CVPR2019 (一)
1. Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
paper
code
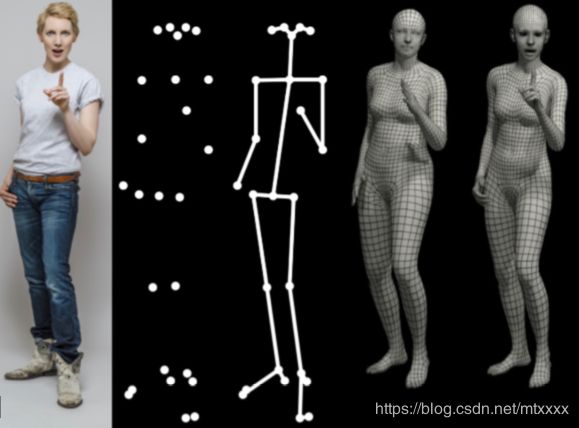
Abstract:To facilitate the analysis of human actions, interactions and emotions, we compute a 3D model of human body pose, hand pose, and facial expression from a single monocular image. To achieve this, we use thousands of 3D scans to train a new, unified, 3D model of the human body, SMPL-X, that extends SMPL with fully articulated hands and an expressive face. Learning to regress the parameters of SMPL-X directly from images is challenging without paired images and 3D ground truth. Consequently, we follow the approach of SMPLify, which estimates 2D features and then optimizes model parameters to fit the features. We improve on SMPLify in several significant ways: (1) we detect 2D features corresponding to the face, hands, and feet and fit the full SMPL-X model to these; (2) we train a new neural network pose prior using a large MoCap dataset; (3) we define a new interpenetration penalty that is both fast and accurate; (4) we automatically detect gender and the appropriate body models (male, female, or neutral); (5) our PyTorch implementation achieves a speedup of more than 8×over Chumpy. We use the new method, SMPLify-X, to fit SMPL-X to both controlled images and images in the wild. We evaluate 3D accuracy on a new curated dataset comprising 100 images with pseudo ground-truth. This is a step towards automatic expressive human capture from monocular RGB data. The models, code, and data are available for research purposes at https://smpl-x.is.tue.mpg.de.
为了便于分析人的行为、互动和情绪,我们从单张图像中计算出人体姿势、手姿势和面部表情的三维模型。为了实现这一点,我们使用了数千次3D扫描来训练一个新的、统一的人体3D模型SMPL-X,它用完全关节化的手和表情丰富的脸来扩展SMPL。在没有配对图像和三维ground truth 的条件下学习直接从图像中回归SMPL-X的参数是一个挑战。因此,我们采用SMPLify方法,对二维特征进行估计,然后优化模型参数以确定特征。我们在SMPLify上有几个显著的改进:(1)我们检测与脸、手和脚相对应的二维特征,并确定这些特征的完整smpl-x模型;(2)我们使用大型mocap数据集训练一个新的神经网络姿势先验;(3)我们定义了一个新的快速且准确的穿透惩罚;(4)我们自动检测性别和适当的身体模型(男性、女性或中性);(5)我们的PyTorch实现了Chumpy方法8倍的速度。我们使用新的方法smplify-x,使smpl-x适用于为受控图像和自然环境中的图像(in the wild)。我们评估了一个新的整理过后包括100张具有伪ground-truth的图像数据集的三维精度。这是实现从单目RGB数据自动表达人物造型捕获的一个进步。这些模型、代码和数据可在https://smpl-x.is.tue.mpg.de上获得,以供研究之用。
2. Combining 3D Morphable Models: A Large scale Face-and-Head Model
paper
lsfm-code
Abstract:Three-dimensional Morphable Models (3DMMs) are powerful statistical tools for representing the 3D surfaces of an object class. In this context, we identify an interesting question that has previously not received research attention: is it possible to combine two or more 3DMMs that (a) are built using different templates that perhaps only partly overlap, (b) have different representation capabilities and (c) are built from different datasets that may not be publiclyavailable? In answering this question, we make two contributions. First, we propose two methods for solving this problem: i. use a regressor to complete missing parts of one model using the other, ii. use the Gaussian Process framework to blend covariance matrices from multiple models. Second, as an example application of our approach, we build a new face-and-head shape model that combines the variability and facial detail of the LSFM with the full head modelling of the LYHM. The resulting combined shape model achieves state-of-the-art performance and outperforms existing head models by a large margin. Finally, as an application experiment, we reconstruct full head representations from single, unconstrained images by utilizing our proposed large-scale model in conjunction with the FaceWarehouse blendshapes for handling expressions.
三维变形模型(3DMMs)是表示对象类的三维曲面的强大统计工具。在此背景下,我们发现了一个以前未受到研究关注的有趣问题:是否可以将两个或多个3DMM组合起来:(a)使用可能只是部分重叠的不同模板构建;(b)具有不同的表示能力;(c)基于可能无法公开的不同数据集?在回答这个问题时,我们做出了两项贡献。首先,我们提出了两种方法来解决这个问题:一,使用回归器和另一个模型来完成一个模型的缺失部分;二,使用高斯过程框架混合来自多个模型的协方差矩阵。其次,作为我们方法的一个应用实例,我们构建了一个新的面部和头部形状模型,将LSFM的可变性和面部细节与Lyhm的全头部模型相结合。由此产生的组合形状模型达到了最先进的性能,并大大优于现有的头部模型。最后,作为一个应用实验,我们利用我们提出的大规模模型,结合FaceWarehouse的混合变形来处理表达式,从单一的、不受约束的图像重建完整的头部表示。
主要贡献:1)一种方法,旨在融合基于形状的3DMMs,以人脸和头部为例。特别地,我们提出了一种基于潜在形状参数的回归方法,以及一种在高斯过程框架中使用的协方差组合方法。2)一种大规模人类头部组合比例统计模型,(人类头部包含了种族、年龄和性别方面)。该模型比任何其他现有的头部变形模型都要精确得多——我们将此模型公之于众,以造福研究界,包括有眼和无牙的版本。3)一个应用实验,我们利用组合3dmm从无约束的单个图像进行全头部重建,同时利用FaceWarehouse混合变形处理面部表情。
整合现有的3DMM来增强自己的表达能力。
3. Self-supervised 3D hand pose estimation through training by fitting

