(a)所示);而这些“塔”之间可以共享特征。
DFANet 的核心结构是如图 1(d)所示的深度多层聚合,其特点是每一个层提取的特征会复用于下一级“塔”,同时,前一级“塔”的输出特征在上采样之后送到后一级“塔”。之前的分割网络结构要么塔之间没有连接,从而在这里失去了重用特征的机会;要么干脆没有多个塔,导致解码器承受过多压力。而把一级的输出送回下一级的设计使得每一级都能站在上一级结果的肩膀上,从而加速了网络的训练。
综合以上优势,DFANet 的特征提取方式可在小计算量的前提下最充分地促进不同层次特征之间的交互与聚合,从而提升准确率。
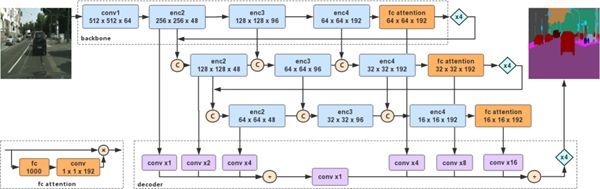
图 2:深度多层聚合网络示意图
图 2 以 1024x1024 的输入分辨率为例展示了 DFANet 的全部结构,它由最多三级特征提取塔所构成。各个层级的特征最后汇总到一个解码器(decoder)输出逐像素的结果。实际使用时可按需求定制输入分辨率与塔的级数,从而灵活调节计算量与效果。
聚合让轻量级编码器受益
为了适应实时的要求,网络结构中的编码器(encoder)使用了一个修改后的 Xception 结构。


通常,使用 Xception 等“轻量级”编码器会导致精度极大下降(如上表所示,把 ResNet-50 换成 Xception 最多可以导致 9% 的 mIou 下降)。缓解该问题有个方法,即通过增加多层次特征聚合来减轻编码器容量减小所带来的冲击。不过,一般的特征聚合方法,如ASPP,会显著增加运算量。上表中所举的例子,ASPP 模块甚至能占到 70%~80% 左右的总运算量。这在实时应用中无疑成为了最大的瓶颈。
而在 DFANet 中,聚合不再是运算量的“无底洞”。如表中数字所示,DFANet 的轻量级聚合结构在不显著增加运算的前提下,可以达到类似 ASPP 等的聚合效果。例如在同样 1.6GMAdds 的对比中,使用了 DFA 结构后,可以把原来 Xception 结构的性能从 59.2%提升到 71.9%,远远超出 ASPP 之后的效果,且计算量更小。这充分说明了 DFA 结构是一个能力出色的轻量级特征聚合结构。
DFA 结构与轻量级编码器相辅相成,共同实现了算法总运算量的降低。可以说,轻量级的聚合结构是通向实时计算的关键组件。
实验
7 倍轻量依然准确
为公平验证 DFANet 的效果,旷视研究院在学术界最常用的分割测试集 Cityscapes 上做了测试。这个数据集是各种最新分割算法的集大成者,尤其是实时分割结果;在其中,输入图片被要求分割为道路、车辆等不同区域,而预测区域与实际区域之间的“平均相交比例”(mIou)被作为评测不同算法的指标。

图3:DFANet 与其他方法性能对比
由上图可知,相比于先前的 BiSeNet 和 ICNet 等,在相近精度的条件下 DFANet 可以极大地减少运算量。而和 ENet 等小计算量方法相比,DFANet 的精度有巨大提升。
具体而言,在使用边长 1024 的高清测试集上,DFANet可以只使用 3.4GMAdds 的运算量在 Cityscapes testset上达到 71.3% 的 mIou 水平。与它运算量接近的 ENet 只有 57% 的 mIou,而当 mIou 类似时,例如 BiSeNet,之前方法的运算达到 10GMAdds 以上,无法完全满足终端设备实时计算的要求。
可以说,在计算量受限的前提下,DFANet 是第一个能在高分辨率图片上达到准确度媲美主流“大模型”的轻量化网络。
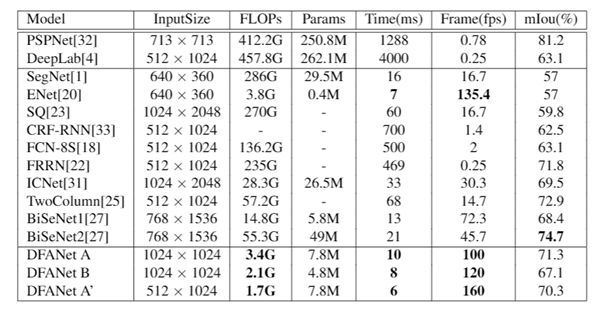
表 5:分割测试集Cityscapes testset上的速度分析
对于图像结果的主观评估也验证了 DFANet 结构的有效性。如下图所示,随着特征提取塔数的加多,分割结果中错误的细节越来越少,直到逼近真实答案。这说明随着越来越多的特征被聚合,原来“看不明白”的地方可以被更正确的理解与预测。
