Hive基本操作(二)
GROUP BY语句
1.创建分区表语法
create table score(s_id string,c_id string, s_score int) partitioned by (month string) row format delimited fields terminated by ‘\t’;
2.加载数据到分区表中
load data local inpath ‘/home/score.csv’ into table score partition (month=‘201909’);
3.GROUP BY语句通常会和聚合函数一起使用,按照一个或者多个列队结果进行分组,然后对每个组执行聚合操作。
案例实操:
(1)计算每个学生的平均分数
select s_id ,avg(s_score) from score group by s_id;
注意group by的字段,必须是select后面的字段,select后面的字段不能比group by的字段多
(2)计算每个学生最高成绩
select s_id ,max(s_score) from score group by s_id;
HAVING语句
1.having与where不同点
(1)where针对表中的列发挥作用,查询数据;having针对查询结果中的列发挥作用,筛选数据。
(2)where后面不能写分组函数,而having后面可以使用分组函数。
(3)having只用于group by分组统计语句。
2.案例实操:
求每个学生的平均分数
select s_id ,avg(s_score) from score group by s_id;
求每个学生平均分数大于85的人
select s_id ,avg(s_score) avgscore from score group by s_id having avgscore > 85;
JOIN语句
等值JOIN
老版本中,不支持非等值的join
在新版中:1.2.0后,都支持非等值join,不过写法应该如下:
案例操作
1.查询分数对应的姓名
创建学生表老师表:
create table student (s_id string,s_name string,s_birth string , s_sex string ) row format delimited fields terminated by ‘\t’;
create table teacher (t_id string,t_name string) row format delimited fields terminated by ‘\t’;
加载数据
load data local inpath ‘/home/teacher.csv’ into table teacher;
load data local inpath ‘/home/student.csv’ into table student;
SELECT s.s_id,s.s_score,stu.s_name,stu.s_birth FROM score s LEFT JOIN student stu ON s.s_id = stu.s_id;
表的别名
1)好处
(1)使用别名可以简化查询。
(2)使用表名前缀可以提高执行效率。
2)案例实操
合并老师与课程表
select * from teacher t join course c on t.t_id = c.t_id;
内连接(INNER JOIN)
内连接:只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。
select * from teacher t inner join course c on t.t_id = c.t_id;
左外连接(LEFT OUTER JOIN)
左外连接:JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。
查询老师对应的课程
select * from teacher t left join course c on t.t_id = c.t_id;
右外连接(RIGHT OUTER JOIN)
右外连接:JOIN操作符右边表中符合WHERE子句的所有记录将会被返回。
select * from teacher t right join course c on t.t_id = c.t_id;
满外连接(FULL OUTER JOIN)
满外连接:将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
SELECT * FROM teacher t FULL JOIN course c ON t.t_id = c.t_id ;
多表连接
注意:连接 n个表,至少需要n-1个连接条件。例如:连接三个表,至少需要两个连接条件。
多表连接查询,查询老师对应的课程,以及对应的分数,对应的学生
设置表头:
set hive.cli.print.header=true;
select * from teacher t
left join course c
on t.t_id = c.t_id
left join score s
on s.c_id = c.c_id
left join student stu
on s.s_id = stu.s_id;
大多数情况下,Hive会对每对JOIN连接对象启动一个MapReduce任务。本例中会首先启动一个MapReduce job对表teacher和表course进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表score;进行连接操作。
排序
全局排序(Order By)
Order By:全局排序,一个reduce
1)使用 ORDER BY 子句排序
ASC(ascend): 升序(默认)
DESC(descend): 降序
2)ORDER BY 子句在SELECT语句的结尾。
3)案例实操
(1)查询学生的成绩,并按照分数降序排列
SELECT * FROM student s LEFT JOIN score sco ON s.s_id = sco.s_id ORDER BY sco.s_score DESC;
(2)查询学生的成绩,并按照分数升序排列
SELECT * FROM student s LEFT JOIN score sco ON s.s_id = sco.s_id ORDER BY sco.s_score asc;
按照别名排序
按照分数的平均值排序
select s_id ,avg(s_score) avg from score group by s_id order by avg;
多个列排序
按照学生id和平均成绩进行排序
select s_id ,avg(s_score) avg from score group by s_id order by s_id,avg;
每个MapReduce内部排序(Sort By)局部排序
Sort By:每个MapReduce内部进行排序,对全局结果集来说不是排序。
1)设置reduce个数
set mapreduce.job.reduces=3;
2)查看设置reduce个数
set mapreduce.job.reduces;
3)查询成绩按照成绩降序排列
select * from score sort by s_score;
将查询结果导入到文件中(按照成绩降序排列)
insert overwrite local directory ‘/export/servers/hivedatas/sort’ select * from score sort by s_score;
分区排序(DISTRIBUTE BY)
Distribute By:类似MR中partition,进行分区,结合sort by使用。
注意,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
案例实操:
1.先按照学生id进行分区,再按照学生成绩进行排序。
设置reduce的个数,将我们对应的s_id划分到对应的reduce当中去
set mapreduce.job.reduces=7;
2.通过distribute by 进行数据的分区
insert overwrite local directory ‘/home/sort’ select * from score distribute by s_id sort by s_score;
CLUSTER BY
当distribute by和sort by字段相同时,可以使用cluster by方式。
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒序排序,不能指定排序规则为ASC或者DESC。
以下两种写法等价
select * from score cluster by s_id;
select * from score distribute by s_id sort by s_id;
小技巧
可以在hive中执行linux命令
hive> !ls /root;
在hive中显示字段名
hive> set hive.cli.print.header=true;
hive> set hive.resultset.use.unique.column.names=false;
函数
首先为了测试函数,我们先随便建一张表
hive> create table dual(id string);
hive> insert into table dual values(1);
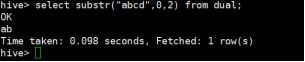
例如:要测试函数substr怎么使用
hive> select substr(“abcd”,0,2) from dual;
日期函数
hive> select current_date from dual;
![]()
hive> select current_timestamp from dual;