paper
code
Abstract:We present a self-supervision method for 3D hand pose estimation from depth maps. We begin with a neural network initialized with synthesized data and fine-tune it on real but unlabelled depth maps by minimizing a set of datafitting terms. By approximating the hand surface with a set ofspheres,we design a differentiable hand renderer to align estimates by comparing the rendered and input depth maps. In addition,we place a set of priors including a data-driven term to further regulate the estimate’s kinematic feasibility. Our method makes highly accurate estimates comparable to current supervised methods which require large amounts of labelled training samples, thereby advancing state-of-theart in unsupervised learning for hand pose estimation.
提出了一种基于深度图的三维手部姿态估计的自监督方法。我们从一个用合成数据初始化的神经网络开始,通过最小化一组数据定义项,在真实但未标记的深度图上对其进行微调。通过将手部表面近似为一组球体,我们设计了一个可区分的手部渲染器,通过比较渲染和输入深度映射来对齐估计值。此外,我们还放置了一组先验项,包括数据驱动项,以进一步调节估计的运动可行性。我们的方法使高精度的估计可与当前的监督方法相比,后者需要大量的标记训练样本,从而提高了无监督学习中的手位估计状态。
4. Monocular Total Capture:Posing Face, Body and Hands in the Wild
paper
code
Abstract:We present the first method to capture the 3D total motion of a target person from a monocular view input. Given an image or a monocular video, our method reconstructs the motion from body, face, and fingers represented by a 3D deformable mesh model. We use an efficient representation called 3D Part Orientation Fields (POFs), to encode the 3D orientations of all body parts in the common 2D image space. POFs are predicted by a Fully Convolutional Network, along with the joint confidence maps. To train our network, we collect a new 3D human motion dataset capturing diverse total body motion of 40 subjects in a multiview system. We leverage a 3D deformable human model to reconstruct total body pose from the CNN outputs with the aid of the pose and shape prior in the model. We also present a texture-based tracking method to obtain temporally coherent motion capture output. We perform thorough quantitative evaluations including comparison with the existing body-specific and hand-specific methods, and performance analysis on camera viewpoint and human pose changes. Finally, we demonstrate the results of our total body motion capture on various challenging in-the-wild videos.
我们提出了第一种方法,从单眼视图输入中捕捉目标人物的三维总运动。对于一个图像或单目视频,我们的方法从三维可变形网格模型表示的身体、面部和手指重建运动。我们使用一种称为3D零件方向场(POF)的有效表示,来编码公共二维图像空间中所有身体零件的3D方向。POF是通过一个完全卷积的网络以及联合信心图来预测的。为了训练我们的网络,我们收集了一个新的三维人体运动数据集,在多视图系统中捕获了40个受试者的不同的全身运动。我们利用一个三维可变形人体模型,借助于模型中的姿势和形状,从CNN输出中重建整个身体姿势。我们还提出了一种基于纹理的跟踪方法来获得时间相干运动捕获输出。我们进行了全面的定量评估,包括与现有的身体和手部特定方法的比较,以及对摄像机视角和人体姿势变化的性能分析。最后,我们展示了我们在野外视频中对各种挑战的全身运动捕捉的结果。
5. FML:Face Model Learning from Videos
paper

