Hands Deep in Deep Learning for Hand Pose Estimation
摘要:
我们介绍和评估了卷积神经网络的几种架构,以预测给定深度图的手的3D关节位置。我们首先表明,可以很容易地引入3D姿势的先验,并显着提高预测的准确性和可靠性。我们还展示了如何有效地使用上下文来处理手指之间的歧义。这两个贡献使我们能够明显优于几个具有挑战性的基准状态,包括准确度和计算时间。代码可以在https://github.com/moberweger/deep-prior/找到
1. Introduction
准确的手势估计是许多人机交互或增强现实任务的重要要求,并且在计算机视觉研究界引起了很多关注[10,11,14,15,17,22,23,29]。即使使用3D传感器构造 - 光线透射传感器,它仍然具有挑战性,同时具有很大的自由度,并且在图像中表现出自相似性和自遮挡性。
鉴于目前计算机视觉的趋势,应用深度学习[18]来解决这一任务是很自然的,并且具有标准体系结构的卷积神经网络(CNN)在应用于此问题时表现非常好,如一个简单的实验所示。然而,网络的布局对输出的准确性有很大的影响[4,21],在本文中,我们的目标是确定最适合这个问题的架构。更具体地说,我们的贡献是双重的:
(1)我们展示了我们可以学习手势的先前模型并将其无缝地集成到网络中以提高预测姿势的准确性。 这导致网络具有不寻常的“瓶颈”,即具有比最后一层更少的神经元的层。
(2)像以前的工作[21,27]一样,我们使用一个改进阶段来独立地改进每个关节的位置估计。 由于这是一个回归问题,因此在此阶段应谨慎使用空间池和子采样。 为了解决这个问题,我们使用以关节的初始估计为中心的多个输入区域,对于较小的输入区域具有非常小的池化区域,对于较大的输入区域具有较大的池化区域。 较小的区域提供准确性,较大的区域提供上下文信息。
我们表明,我们的原始贡献使我们在准确性和计算时间方面在几个具有挑战性的基准[22,26]上显着优于最先进的技术。 我们的方法在单个GPU上运行速度超过5000 fps,在CPU上运行速度超过500 fps,比现有技术速度快一个数量级。 在本文的其余部分,我们首先简要回顾第2节中的相关工作。我们在第3节中介绍了我们的贡献,并在第4节中对它们进行了评估。
2. Related Work
手姿势估计是计算机视觉中的一个老问题,早期参考了九十年代,但它目前非常活跃,可能是因为深度传感器的出现。 [6]中给出了对早期工作的一个很好的概述。 在这里,我们将仅讨论最近的工作,这可以分为两种主要方法。
第一种方法基于生成的,基于模型的跟踪方法。 [15,17]使用3D手模型和粒子群优化来处理要估计的大量参数。 [14]也考虑了3D模型的动力学模拟。 一些作品依赖于综合跟踪方法:[5]考虑着色和纹理,[1]突出点和[29]深度图像。 所有这些工作都需要仔细初始化以保证收敛,因此依赖于基于最后帧的姿势或单独的初始化方法的跟踪 - 例如,[17]需要指尖是可见的。 这种基于跟踪的方法难以处理两帧之间的剧烈变化,这是常见的,因为手往往快速移动。
第二种方法是辨别性的,旨在直接从RGB或RGB-D图像预测关节的位置。 例如,[11]和[13]依靠多层随机森林进行预测。 前者使用不变的深度特征,后者使用手工配置空间中的聚类和像素方式标记。 然而,两者都没有预测实际的目的,而是基于字典来分类。 受人类姿势估计工作的启发[20],[10]使用随机森林对深度图像进行逐像素分类,然后使用局部模式发现算法来估计2D关节位置。 然而,这种方法不能直接推断隐藏关节的位置,隐藏关节的位置对于手而言比人体更频繁。