hive> select unix_timestamp() from dual;

hive> select unix_timestamp(‘2019-05-07 13:01:03’) from dual;

hive> select unix_timestamp(‘20190507 13:01:03’,‘yyyyMMdd HH:mm:ss’) from dual;
![]()
hive> select from_unixtime(1557205263,‘yyyy-MM-dd HH:mm:ss’) from dual;
![]()
获取日期、时间
hive> select year(‘2011-12-08 10:03:01’) from dual;

hive> select year(‘2012-12-08’) from dual;

select month(‘2011-12-08 10:03:01’) from dual;
12
select month(‘2011-08-08’) from dual;
8
select day(‘2011-12-08 10:03:01’) from dual;
8
select day(‘2011-12-24’) from dual;
24
select hour(‘2011-12-08 10:03:01’) from dual;
10
select minute(‘2011-12-08 10:03:01’) from dual;
3
select second(‘2011-12-08 10:03:01’) from dual;
1
日期增减
select date_add(‘2012-12-08’,10) from dual;
2012-12-18
date_sub (string startdate, int days) : string
例:
select date_sub(‘2012-12-08’,10) from dual;
2012-11-28
Json函数解析
电影topn
将数据rating.json上传到hdp03的/home下
在hive中先创建一张表,将一行的json看做一个字段
hive> create table t_rate_json(line string) row format delimited;
导入数据
hive> load data local inpath ‘/home/rating.json’ into table t_rate_json;
创建一张表,存储解析后的数据
hive> create table t_rate(movie string,rate int,ts string,uid string) row format delimited fields terminated by ‘\001’;
解析json函数使用get_json_object函数
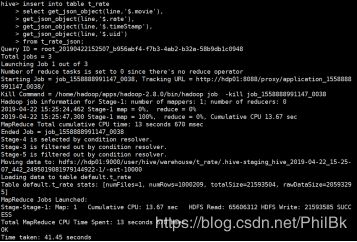
测试:
hive> select get_json_object(line,"$.movie") from t_rate_json limit 2;