Abstract:Monocular image-based 3D reconstruction of faces is a long-standing problem in computer vision. Since image data is a 2D projection of a 3D face, the resulting depth ambiguity makes the problem ill-posed. Most existing methods rely on data-driven priors that are built from limited 3D face scans. In contrast, we propose multi-frame video-based self-supervised training of a deep network that (i) learns a face identity model both in shape and appearance while (ii)jointly learning to reconstruct 3Dfaces. Our face model is learned using only corpora of in-the-wild video clips collected from the Internet. This virtually endless source of training data enables learning of a highly general 3D face model. In order to achieve this, we propose a novel multiframe consistency loss that ensures consistent shape and appearance across multiple frames of a subject’s face, thus minimizing depth ambiguity. At test time we can use an arbitrary number of frames, so that we can perform both monocular as well as multi-frame reconstruction.
基于单目图像的人脸三维重建是计算机视觉中一个长期存在的问题。由于图像数据是三维人脸的二维投影,由此产生的深度模糊性使问题不适定。大多数现有的方法都依赖于数据驱动,而不是有限的3面扫描。相比之下,我们提出了一种基于多帧视频的深层网络自监督训练:(i)在形状和外观上学习人脸识别模型;(ii)共同学习重建三维人脸。我们的面部模型是使用从互联网上收集的野生视频片段的语料库学习的。这种几乎无穷无尽的训练数据源使得学习一个高度通用的三维人脸模型成为可能。为了实现这一点,我们提出了一种新的多帧一致性损失,确保在一个主题的脸的多帧一致的形状和外观,从而最小化深度模糊。在测试时,我们可以使用任意数量的帧,这样我们既可以执行单目重建,也可以执行多帧重建。
6. Self Supervised Learning of 3D Human Pose using Multi-view Geometry
paper
code
Abstract:Training accurate 3D human pose estimators requires large amount of 3D ground-truth data which is costly to collect. Various weakly or self supervised pose estimation methods have been proposed due to lack of 3D data. Nevertheless, these methods, in addition to 2D groundtruth poses, require either additional supervision in various forms (e.g. unpaired 3D ground truth data, a small subset of labels) or the camera parameters in multiview settings. To address these problems, we present EpipolarPose, a self-supervised learning method for 3D human pose estimation, which does not need any 3D ground-truth data or camera extrinsics. During training, EpipolarPose estimates 2D poses from multi-view images, and then, utilizes epipolar geometry to obtain a 3D pose and camera geometry which are subsequently used to train a 3D pose estimator. We demonstrate the effectiveness of our approach on standard benchmark datasets (i.e. Human3.6M and MPI-INF-3DHP) where we set the new state-of-the-art among weakly/self-supervised methods. Furthermore, we propose a new performance measure Pose Structure Score (PSS) which is a scale invariant, structure aware measure to evaluate the structural plausibility of a pose with respect to its ground truth. Code and pretrained models are available at https://github.com/mkocabas/ EpipolarPose
训练精确的三维人体姿态估计器需要大量的三维地面真实数据,采集成本很高。由于缺乏三维数据,提出了各种弱监督或自监督的姿态估计方法。然而,这些方法,除了二维地面真值姿态外,还需要以各种形式(例如,未配对的三维地面真值数据、标签的一小部分)进行额外的监控,或者多视图设置中的相机参数。为了解决这些问题,我们提出了一种三维人体姿态估计的自监督学习方法,它不需要任何三维ground-truth数据或相机外部信息。在训练过程中,epiparpose从多视图图像中估计二维姿态,然后利用epiparpose几何来获得三维姿态和相机几何,随后用于训练三维姿态估计器。我们证明了我们的方法在标准基准数据集(即human360万和mpi-inf-3dhp)上的有效性,在这些数据集中,我们在弱/自监督方法之间设置了最新的技术水平。此外,我们还提出了一种新的性能度量-姿势结构评分(PSS),它是一种尺度不变的、结构感知的度量,用于评估姿势相对于其基本真实性的结构合理性。可在https://github.com/mkocabas/epiparpose上获取代码和预培训模型。
7. Learning to Reconstruct People in Clothing from a Single RGB Camera
paper
code
Abstract:We present Octopus, a learning-based model to infer the personalized 3D shape of people from a few frames (1-8) of a monocular video in which the person is moving with a reconstruction accuracy of 4 to 5mm, while being orders of magnitude faster than previous methods. From semantic segmentation images, our Octopus model reconstructs a 3D shape, including the parameters of SMPL plus clothing and hair in 10 seconds or less. The model achieves fast and accurate predictions based on two key design choices. First, by predicting shape in a canonical T-pose space, the network learns to encode the images of the person into pose in variant latent codes, where the information is fused. Second,based on the observation that feed-forward predictions are fast but do not always align with the input images, we predict using both, bottom-up and top-down streams (one per view) allowing information to flow in both directions. Learning relies only on synthetic 3D data. Once learned, Octopus can take a variable number of frames as input, and is able to reconstruct shapes even from a single image with an accuracy of 5mm. Results on 3 different datasets demonstrate the efficacy and accuracy of our approach. Code is available at [2].
我们提出了一种基于学习的章鱼模型,从一个单眼视频的几个帧(1-8)中推断出人的个性化三维形状,其中人以4到5毫米的重建精度移动,同时比以前的方法快几个数量级。从语义分割图像,我们的章鱼模型重建一个三维形状,包括参数的SMPL加上服装和头发在10秒或更少。该模型基于两个关键设计选择,实现了快速、准确的预测。首先,通过预测典型T姿势空间中的形状,网络学习将人的图像编码成不同的潜在代码中的姿势,在那里信息被融合。其次,根据前馈预测速度快但并不总是与输入图像一致的观察结果,我们预测使用自下而上和自上而下的流(每个视图一个),允许信息向两个方向流动。学习只依赖于合成的3D数据。一旦学会,章鱼可以接受一个可变的帧数作为输入,并能够重建形状,即使从一个单一的图像精度为5毫米。3个不同数据集的结果证明了我们方法的有效性和准确性。代码可在[2]上找到。
8. Unsupervised 3D Pose Estimation with Geometric Self-Supervision
paper
Abstract:We present an unsupervised learning approach to recover 3D human pose from 2D skeletal joints extracted from a single image. Our method does not require any multiview image data, 3D skeletons, correspondences between 2D-3D points, or use previously learned 3D priors during training. A lifting network accepts 2D landmarks as inputs and generates a corresponding 3D skeleton estimate. During training, the recovered 3D skeleton is reprojected on random camera viewpoints to generate new ‘synthetic’ 2D poses. By lifting the synthetic 2D poses back to 3D and re-projecting them in the original camera view, we can define self-consistency loss both in 3D and in 2D. The training can thus be self supervised by exploiting the geometric selfconsistency of the lift-reproject-lift process. We show that self-consistency alone is not sufficient to generate realistic skeletons, however adding a 2D pose discriminator enables the lifter to output valid 3D poses. Additionally, to learn from 2D poses ‘in the wild’, we train an unsupervised 2D domain adapter network to allow for an expansion of 2D data. This improves results and demonstrates the usefulness of 2D pose data for unsupervised 3D lifting. Results on Human3.6M dataset for 3D human pose estimation demonstrate that our approach improves upon the previous unsupervised methods by 30% and outperforms many weakly supervised approaches that explicitly use 3D data.
我们提出了一种无监督学习方法来恢复三维人体姿势从二维骨骼关节提取的单一图像。我们的方法不需要任何多视图图像数据、三维骨骼、二维到三维点之间的对应关系,或者在培训期间使用以前学习过的三维优先级。提升网络接受二维地标作为输入,并生成相应的三维骨架估计。在训练过程中,恢复的三维骨架被重新投射到随机的相机视点上,以生成新的“合成”二维姿态。通过将合成的二维姿势提升回三维并在原始相机视图中重新投影,我们可以在三维和二维中消除自一致性损失。因此,通过利用提升重投影提升过程的几何自一致性,可以自我监督训练。我们表明,仅仅自我一致性并不足以生成真实的骨骼,但是添加一个二维姿势鉴别器可以使升降机输出有效的三维姿势。此外,为了从“野外”的二维姿势中学习,我们训练了一个无监督的二维域适配器网络,以允许二维数据的扩展。这提高了结果,并证明了二维姿态数据在无监督三维提升中的实用性。三维人体姿态估计的人类360万数据集的结果表明,我们的方法比以前的无监督方法提高了30%,优于许多明确使用三维数据的弱监督方法。
9. Fast and Robust Multi-Person 3D Pose Estimation from Multiple Views
paper
code
This paper addresses the problem of 3D pose estimation for multiple people in a few calibrated camera views. The main challenge of this problem is to find the cross-view correspondences among noisy and incomplete 2D pose predictions. Most previous methods address this challenge by directly reasoning in 3D using a pictorial structure model, which is inefficient due to the huge state space. We propose a fast and robust approach to solve this problem. Our key idea is to use a multi-way matching algorithm to cluster the detected 2D poses in all views. Each resulting cluster encodes 2D poses of the same person across different views and consistent correspondences across the keypoints, from which the 3D pose of each person can be effectively inferred. The proposed convex optimization based multi-way matching algorithm is efficient and robust against missing and false detections, without knowing the number of people in the scene. Moreover, we propose to combine geometric and appearance cues for cross-view matching. The proposed approach achieves significant performance gains from the state-of-the-art (96.3% vs. 90.6% and 96.9% vs. 88% on the Campus and Shelf datasets,respectively),while being efficient for real-time applications.
本文讨论了在几个已校准的摄像机视图中多人三维姿态估计的问题。这一问题的主要挑战是确定噪声和不完全二维姿态预测之间的交叉视图对应关系。大多数以前的方法都是通过使用图像结构模型直接在3D中进行推理来解决这一挑战,这种模型由于状态空间巨大而不适用。我们提出了一种快速而有力的方法来解决这个问题。我们的核心思想是使用多路径匹配算法对所有视图中检测到的二维姿态进行聚类。每个生成的集群对同一个人在不同视图中的二维姿势和关键点之间的一致对应进行编码,从中可以有效地推断出每个人的三维姿势。提出的基于凸优化的多路径匹配算法,在不知道现场人数的情况下,对漏检和误检具有良好的鲁棒性。此外,我们还建议结合几何和外观线索进行交叉视图匹配。该方法通过最先进的技术(分别为96.3%和90.6%以及96.9%和88%的校园和货架数据集)获得了显著的性能提升,同时对实时应用非常有效。
10. Pushing the Envelope for RGB-based Dense 3D Hand Pose Estimation via Neural Rendering
paper
Estimating 3D hand meshes from single RGB images is challenging, due to intrinsic 2D-3D mapping ambiguities and limited training data. We adopt a compact parametric 3D hand model that represents deformable and articulated hand meshes. To achieve the model fitting to RGB images, we investigate and contribute in three ways: 1) Neural rendering: inspired by recent work on human body, our hand mesh estimator (HME) is implemented by a neural network and a differentiable renderer, supervised by 2D segmentation masks and 3D skeletons. HME demonstrates good performance for estimating diverse hand shapes and improves pose estimation accuracies. 2) Iterative testing refinement: Our fitting function is differentiable. We iteratively refine the initial estimate using the gradients, in the spirit of iterative model fitting methods like ICP. The idea is supported by the latest research on human body. 3) Self-data augmentation: collecting sized RGB-mesh (or segmentation mask)-skeleton triplets for training is a big hurdle. Once the model is successfully fitted to input RGB images, its meshes i.e. shapes and articulations, are realistic, and we augment view-points on top of estimated dense hand poses. Experiments using three RGB-based benchmarks show that our framework offers beyond state-of-the-art accuracy in 3D pose estimation, as well as recovers dense 3D hand shapes. Each technical component above meaningfully improves the accuracy in the ablation study.
这篇文章说的是从二维图像建模三维手部模型。
由于固有的二维-三维映射模糊性和有限的训练数据,从单个RGB图像估计三维手部网格具有挑战性。我们采用一个紧凑的参数化三维手模型来表示可变形和关节化的手网格。为了实现对RGB图像的模型化,我们从三个方面进行了研究和贡献:1)神经渲染:在最近对人体的研究的启发下,我们的手网格估计(HME)由神经网络和可区分的渲染器实现,由2个分割遮罩和3D骨骼监控。结果表明,该方法具有较好的估计性能,能较好地估计各种形状和形状,提高了估计精度。2)迭代测试结果:我们的拟合函数是可微的。我们根据迭代模型确定方法(如ICP)的精神,使用梯度迭代重新确定初始估算。这一想法得到了最新人体研究的支持。3)自数据增强:采集大小的RGB网格(或分割掩模)-骨骼三联体训练是一个很大的障碍。一旦模型成功地被定义为输入RGB图像,它的网格(即形状和关节)是真实的,我们在估计的密集的手姿态上增加了视点。使用三个基于RGB的基准点进行的实验表明,我们的框架在3D姿势估计方面提供了最先进的精度,并且恢复了密集的3D手形。上述各技术组件都有意义地提高了烧蚀研究的准确性。
11. Neural Scene Decomposition(NSD) for Multi-Person Motion Capture
paper
code
介绍:从单个图像中检测人并恢复其姿势
多人检测、三维姿态估计、新的视图合成

