【 C 】在单链表中插入一个新节点的尝试(一)
根据《C和指针》中讲解链表的知识,记录最终写一个在单链表中插入一个新节点的函数的过程,这个分析过程十分的有趣,准备了两篇博文,用于记录这个过程。
链表是以结构体和指针为基础的,所以结构体和指针是需要首先掌握的知识,掌握之后,最后要明白这个问题:结构体的自引用
这时候就可以尝试链表的学习了。记得去年学习链表的时候觉得特别新奇,并使用之写了一个蹩脚的学生信息管理系统,当然不值一提,可惜没有趁热打铁继续下去,也许不是坏事,醒悟的时候还不算晚!
先介绍下链表吧:
链表(linked list)就是一些包含数据的节点的集合。这些节点是用结构体定义的,如下:
typedef struct NODE{
struct NODE *link;
int value;
} Node;使用typedef定义了一个结构类型的别称Node,称为节点。
链表中的每个节点通过指针(也叫链)链接一起。程序通过指针访问链表中的节点。通常节点是动态分配的,但是有时你也能看到由节点数组创建的链表。即使在这种情况下,程序也是通过指针来遍历链表的。我们关注的是动态内存分配来创建节点。
在单链表中,每个节点包含一个指向链表下一个节点的指针。链表最后一个节点的指针字段的值为NULL,提示链表后面不再有其他节点。在你找到链表的第一个节点后,指针就可以带你访问剩余的所有节点。为了记住链表的起始位置,可以使用一个根指针(root pointer)。根指针指向链表的第一个节点。注意根指针只是一个指针,它不包含任何数据。
下面是一个单链表的图:
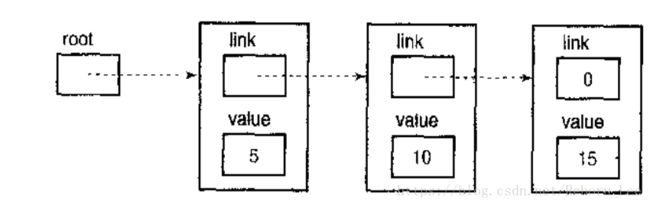
从上面的图中可以看出,这些节点相邻在一起,这是为了显示链表所提供的逻辑顺序。事实上,链表中的节点可能分布于内存中的各个地方。对于一个处理链表的程序而言,各节点在物理上是否相邻并没有什么区别,因为程序始终用指针(链)从一个节点移动到另一个节点。
但链表可以通过链从开始位置遍历链表直到结束位置,但链表无法从相反的方向进行遍历。
上面显示的链表中,节点根据数据的值按升序链接在一起。对于有些应用程序而言,这种顺序非常重要,比如根据一天的时间安排约会。对于那些不要求排序的应用程序,当然也可以创建无序的单链表。
下面正式进入正题:在单链表中插入一个新节点的第一次尝试:
如何才能把一个新节点插入到一个有序的单链表中呢?
假定我们有一个新值,比如12,想把它插入到上面提到的那个链表中。从概念上讲,是很容易做到的,从链表的起始位置开始,跟随指针直到找到第1个值大于12的节点,然后把这个新值插入到那个节点之前的位置。
实际的算法比较有趣:我们按顺序访问链表,当到达内容为15的节点(第一个值大于12的节点)时就停下来。我们知道这个新值应该添加到这个节点之前,但前一个节点的指针必须进行修改以实现这个插入。但是我们已经越过了这个节点,无法返回。解决这个问题的办法是始终保存一个指向链表当前节点之前的那个节点的指针。
了解这么多,我们就可以开始实践了:
首先定义一个头文件:
typedef struct NODE{
struct NODE *link;
int value;
} Node;存放于sll_node.h的头文件中。
下面开发一个函数,把一个节点插入到一个有序的单链表中,后面并做出详细分析:
//插入到一个有序的单链表。函数的参数是一个指向链表第一个节点的指针以及需要插入的值
#include
#include
#include "sll_node.h" //这个头文件是前面自己创建的
#define FALSE 0
#define TRUE 1
int sll_insert( Node *current, int new_value )
{
Node *previous;
Node *new; //需要插入的新节点
//寻找正确的插入位置,方法是顺序访问链表,直到到达其值大于或等于新插入的节点的值
while( current->value < new_value )
{
previous = current; //始终保存当前节点之前的那个节点
current = current->link; //当前节点移动到下一个节点
}
//为新节点分配内存,并把新值存储到新节点中,如果内存分配失败,函数返回FALSE
new = ( Node *)malloc( sizeof( Node ) );
if( new == NULL )
{
return FALSE;
}
new->value = new_value;
//把新节点插入到链表中,并返回TRUE
new->link = current; //新节点的指针指向当前节点
previous->link = new; //前一个节点的指针指向新节点
return TRUE;
}
我们用下面的方法调用这个函数:
result = sll_insert( root, 12 );
下面跟踪代码的执行过程:
首先传递给函数的参数是root变量的值,它是指向链表的第一个节点的指针。当函数刚刚执行时,链表的状态如下:
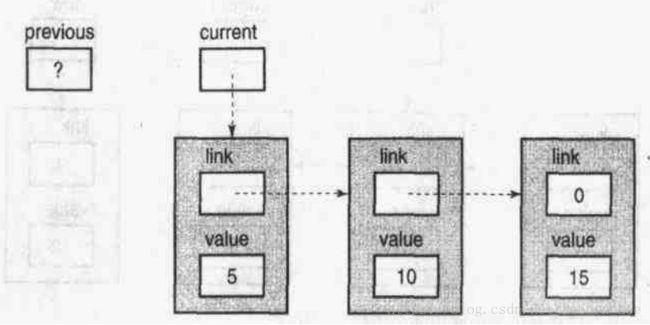
这张图没有显示root变量,因为函数不能访问它。它的值的一份拷贝作为形参current传递给函数,但函数不能访问root。现在current->value是5,小于12,所以循环再次执行。
当我们回到循环的顶部时,current和previous指针都向前移动了一个节点。
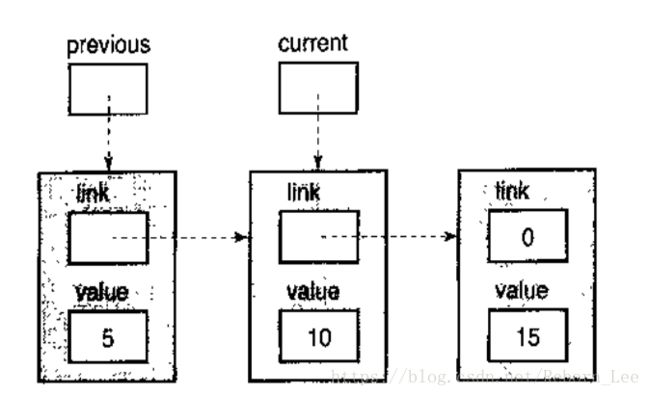
现在current->value的值是10,小于12,因此循环体继续执行,结果如下:
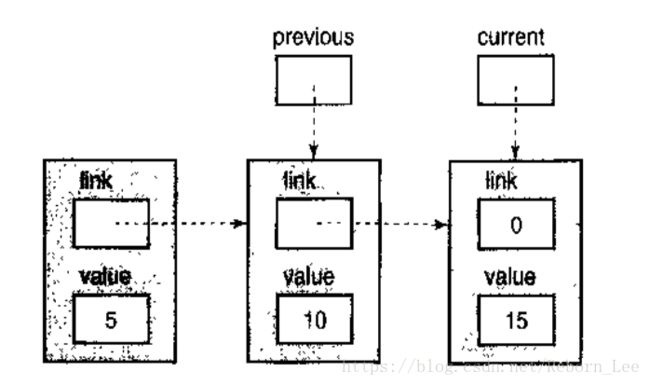
现在current->value的值是15大于12,所以退出循环。
此时,重要的是previous指针,因为它指向我们必须加以修改以插入新值的那个节点。但首先,我们必须得到一个新节点,用于容纳新值。下面这张图显示了新值被赋值到新节点之后链表的状态。