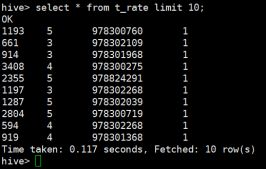
hive> select * from t_rate limit 10;
统计评分大于3的所有评分记录
hive> select * from t_rate where rate > 3;
统计每个人评分的总分数
hive> select uid,sum(rate) from t_rate group by uid;
统计每个人评分的总分数倒序排
hive> select uid,sum(rate) rate_sum from t_rate group by uid order by rate_sum desc;
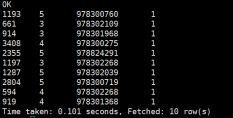
统计每个人评分的总分数倒序排,前10个;
hive> select uid,sum(rate) rate_sum from t_rate group by uid order by rate_sum desc limit 10;
另外一种json解析的方法:
测试:
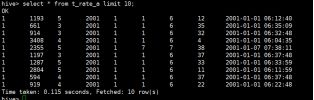
hive> select
json_tuple(line,“movie”,“rate”,“timeStamp”,“uid”)
as(movie,rate,ts,uid)
from t_rate_json
limit 10;
hive> create table t_rate_a
as
select uid,movie,rate,year(from_unixtime(cast(ts as bigint))) as year,month(from_unixtime(cast(ts as bigint))) as month,day(from_unixtime(cast(ts as bigint))) as day,hour(from_unixtime(cast(ts as bigint))) as hour,
minute(from_unixtime(cast(ts as bigint))) as minute,from_unixtime(cast(ts as bigint)) as ts
from
(select
json_tuple(line,‘movie’,‘rate’,‘timeStamp’,‘uid’) as(movie,rate,ts,uid)
from t_rate_json) tmp;
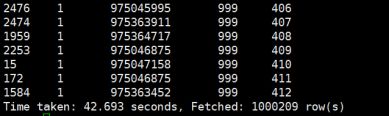
分组topn
hive> select *,row_number() over(partition by uid order by rate desc) as rank from t_rate;
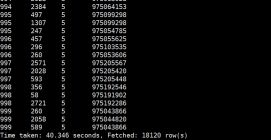
hive> select uid,movie,rate,ts
from
(select uid,movie,rate,ts,row_number() over(partition by uid order by rate desc) as rank from t_rate) tmp
where rank<=3;
网址解析
例如有网址:http://www.baidu.com/find?cookieid=4234234234
解析成:www.baidu.com /find cookieid 4234234234
测试:
hive> select parse_url_tuple(“http://www.baidu.com/find?cookieid=4234234234”,‘HOST’,‘PATH’,‘QUERY’,‘QUERY:cookieid’)
from dual;

explode 和 lateral view
vi sutdent.txt
1,zhangsan,数学:语文:英语:生物
2,lisi,数学:语文
3,wangwu,化学:计算机:java
hive> create table t_xuanxiu(uid string,name string,kc array)
row format delimited
fields terminated by ‘,’
collection items terminated by ‘:’;
加载数据:
hive> load data local inpath “/home/student.txt” into table t_xuanxiu;
hive> select uid,name,kc[0] from t_xuanxiu;
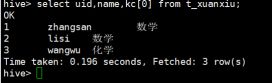
希望得到:
1,zhangsan,数学
1,zhangsan,语文
1,zhangsan,英语
1,zhangsan,生物
2,lisi,数学
2,lisi,语文
…
测试:
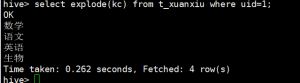
hive> select explode(kc) from t_xuanxiu where uid=1;
可以讲一个数组变成列
问题:
hive> select uid,name,explode(kc) from t_xuanxiu where uid=1;
![]()
lateral view 表生成函数
但是实际中经常要拆某个字段,然后一起与别的字段一起出.例如上面的id和拆分的array元素是对应的.我们应该如何进行连接呢?我们知道直接select id,explode()是不行的.这个时候就需要lateral view出厂了.
lateral view为侧视图,意义是为了配合UDTF来使用,把某一行数据拆分成多行数据.不加lateral view的UDTF只能提取单个字段拆分,并不能塞会原来数据表中.加上lateral view就可以将拆分的单个字段数据与原始表数据关联上.
在使用lateral view的时候需要指定视图别名和生成的新列别名
hive> select uid,name,tmp.course from t_xuanxiu
lateral view explode(kc) tmp as course;
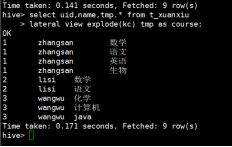
解释:lateral view 将 explode(kc) 看成一个表是 tmp 就一个字段as course;
思考用hive做wordcount?
[root@hdp03 home]# vi words.txt
a b c d e f g
a b c
e f g a
b c d b
hive> create table t_juzi(line string) row format delimited;
hive> load data local inpath “/home/words.txt” into table t_juzi;
hive> select * from t_juzi;

hive> select explode(split(line,’ ')) from t_juzi;