提出了一种多视图自监督方法来训练一个网络,以产生一个层次化的场景表示,它是为三维人体姿势捕捉而量身定制的,但一般足以用于其他重建任务。它包括3个抽象层次、空间布局(边界框和相对深度)、实例分割(遮罩)和身体表示(编码外观和姿势的潜在向量)。经过训练的网络就可以运行,不必事先为人们提供位置。它的人物的数量是预先知道的。今后将把这个范围扩大到更多的未知人数。
监督学习(Supervised Learning)
监督学习是使用已知正确答案的示例来训练网络的。
无监督学习(Unsupervised Learning)
无监督学习适用于你具有数据集但无标签的情况。无监督学习采用输入集,并尝试查找数据中的模式。比如,将其组织成群(聚类)或查找异常值(异常检测)。
文献中阅读到的一些无监督的学习技术包括:
自编码(Autoencoding)
主成分分析(Principal components analysis)
随机森林(Random forests)
K均值聚类(K-means clustering)
12. GANFIT: Generative Adversarial Network Fitting for High Fidelity 3D Face Reconstruction
paper
code


从单张图像重建3D人脸模型
本文从一个新的角度重新审视了基于优化的三维人脸重建,即利用Gans和人脸识别网络等最新机器学习技术的力量分别作为统计纹理模型和能量函数。这是Gans首次用于模型制作,它们显示出高质量纹理重建的良好效果。该方法在定性和定量实验中显示了保持身份的高精度三维重建。
13. In the Wild Human Pose Estimation using Explicit 2D Features and Implicit 3D Representation
基于显式二维特征和中间三维表示的自然环境中人体姿态估计
paper

提出了一种新的基于单目彩色图像的三维人体姿态估计深度学习体系结构。它是为训练符合这两种情况的数据而设计的:1.带有三维姿势ground-truth标签的真实图像(这种数据比较少),2.只有二维姿势标签的自然环境中的图像(这种数据比较容易获取)。我们的算法在In-Studio H3.6M数据集上实现了最先进的性能,并且在更具挑战性的MPI-INF-3DHP基准测试和自然环境图像上明显优于相关工作。
作为具有地面实况3D姿势的训练数据,我们使用了H3.6M训练集的组合,以及背景增强和未认证的MPI-INF-3DHP训练集,总共包含350K个训练图像。与只有二维姿势注释的自然环境中训练图像一样,我们使用MPII[1]和LSP[13][14]数据集,这些数据集通过随机剪切、平移和旋转图像进行增强。
14. SimulCap: Single-View Human Performance Capture with Cloth Simulation
paper
人物动态细节绘制

本文提出了一种使用单台RGBD相机进行实时自由视点人体性能动态细节(如布纹)绘制的新方法。我们的主要贡献是:(i)服装和身体的多层表示;(ii)基于物理的性能捕捉程序。我们首先使用多层表面表示法对表演者进行数字化,其中包括未加工的身体表面和单独的衣服网格。对于性能捕获,我们对传入帧依次执行骨架跟踪、布料模拟和迭代深度调整。通过在性能捕捉管道中加入布料模拟,我们可以模拟真实的布料动力学和布料体相互作用,即使是在封闭区域,这在以前的捕捉方法中是不可能的。此外,通过将深度拟合设定为一个物理过程,我们的系统在保持物理约束的同时产生与深度观测一致的布料跟踪结果。结果和评价表明了我们方法的有效性。我们的方法还支持新类型的应用程序,如布料重定目标、FreeViewPoint视频渲染和动画。
更高的真实性是因为我们用于跟踪的前向模型更接近真实世界中身体和衣服的变形情况:骨骼运动使身体变形,进而使其上的衣服变形。建模这个过程允许我们跟踪布料和身体的相互作用。我们还证明了这可以将捕获的衣服重新定位到不同的身体上。我们相信,这一新的捕获方向将使我们能够为分析和合成生成真实的、完全的、可想象的多层虚拟人物,并将在虚拟现实/虚拟现实、虚拟试运行和远程存在等方面打开许多应用。
尽管我们可以重建看似合理的布料动态,即使是对于相对宽松的衣服(如裙子),但在封闭区域实现的真实性受到模拟器质量的限制,并且跟踪非常厚的衣服(如毛衣)仍然具有挑战性。结合更先进的布料模拟器,并考虑到缝纫模式可能会增加实现的真实性。此外,捕捉手/臂和布之间的自然相互作用需要更精确的基于物理的碰撞模型。最后,拓扑结构的变化、面部、手部和软组织不能用同尺重建,这仍然具有挑战性。幸运的是,将衣服和身体分开,可以很容易地集成新的面部模型[36]、手模型[52]和软组织模型[47]。其他潜在的未来方向包括:结合人体软组织模型(如[47])以忠实地捕捉布体相互作用,“从捕捉的结果中学习”数据驱动的服装变形模型,以及推断材料特性。
15. Detailed Human Shape Estimation from a Single Image by Hierarchial Mesh Deformation
paper
code
基于层次网格变形的单个图像的人体形状详细估计