把这个新节点链接到链表中需要两个步骤。
首先,new->link = current;
也就是使新节点指向将称为链表下一个节点的节点,也就是我们找到的第一个值大于12的那个节点。在这个步骤之后,链表的内容为:

第二个步骤是让previous指针所指向的节点修改为指向这个新节点。下面这个语句执行这个任务:
previous->link = new;
这个步骤之后,链表的状态如下:
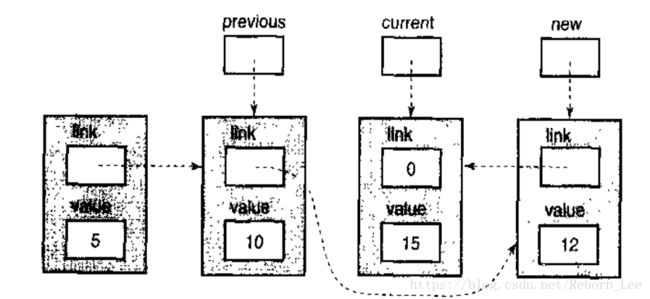
然后函数返回,链表最终的样子如下:

从根节点开始,随各个节点的link字段逐个访问链表,我们可以发现这个新节点已被正确地插入链表中。
最后,不得不提的是现实是否就是这么如意?
可以思考一下,如果试图把20插入链表,也就是new_value = 20,这个程序还能正常工作吗?
这里把循环提出来:
while( current->value < new_value )
{
previous = current; //始终保存当前节点之前的那个节点
current = current->link; //当前节点移动到下一个节点
}
你会发现,while循环会越过链表的尾部,并对一个NULL指针执行间接访问操作。这是不合法的。
为了解决这个问题, 我们必须对current的值进行测试,在执行current->value之前确保它不是一个NULL指针:
将while语句的中条件换成如下:
while( current != NULL & current->value < new_value )
{
...
}
就解决了上述问题。
最后呢?提出下一篇博文要讲的内容,就是试试把3这个值插入链表,看看会发生什么?下篇博文见!
下篇博文地址: 【 C 】在单链表中插入一个新节点的尝试(二)