将打散的结果看成一个表
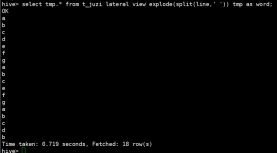
hive> select tmp.* from t_juzi lateral view explode(split(line,’ ‘)) tmp as word;
hive> select a.word,count(1) sum
from
(select tmp.* from t_juzi lateral view explode(split(line,’ ‘)) tmp as word) a
group by a.word
Order by sum desc;
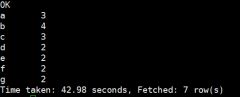
根据单词的数量倒序排序
hive> select a.word,count(1) sum
from
(select tmp.* from t_juzi lateral view explode(split(line,’ ')) tmp as word) a
group by a.word
order by sum desc;
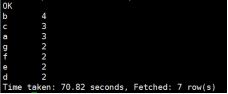
rownumber() 和 over()函数
常用用于求分布topn
测试:求每个人前两高的分数
vi score.txt
zhangsan,1,90,2
zhangsan,2,95,1
zhangsan,3,68,3
lisi,1,88,3
lisi,2,95,2
lisi,3,98,1
hive> create table t_score(name string,kcid string,score int)
row format delimited
fields terminated by ‘,’;
hive>load data local inpath ‘/home/score.txt’ into table t_score;
hive> select *,row_number() over(partition by name order by score desc) rank from t_score;
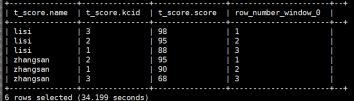
hive>select name,kcid,score
from
(select *,row_number() over(partition by name order by score desc) as rank from t_score) tmp
where rank<3;
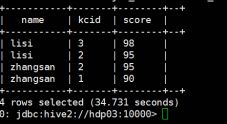
求出每个用户评分最高的3部电影
hive> create table t_rate_topn_uid
as
select uid,movie,rate,ts
from
(select *,row_number() over(partition by uid order by rate desc) as rank from t_rate) tmp
where rank<11;
hive> select * from t_rate_topn_uid where uid=1;

自定义函数
有如下数据
vi user.txt
1,zhangsan:20-1999063017:30:00-beijing
2,lisi:30-1989063017:30:00-shanghai
3,wangwu:22-1997063017:30:00-neimeng
hive> create table user_info(info string)
row format delimited;
hive> load data local inpath ‘/home/user.txt’ into table user_info;
需求:利用上表生成如下表t_user
uid,name,age,birthday,address
思路:可以自定义一个函数parse_user_info,能传入一行数据,返回切分好的字段
写如下hql实现:
create t_user
as
select
parse_user_info(info,0) as uid,
parse_user_info(info,1) as uname,
parse_user_info(info,2) as age,
parse_user_info(info,3) as birthday_date,
parse_user_info(info,4) as birthday_time,
parse_user_info(info,5) as address
from user_info;
核心就是实现parse_user_info()函数
实现步骤:
1.写一个java类实现函数所需要的功能
public class UserInfoParser extends UDF{
public String evaluate(String line,int index) {
String newLine = line.replaceAll(",", "\001").replaceAll(":", "\001").replaceAll("-", "\001");
StringBuffer sb = new StringBuffer();
String[] split = newLine.split("\001");
StringBuffer append = sb.append(split[0])
.append("\t")
.append(split[1])
.append("\t")
.append(split[2])
.append("\t")
.append(split[3].substring(0,8))
.append("\t")
.append(split[3].substring(8, 10)).append(split[4]).append(split[5])
.append("\t")
.append(split[6]);
String res = append.toString();
return res.split("\t")[index];
}
public static void main(String[] args) {
UserInfoParser parser = new UserInfoParser();
String evaluate = parser.evaluate("1,zhangsan:20-1999063017:30:00-beijing",2);
System.out.println(evaluate);
}
}
2.将java类打成jar包
3.上传hiveudf.jar到hive所在的机器上
4.在hive的提示符中添加jar包
hive> add jar /home/hiveudf.jar;
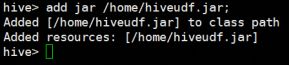
5.创建一个hive的自定义函数跟写好的jar包中的java类对应
hive> create temporary function parse_user_info as ‘UserInfoParser’;

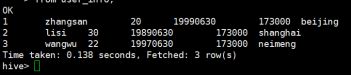
hive> select
parse_user_info(info,0) as uid,
parse_user_info(info,1) as uname,
parse_user_info(info,2) as age,
parse_user_info(info,3) as birthday_date,
parse_user_info(info,4) as birthday_time,
parse_user_info(info,5) as address
from user_info;
需求:1999-06-30 17:30:00
首先在linux创建一个文件movi.txt
U1,m1,5
U1,m2,6
U1,m3,10
U2,m4,2
U2,m5,6
U2,m6,10
创建hive外部表
create external t_rate(uid string,movie string,rate int)
row format delimited
files terminated by ‘,’
location ‘/home/rate’;
这样我们就创建了一个hive表
可以查看hive表
Select * from t_rate;
查看每个人电影评分最高的那个人
select uid,max(rate) from t_rate group by uid;
帮你把文件映射成一个表,帮你把sql语法解析成mapreduce
可以将刚才的查询结果映射成另一张表
create table_max_rate
as
select uid,max(rate) as max_rate from t_rate group by uid;