本文提出了一种从单个图像中恢复人体详细形状的新框架。由于人体形状、姿势和视角等因素的变化,这是一项具有挑战性的任务。以前的方法通常尝试使用缺乏表面细节的基于参数的模板来恢复人体形状。因此,由此产生的身体形状似乎没有衣服。本文提出了一种新的基于学习的框架,将参数模型的鲁棒性与自由三维变形的灵活性相结合。我们使用深度神经网络在层次网格变形(HMD)框架中重新定义3D形状,利用来自身体关节、轮廓和每像素着色信息的约束。我们能够在皮肤模型之外恢复人体的详细形状。实验表明,该方法在二维IOU数和三维公制距离方面均优于现有的先进方法,取得了较好的精度。该代码在https://github.com/zhuhao nju/hmd.git中提供。
16. Convolutional Mesh Regression for Single-Image Human Shape Reconstruction
单图像人形重建的卷积网格回归
本文的目标是通过尝试放松对参数模型(通常是SMPL[21])的过度依赖来解决姿势和形状估计问题。虽然我们保留了SMPL网格拓扑结构,而不是直接预测给定图像的模型参数,但我们的目标是首先估计三维网格顶点的位置。为了有效地实现这一点,我们提出了一种图形CNN体系结构,它对网格结构进行了显式编码,并对附着在网格顶点上的图像特征进行了处理。我们的卷积网格回归优于直接回归模型参数的相关基线,用于各种输入表示,而最终,它在基于模型的姿态估计方法中实现了最先进的结果。未来的工作可以集中于当前的局限性(例如,恢复形状中的遗漏细节),以及这种非参数表示提供的机会(例如,捕捉许多人体模型中缺失的方面,如手关节、面部表情、衣服和头发)。
17. RepNet: Weakly Supervised Training of an Adversarial Reprojection Network

paper
本文研究了基于单个图像的三维人体姿态估计问题。长期以来,人类骨骼都是通过满足重投影误差来参数化和确定观测结果的,而现在研究人员直接使用神经网络从观测结果中推断出三维姿势。然而,大多数这些方法忽略了这样一个事实,即必须满足再投影约束,并且对过拟合很敏感。我们通过忽略二维到三维的对应关系来解决过度配置问题。这有效地避免了简单的训练数据记忆,并允许弱监督训练。建议的再投射网络(repnet)的一部分使用对抗训练方法学习从二维姿势分布到三维姿势分布的映射。网络的另一部分估计摄像机。这样就可以定义网络层,将估计的三维姿态重新投影回二维,从而产生重新投影损失功能。我们的实验表明,当应用于未知数据时,repnet可以很好地推广到未知数据,并且优于最先进的方法。此外,我们的实现在标准台式PC上实时运行。
我们的贡献是:•一种基于二维重投影的三维人体姿态估计神经网络(repnet)的对抗性训练方法。•我们在没有2D-3D通信和未知摄像头的情况下监督训练。•同步3D骨骼关键点和摄像头姿态估计。•一个编码包括骨长度和关节角度信息的无向链状表示的层。•一个姿势回归网络,能很好地归纳出未知的人体姿势和摄像头。
18. Capture, Learning, and Synthesis of 3D Speaking Styles
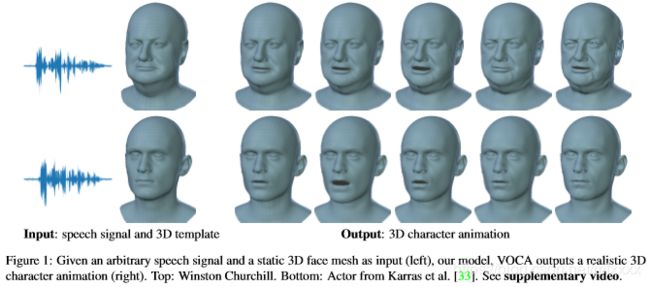
音频驱动的三维人脸动画已经得到了广泛的探索,但实现逼真,接近人的性能仍然没有得到解决。这是由于缺乏可用的三维数据集、模型和标准评估指标。为了解决这个问题,我们引入了一个独特的4D人脸数据集,以60 fps的速度捕获约29分钟的4D扫描,并从12个扬声器同步音频。然后,我们在数据集上训练一个神经网络,该数据集根据面部运动来确定因素。学习的模型,voca(语音操作角色动画)将任何语音信号作为输入,甚至用英语以外的语言输入语音,并在现实中对各种成人面部进行动画处理。在培训期间,主题标签上的调节允许模型学习各种现实的说话风格。voca还提供动画师控件,以在动画期间更改说话风格、身份相关的面部形状和姿势(即头部、下颌和眼球旋转)。据我们所知,voca是唯一一个现实的三维面部动画模型,很容易适用于不重定目标的看不见的对象。这使得voca适合于游戏中的视频、虚拟现实中的虚拟人物,或者任何不预先知道演讲者、演讲人或语言的场景。我们在http://voca.is.tue.mpg.de上提供了用于研究的数据集和模型。
19. Learning to Regress 3D Face Shape and Expression from an Image Without 3D Supervision
学习在没有3D监控的情况下从图像中回归3D人脸形状和表情
code
paper