[23]提出了一个半监督的回归森林,它首先分类手部视点,然后是各个关节,以最终预测3D关节位置。 然而,它依赖于昂贵的像素分类,并且由于视点量化而需要庞大的训练数据库。 同一作者在[22]中提出了一个回归森林,使用手的分层模型直接回归关节的三维位置。 但是,它们的分层方法会累积错误,导致手指提示出现更大的错误。
最近,[26]使用CNN进行特征提取,并为关节位置生成小的“热图”,他们使用逆向运动来推断手部姿势。 然而,他们的方法仅预测关节的2D位置,并使用第三坐标的深度图,这对于隐藏关节是有问题的。 此外,精度限于热图分辨率,并且创建热图在计算上是昂贵的,因为必须在每个像素位置处评估CNN。
手姿势估计问题当然与人体姿势估计问题密切相关。 为了解决这个问题,[20]提出了每像素语义分割和回归森林,以从单个深度图像估计3D人体姿势。 [9]最近表明,通过组合的身体部位标记和用于3D关节定位的迭代结构化输出回归,可以仅从RGB图像做同样的事情。 [27]最近提出了一系列CNN,以直接预测迭代地重新定义RGB图像中的2D关节位置。 此外,[25]使用CNN进行部件检测和简单的空间模型,然而,这对于姿势空间的高度变化无效。
在我们的工作中,我们以CNN的成功为基础,并将它们用于展示其性能。 我们观察到,网络的结构非常重要。 因此,我们提出并研究不同的体系结构,以找到最适合手姿势估计问题的体系结构。 我们提出了一种运行良好的网络结构,在两个难以分析的数据集上优于基线。
3. Hand Pose Estimation with Deep Learning
在本节中,我们将展示我们对手部姿势估计问题的原始贡献。 我们首先简要介绍了这个问题和一个简单的2D手检测器,我们用它来获得手的粗略边界框作为基于CNN的姿势预测器的输入。
然后我们描述了我们的一般方法,它包括两个阶段。 对于第一阶段,我们考虑不同的架构,同时预测所有关节的位置。 可选地,该阶段可以预测较低维空间中的姿势,这将在下面描述。 最后,我们详细介绍了第二阶段,它独立于第一阶段的预测来确定关节的位置。
在本节中,我们将展示我们对手部姿势估计问题的原始贡献。 我们首先简要介绍了这个问题和一个简单的2D手检测器,我们用它来获得手的粗略边界框作为基于CNN的姿势预测器的输入。
然后我们描述了我们的一般方法,它包括两个阶段。 对于第一阶段,我们考虑不同的架构,同时预测所有关节的位置。 可选地,该阶段可以预测较低维空间中的姿势,这将在下面描述。 最后,我们详细介绍了第二阶段,它独立于第一阶段的预测来确定关节的位置。
3.1 Problem Formulation
我们想要从单个深度图像估计J 3D手关节位置J = {ji} J i = 1 withji =(xi,yi,zi)。 我们假设可以获得用3D关节位置标记的训练深度图像集。 为了简化回归任务,我们首先使用类似于[22]的简单方法估计包含手的粗糙3D边界框,假设手是最接近相机的对象:我们从深度图中提取固定大小的立方体 以该物体的质心为中心,并将其调整为128×128的深度值补片,其标准化为[-1,1]。 深度不可用的点 - 例如结构光传感器可能发生 - 或者比立方体的背面更深,被指定深度为1.这种归一化对于CNN是重要的,对手部距离摄像机的不同距离而不发生改变。
3.2 Network Structures for Predicting the Joints' 3D Locations
我们首先考虑了两种标准的CNN架构。 第一个如图1a所示,是一个简单的浅网络,由一个卷积层,一个最大池层和一个完全连接的隐藏层组成。 我们考虑的第二种架构如图1b所示,是一个更深层但仍然是通用的网络[12,27],其中有三个卷积层,后面是最大池层和两个完全连接的隐藏层。 所有层都使用修正线性单元[12]激活功能。