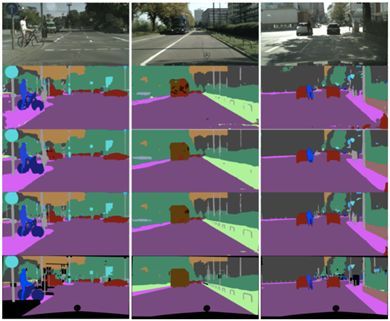
图 4:DFANet 在 Cityscapes 验证集上的结果
结论
AI落地之路行之不易,除了完备的训练系统与工程化之外,更需要在算法理论上进行突破创新。对于无数需要智能化进行赋能的终端设备,以 DFANet 为代表的新一代模型算法将找到广阔的应用,旷视正以非凡科技,朝着驱动百亿智能设备的愿景大步前进。
参考文献
1. H. Zhao, X. Qi, X. Shen, J. Shi, andJ. Jia. Icnet for real-time semantic segmentation on high-resolution images. ArXiv preprint arXiv:1704.08545, 2017.
2. H. Zhao, J. Shi, X. Qi, X. Wang, andJ. Jia. Pyramid scene parsing network. In IEEE Conf. on Computer Vision andPattern Recognition (CVPR), pages 2881–2890, 2017.
3. L.-C. Chen, Y. Zhu, G. Papandreou, F.Schroff, and H. Adam. Encoder-decoder with atrous separable convolution forsemantic image segmentation. arXiv preprint arXiv:1802.02611, 2018.
4. H. Li, P. Xiong, J. An, and L. Wang.Pyramid attention network for semantic segmentation. arXiv preprintarXiv:1805.10180, 2018.
5. C. Yu, J. Wang, C. Peng, C. Gao, G.Yu, and N. Sang. Bisenet: Bilateral segmentation network for real-time semanticsegmentation. arXiv preprint arXiv:1808.00897, 2018.
6. F. Chollet. Xception: Deep learningwith depthwise separable convolutions. arXiv preprint, pages 1610–02357, 2017.
7. A. Paszke, A. Chaurasia, S. Kim, andE. Culurciello. Enet: A deep neural network architecture for real-time semanticsegmentation. arXiv preprint arXiv:1606.02147, 2016.
往期解读
1. CVPR 2019 | 旷视研究院提出GIF2Video:首个深度学习 GIF 质量提升方法
2. CVPR 2019 | 旷视研究院Oral论文提出GeoNet:基于测地距离的点云分析深度网络
3. CVPR 2019 | 旷视研究院提出Meta-SR:单一模型实现超分辨率任意缩放因子
传送门 1
欢迎各位同学关注旷视研究院 AI 影像(LLCV)组(及其知乎专栏“旷视AI摄影”:https://zhuanlan.zhihu.com/r-llcv),简历可投递给 LLCV 组负责人范浩强([email protected])。
传送门 2
欢迎大家关注如下 旷视研究院 官方微信号????