为了训练一个没有任何二维到三维监控的网络,我们提出了环网,它从一个图像学习计算三维人脸形状。我们的关键观察是,无论表情、姿势、灯光等如何,每个人的面部形状在图像中都是恒定的。Ringnet利用一个人的多个图像并自动检测二维面部特征。它使用了一种新的损失,当不同的人的身份相同和不同时,它鼓励脸型相似。用火焰模型表示人脸,实现了人脸的不变性。一旦训练,我们的方法采取一个单一的图像和输出参数的火焰,可以很容易地动画。此外,我们还创建了一个新的人脸数据库,“不太野生”(现在),其中包括各种条件下受试者的3D头部扫描和高分辨率图像。我们评估了公开可用的方法,发现Ringnet比使用3D监控的方法更准确。数据集、模型和结果可在http://ringnet.is.tuebingen.mpg.de上获得,以供研究之用。
20. Learning 3D Human Dynamics from Video
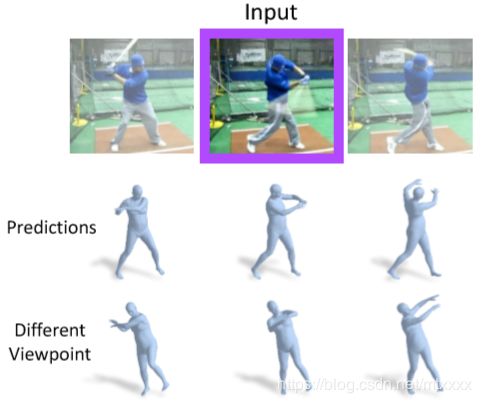
从一个行动中的人的图像,我们可以很容易地猜出这个人在过去和未来的三维运动。我们提出了一个框架,通过对图像特征的时间编码,类似地从视频中学习人类三维动态的表示。从单个图像中,我们的模型可以恢复当前的三维网格以及其过去和将来的三维运动。我们的方法是这样设计的,它可以通过半监督的方式学习视频与二维姿势标注。我们通过训练我们的模型,从现成的二维姿态检测器中获得伪ground-truth的二维姿态,来从互联网获取未标记数据源。我们的实验表明,添加更多的伪ground-truth二维姿态视频可以提高三维预测性能。我们对最近具有挑战性的3D姿势数据集进行了评估,并在不进行任何微调的情况下获得了最先进的3D预测任务性能。
结果:
1)输入视频,可以得到动态的3D人物动作模型视频输出
2)输入图片,可以重建人物的三维模型
21. FaceGenderID: Exploiting Gender Information in DCNNs Face Recognition Systems
人脸识别:利用DCNNS人脸识别系统中的性别信息
本文讨论了在人脸验证系统中,性别作为协变量的影响。尽管基于深度卷积神经网络(DCNN)的预训练模型(如VGG Face或Resnet-50)获得了很高的性能,但它们在包含数百万图像的超大数据集上进行训练,这些数据集在人口统计学方面存在偏见,如性别和种族。在其他中。在这项工作中,我们首先分析这些最先进的男女模特的独立表现。我们观察到两个性别组的面部验证表现之间存在差异。这些结果表明,由偏态模型得到的特征受性别协变量的影响。我们提出了一种基于性别的训练方法,以改进两种性别的特征表示,并发展这两种方法:i)性别特定的DCNNS模型,以及ii)性别平衡的DCNNS模型。我们的研究结果表明,无论是单独还是总体上,我们提出的方法都能显著和一致地改善两种性别的人脸识别性能。最后,我们宣布了本文中提出的facegenderid dcnns模型的可用性(在github1),这可以支持进一步的实验。
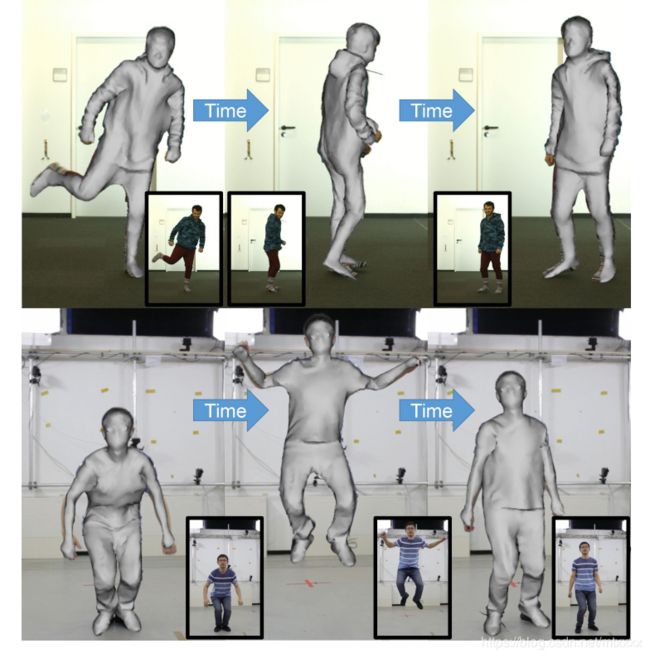
22. Livecap: Real-time Performance Capture from Single RGB Camera
输入视频可以得到动态的3D人物动作模型视频输出
paper
23. Directing DNNs Attention for Facial Attribution Classification using Gradient-weighted Class Activation Mapping
脸部属性区分

这里标记出嘴唇的位置
这个方法还可以标记出鼻子的位置等其他脸部位置
paper
24. Facial Soft Biometrics Detection on Low Power Devices
脸部分析