此外,我们评估了多尺度方法,例如[7,19,25]。 这种方法的动机是使用多个尺度可能有助于捕获上下文信息。 它使用几个缩小版本的输入图像输入到网络,如图1c所示。 我们的结果将表明,毫不奇怪,多尺度方法比深层架构表现更好,深层架构比浅层架构表现更好。 但是,我们在接下来的两节中描述的贡献会带来显着的改善。
3.3 Enforcing a Prior on the 3D Pose
到目前为止,我们只考虑直接预测关节的3D位置。 然而,考虑到手的物理约束,不同的3D关节位置之间存在很强的相关性,之前的工作[28]已经表明低维嵌入足以参数化手的3D姿势。 因此,我们可以在较低维空间中预测姿势的参数,而不是直接预测3D关节位置。 由于这强制了手姿势的约束,可以预期它会提高预测的可靠性,这将通过我们的实验得到证实。
如图1d所示,我们通过引入“瓶颈”来实现网络结构之前的姿势。这个瓶颈是一个神经元比完整姿势表示所需的神经元少的层,即<<3·J。它迫使网络学习训练数据的低维表示,其实现手的物理约束。与[28]类似,我们依赖于线性嵌入。嵌入由瓶颈层强制执行,并且从嵌入到姿势空间的构造被集成为添加在瓶颈层顶部的单独隐藏层。设置重建层的权重以计算到3·J维关节空间的反投影。因此,生成的网络直接计算完整的姿势。我们使用来自手势数据的主成分分析的主要成分初始化构造权重,然后使用反向传播训练整个网络。使用这种方法,我们训练上一节中描述的网络。
对于42维姿势向量,嵌入可以小到8维,以完全表示我们在实验中显示的3D姿势
3.4 Refining the Joint Location Estimates
以前的架构同时提供了对所有关联的位置的估计。 如[21,27]所述,这些估计可以独立地重新定义。 空间背景对于这个改进步骤很重要,以避免不同手指之间的混淆。 我们试验过的最佳性能架构如图2a所示。 我们将这个架构称为ORRef,用于重构区域的细化。 它使用不同大小的几个补丁作为输入,但都以第一阶段预测的关节位置为中心。 没有池应用于最小的补丁,并且池区域的大小随着补丁的大小而增加。 较大的补丁提供了更多的空间背景,而小补丁上没有池化可以提高准确性。
我们还将标准CNN架构视为基线,如图1b所示,它依赖于单个输入补丁。 我们将此基线称为StdRef,用于标准体系结构的改进。
为了进一步提高位置估计的准确性,我们通过将网络集中在前一次迭代预测的位置上,对该改进步骤进行多次迭代。
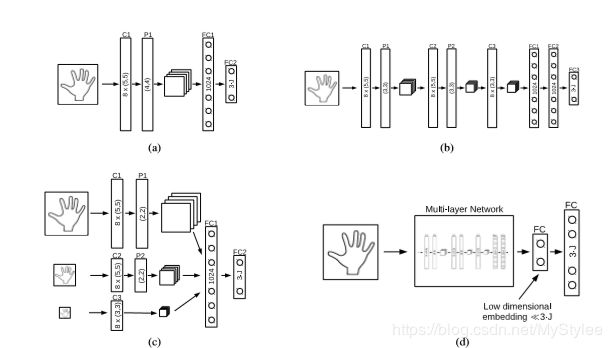
图1:第一阶段的不同网络架构。 C表示卷积层,其具有过滤器的数量和内接过滤器的大小,FC是具有神经元数量的完全连接的层,并且P是具有合并大小的最大池化层。 我们评估了浅层网络(a)和更深层网络(b)的性能,以及[7,19]中使用的多尺度架构(c)。 该结构在通过若干因素缩减输入深度图之后提取特征。 (d)所有这些网络都可以扩展到包含先前的约束姿势。 这导致了一个不寻常的瓶颈,神经元比输出层少。
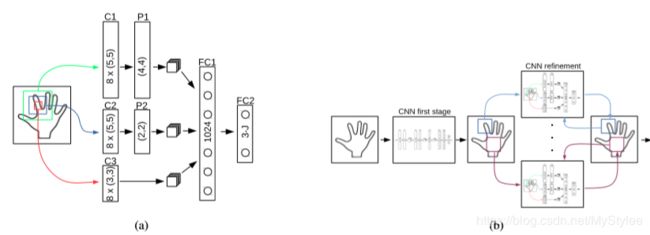
图2:我们在第二阶段重新确定关节位置的架构。 我们为每个关节使用不同的网络,以便在第一阶段提供其位置估计。 (a)我们提出的架构使用以关节为中心的重叠输入。 小区域的汇集适用于较小的输入,而较大的输入汇集较大的区域。 较小的输入允许更高的准确性,较大的输入提供上下文信息。 我们通过实验证明,这种架构比更标准的网络架构更准确。 (b)显示了迭代改进的通用体系结构,其中前一次迭代的输出用作下一次迭代的输入。 对于图1,C表示卷积层,FC表示完全连接层,P表示最大化层。 (最好看的颜色)
4. Evaluation
在本节中,我们将评估上一节中介绍的几个具有挑战性的基准测试的不同架构。 我们首先介绍这些基准和我们方法的参数。 然后我们描述评估指标,最后我们定量地和定性地呈现结果。 我们的研究结果表明,我们的不同贡献显着优于现有技术。