论文阅读笔记 Transfer learning for sequence tagging with hierarchical recurrent networks
论文地址 https://arxiv.org/abs/1703.06345
论文中的项目代码地址 https://github.com/kimiyoung/transfer
本文探讨了神经序列标记器的转移学习问题,其中使用具有丰富注释的源任务(例如,Penn Treebank上的POS标记)来改善具有较少可用注释的目标任务的性能(例如,POS标记为微博)。
1、介绍
有没有办法通过共享模型参数和特征表示与另一个任务来利用神经网络的通用性来提高任务性能?
为了解决上述问题,我们研究了转移学习设置,旨在通过与源任务的联合培训来提高目标任务的性能。我们提出了一种基于深层次递归神经网络的转移学习方法。我们研究了跨域(cross-domain),跨应用(cross-application)和跨语言(cross-lingual)迁移,并为每种情况提供参数共享架构。
2、相关工作
自然语言处理(NLP)任务的转移学习,基于资源的迁移(resource-based transfer)和基于模型(model-based transfer)的迁移有两种常见的范例(paradigms)。基于资源的迁移主要限于以前的工作中的跨语言转移,并且没有广泛的研究将基于资源的方法扩展到跨域和跨应用设置。
(Peng&Dredze(2016)研究了基于递归神经网络的中文命名实体识别和分词之间的转移学习。PS: 这个是本论文中引用的与中文任务相关的论文,特摘出来)
3、方法
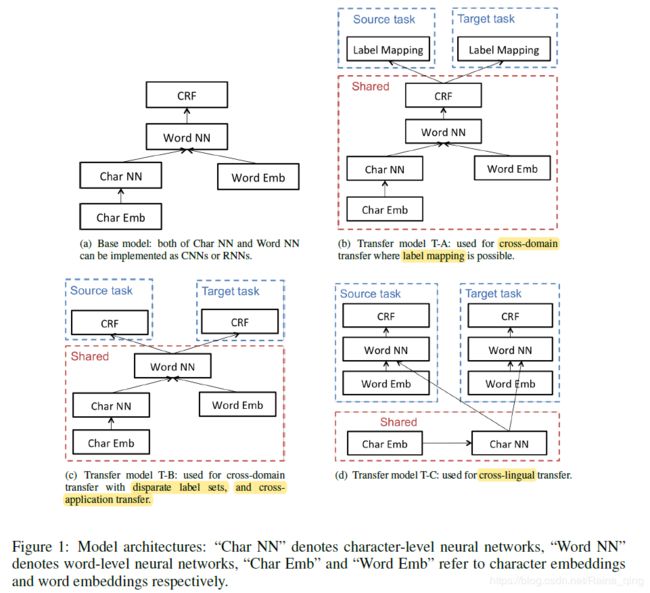
3.1基线模型
见Figure 1(a).
3.2迁移学习架构
我们开发了三种用于转移学习的架构,T-A,T-B和T-C,分别在图1(b),1(c)和1(d)中示出。
3.2.1跨域迁移
我们假设目标域中有少量标签可用。有两种跨域转移:
1、如果这两个域具有可映射的标签集,我们在神经网络中共享所有模型参数和特征表示,Figure 1(b).。
2、如果两个域具有不同的标签集,我们将CRF层中的参数共享,Figure 1(c)。
3.2.2跨应用迁移
在跨应用设置中,我们假设多个应用使用相同的语言。由于不同的应用程序共享相同的字母表,因此案例类似于使用不同标签集的跨域传输。我们采用模型T-B的体系结构进行跨应用程序传输学习,其中只有CRF层与不同的应用程序不相交。
3.2.3跨语种迁移
我们的方法侧重于具有相似字母表的语言之间的转移学习,通过利用两种语言共享的形态来实现模型级转移学习。例如,英语中的“Canada”和西班牙语中的“Canad'a”指的是相同的命名实体,并且形态相似性可以用于NER以及用名词进行POS标记。因此,我们在不同语言之间共享字符嵌入和字符级层以进行转移学习,如图1(d)中的模型T-C所示。
3.3训练
参数分两种(三块)task specific parameters和shared parameters。
![]()
其中共享参数Wshared由两个任务联合优化,而任务特定参数Ws; spec和Wt; spec分别针对每个任务进行训练。
3.4模型应用
使用的cell是gru
4实验
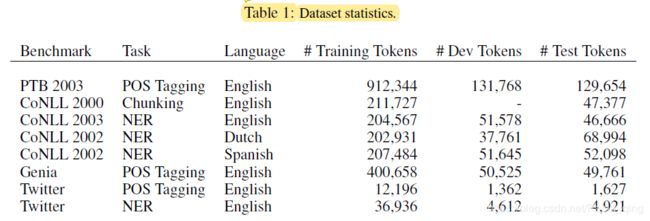
数据集见表1
4.2迁移学习表现
除了Twitter数据集,这些数据集相当大。为了模拟低资源设置,我们还使用数据的随机子集。我们在0.001, 0.01, 0.1和1.0处改变目标任务的标记率。转移学习的结果绘制在图2中,我们在各种标记率下比较有和没有转移学习的结果。

(以下是摘取出的重要结论)
我们可以看到,我们的转移学习方法比非转移结果持续改进。我们还观察到,当标记率较低时,转移学习的改善更为显着。
图2进一步表明,不同体系结构的改进顺序如下:T-A> T-B> T-C。这种现象可以解释为T-A共享模型参数最多而T-C共享最少的事实。诸如跨语言转移之类的转移设置只能使用T-C,因为源任务和目标任务之间的潜在相似性不那么突出(即,可转移性较低),并且在那些情况下,通过转移学习的改进不太重要。
结果表明,当转移变为“间接”时(即源任务和目标任务更松散地相关),转移学习的改进减少。
我们观察到当共享较少的参数时性能增益降低(即,T-A> T-B> T-C)。
5、结论
在本文中,我们开发了一种用于序列标记的转移学习方法,该方法利用了以前工作中深度神经网络所展示的一般性。
我们设计了三种神经网络架构,用于跨域,跨应用和跨语言传输的设置。
我们的转移学习方法在资源匮乏的条件下实现了对各种数据集的显着改进,并在一些基准测试中实现了最新的最新结果。
通过全面的实验,我们观察到以下因素对于我们的转移学习方法的表现至关重要:a)目标任务的标签丰度,b)源任务和目标任务之间的相关性,以及c)可以参数的数量共享。
将来,将基于模型的转移(如本工作)与基于资源的转移结合起来进行跨语言转移学习将会很有趣。