提出了一种新颖的CNN架构,适用于低功耗设备的实时实现,同时执行性别、年龄、种族、眼睛状态、眼镜等的检测。该体系结构采用了MobileNet体系结构,并利用了各个生物特征之间的相关性,与三种最先进的人脸分析系统相比,其性能相当,同时需要显著降低的计算资源。
25. Learned Image Compression with Residual Coding(图像压缩)
26. A Compression Objective and a Cycle Loss for Neural Image Compression(神经图像压缩)
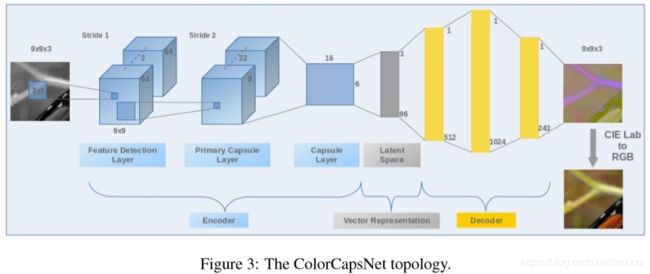
27. Image Colorization By Capsule Networks(黑白图像上色)
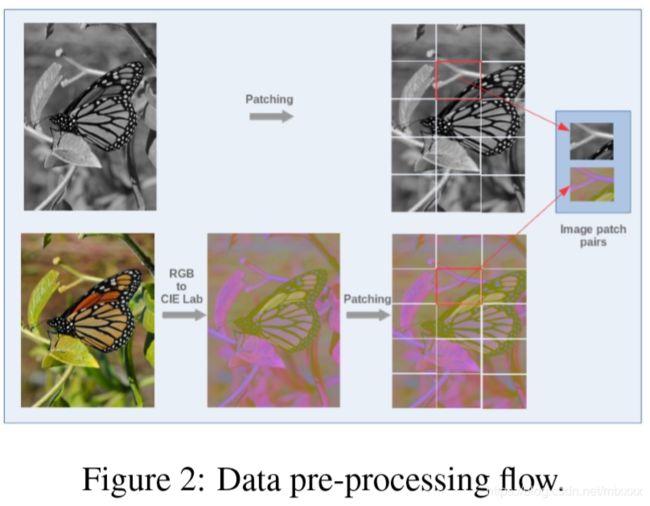
首先将黑白图像分割成小块,分别通过网络映射到CIE Lab 颜色空间,再从这个颜色空间映射到RGB图像,最后拼起来。
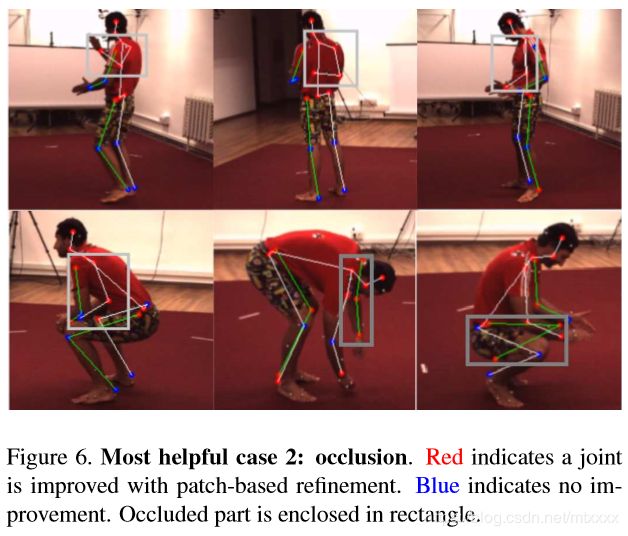
28. Patch-based 3D Human Pose Refinement(三维姿态估计)
最先进的三维人体姿态估计方法通常是从一个向前运行的整个RGB图像中估计姿态。在本文中,我们开发了一个后处理步骤,从身体部位补丁重新确定三维人体姿势估计。使用局部补丁作为输入有两个优点。首先,身体部位周围的细节被放大到高分辨率,以便进行精确的三维姿势预测。第二,它可以使部分外观在姿势之间共享,从而有益于罕见的姿势。为了获得补丁的信息表示,我们探索了不同的输入方式,验证了将预测分割与RGB融合的优越性。我们证明,我们的方法始终提高了最先进的三维人体姿势方法的准确性。
这个方法可以用在任何一个现有的先进技术上来调整并提高三维人体姿态的准确性
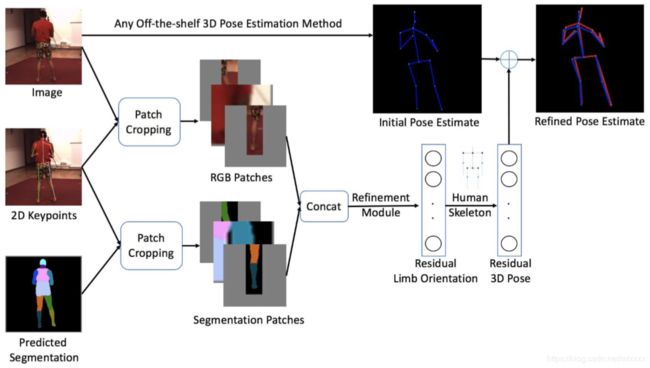
对于一张输入照片,首先预测二维的关键点和分割图,二维的关键点可以用于剪裁得到图片的关键部位小块和分割图的关键部位小块,这些剪裁出来的高分辨率细节图可以通过我们的改进模型获得这些身体部分的方位,再结合根据现有其他最先进方法的预测姿态,可以改进现有的姿态。
29. Event-based attention and tracking on neuromotphic hardware(神经硬件的注意和跟踪)
30. MediaPipe: A Framework for Perceiving and Augmenting Reality
paper
MediaPipe是一个用于构建多模式应用机器学习管道的跨平台框架
机器学习框架?
构建一个处理感知输入的应用程序不仅仅需要运行一个ML模型。开发人员必须利用各种设备的功能;平衡资源使用和结果质量;并行运行多个操作并使用流水线;并确保时间序列数据正确同步。MediaPipe框架解决了这些挑战。开发人员可以使用MediaPipe轻松快速地将现有和新的感知组件组合到原型中,并将它们推进到经过打磨的跨平台应用程序中。开发人员可以配置一个使用MediaPipe构建的应用程序,以便有效地管理资源(CPU和GPU),以获得低延迟性能,处理音频和视频帧等时间序列数据的同步,并测量性能和资源消耗。我们表明,这些特性使开发人员能够专注于算法或模型开发,并将MediaPipe用作迭代改进其应用程序的环境,结果在不同的设备和平台上都是可复制的。MediaPipe将在https://github.com/google/mediapipe上开放。
MediaPipe允许对任意数据类型进行操作,并为流式时间序列数据提供本机支持。
MediaPipe由三个主要部分组成:(1)感官数据推理框架;(2)一套性能评估工具;(3)可重用推理和处理组件的集合。
举的例子是object detecting 和
31. Learning-Based Image Compression using Convolutional Autoencoder and Wavelet Decomposition(图像压缩)
32. On-Device AR with Mobile GPUs
本文研究了产生图像的实时处理技术,特别是在使用图形处理单元的设备上。讨论了移动设备上图像处理的问题和局限性,并通过Canny边缘检测的可编程着色实现,测量了一系列设备上图形处理单元的性能。
33. BlazeFaces: Sub-millisecond Neural Face Detection on Mobile GPUs
34. Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs


我们提出了一个基于端到端神经网络的模型,用于从AR应用的单相机输入中推断人脸的近似三维网格表示。468个顶点的相对密集网格模型非常适合于基于面的AR效果。该模型在移动GPU上具有超实时推理速度(100-1000+fps,取决于设备和模型变量),预测质量高,可与同一图像的人工注释差异相媲美。
35. Real-time Hair segmentation and recoloring on Mobile GPUs
我们提出了一种基于神经网络的头发分割的新方法,从一个摄像头输入专门设计的实时,移动应用程序。我们相对较小的神经网络产生了一个高质量的头发分割面膜,非常适合AR效果,例如虚拟头发重新着色。该模型在移动GPU(30-100+fps,取决于设备)上实现了高精度的实时推理速度。我们还提出了一个非常现实的头发脱色方案。我们的方法已经部署在主要的AR应用程序中,并被数百万用户使用。

36. High-Quality AR Lipstick Simulation via Image Filtering Techniques


本文提出了一种新的AR口红模拟技术,产生高品质的视觉效果。它的设计强调了简单性和使用现有的图像过滤技术。由于其独特的性质,所提出的技术可以由软件工程师和视觉设计师实现。我们的方法在各种肤色和照明条件下都很稳健。它在现代中高端智能手机上达到720p分辨率的实时性能。
37. Nail Polish Try-on: Realtime Semantic Segmentation of Small Objects for Native and Browser Smartphone AR Applications
指甲油试涂(在智能手机上实现小对象的语义分割)
38. Lightweight Mobile Remote Collaboration using Mixed Reality(远程协作)
39. Human Hair Segmentation In The Wild Using Deep Shape Prior(头发分割)
40. Towards Scalable Sharing of Immersive Live Telepresence Experiences Beyond Room-scale based on Efficient Real-time 3D Reconstruction and Streaming
基于高效的实时3D重建和流媒体,实现超出室内规模的沉浸式实时远程呈现体验的可扩展共享
我们提供了一个框架,用于为任意大小的环境中的远程用户组共享身临其境的实时远程呈现体验。 我们的框架建立在本地环境(由人或机器人)的RGB-D数据捕获的基础上,涉及实时3D重建,可扩展数据流和可视化,以适度的带宽要求和低延迟,同时保留视觉的多个远程用户 当前实时重建方法的质量。
41. Lightweight Real-time Makeup Try-on in Mobile Browsers with Tiny CNN Models for Facial Tracking(手机模拟上妆)
42. HoloPose: Holistic 3D Human Reconstruction In-The-Wild
可以根据视频生成动态的三维人体造型

我们介绍了HoloPose,一种整体3D人体重建方法。 我们首先介绍一个基于部件的3D模型参数回归模型,它允许我们的方法在自然图像上操作,优雅地处理严重的遮挡和大的姿势变化。 我们进一步训练包括2D,3D和密集姿势估计的多任务网络以驱动3D重建任务。 为此,我们引入了一种迭代细化方法,该方法将基于模型的2D / 3D关节位置和DensePose三维估计与CNN提供的基于图像的对应物进行对齐,实现基于模型,全局一致性和高空间精度的底部 CNN处理。 我们验证了我们对具有挑战性的基准测试的贡献,表明我们的方法允许我们获得准确的关节和3D表面估计,同时以超过10fps的速度运行。 有关我们的方法的更多信息,包括视频和演示,请访问http://arielai.com/holopose。
43. Efficient 2.5D Hand Pose Estimation via Auxiliary Multi-Task Training for Embedded Devices(手部位姿)
包括:2D手部关节点估计,再根据深度传感器捕获的深度信息表示成2.5D
44. Disguised Faces in the Wild
一个包含了伪装的人脸的数据集 人脸识别
45. Face Hallucination Revisited: An Exploratory Study on Dataset Bias
从低分辨率面部图像重建高分辨率面部图像
当代面部幻觉(FH)模型展示了从低分辨率(LR)面部图像重建高分辨率(HR)细节的相当大的能力。这种能力通常是从相应的HRLR图像对的例子中学习的,这些图像对是通过人工下采样HR地面实况数据而创建的。该下采样(或降级)过程不仅定义了LR训练数据的特征,而且还确定了学习的FH模型最终能够处理的图像劣化的类型。如果真实世界LR图像遇到的图像特征与训练期间看到的图像特征不同,FH模型仍然可以表现良好,但实际上可能无法产生预期的结果。在本文中,我们研究了这个问题,并通过训练数据的特点探讨了引入FH模型的偏差。我们系统地分析了几种FH模型在各种情况下的泛化能力,其中降级函数与训练设置不匹配,并通过综合降级以及现实生活中的低质量图像进行实验。我们制作了一些有趣的发现,可以深入了解FH模型存在的问题并指出未来的研究方向。
46. Multimodal 2D and 3D for In-the-wild Facial Expression Recognition
用于面部表情识别的多模2D和3D
在本文中,与仅关注2D信息的其他野外面部表情识别(FER)研究不同,我们提出了FER中2D和3D面部数据的融合方法。具体地,首先从图像数据集重建3D面部数据。然后通过深度学习技术提取3D信息,该技术可以利用有意义的面部几何细节进行表达。我们通过将3D面部的2D投影图像作为FER的附加输入,进一步展示了使用3D面部数据的潜力。这些功能与典型网络中的2D功能融合在一起。根据最近研究中的实验程序,通过线性支持向量机(SVM)对级联特征进行分类。进一步进行综合实验,整合面部特征用于表达预测。结果表明,该方法在RAF数据库和SFEW 2.0数据库上均实现了最先进的识别性能。这是第一次在野外FER的背景下呈现这种3D和2D面部模态的深度学习组合。
47. Single Image Based Metric Learning via Overlapping Blocks Model for Person Re-Identification
基于单图像的度量学习通过重叠块模型进行人员重新识别
行人再识别:是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。
在本文中,我们提出了一种新的基于块的人重新识别方法,称为重叠块模型(OBM),其中使用卷积特征上的重叠分区的创新策略来构造多个重叠块结构和新的重叠块丢失函数。 用于测量单个图像中不同块之间的差异,以确保更多块可以带来更多的区分信息和更高的性能。 我们对Market-1501,CUHK03和DukeMTMC-reID数据集进行了彻底的验证实验,证明了我们提出的重叠块模型可以通过添加多个重叠块结构和重叠块丢失来有效地提高网络的识别性能。
48. Attention-guided Network for Ghost-free High Dynamic Range Imaging
由移动物体或未对准引起的重影伪像是动态场景的高动态范围(HDR)成像中的关键挑战。先前的方法首先在合并它们之前使用光流注册输入的低动态范围(LDR)图像,这些图像容易出错并且导致结果中的重影。最近的一项工作试图通过具有跳过连接的深度网络绕过光流,但是仍然存在严重移动的重影伪像。为了避免来源的鬼影,我们提出了一种新颖的注意力引导端到端深度神经网络(AHDRNet)来产生高质量的无鬼HDR图像。与先前直接堆叠LDR图像或用于合并的特征的方法不同,我们使用注意模块来引导根据参考图像的合并。注意模块自动抑制由未对准和饱和引起的不期望的分量,并增强非参考图像中期望的精细细节。除了注意模型之外,我们还使用扩张的残余密集块(DRDB)来充分利用分层特征,并增加感知区域以消除丢失的细节。所提出的AHDRNet是一种非基于流的方法,它还可以避免由光流估计误差产生的伪像。对不同数据集的实验表明,所提出的AHDRNet可以实现最先进的定量和定性结果。
49. Sea-thru: A Method for Removing Water from Underwater Images
从水下照片移除水
50. Attentive Feedback Network for Boundary-Aware Salient Object Detection
目标检测(注意边界的细节)