linux命令大全(完善中)
bash作为大多数的linux系统的默认字符解析器,所以必须了解bash的优势
1.默认保存历史命令(可以用上下键翻看)
2.命令输入前几位可用tab键补全
3.强大的批量处理脚本
4.实用的环境变量
一条完整命令的格式
命令 字符 【命令参数】 【操作对象】
命令的参数可选用长格式(完整的选项名称)也可选用短格式(单个字母的缩写),分别用“--”;“-”做前缀。
长格式 如 man --help
短格式 如 man -h
linux的第一个命令
man
在遇到不知道如何使用的命令的时候就可以用到man 帮助命令,来帮助我快速了解命令的用法很有帮助。
echo 终端回显
命令的格式为 echo 字符串 |变量
date 命令用于显示、设置系统的时间或者日期
格式为 dete 【选项】【+指定的格式】
参数 作用
%t 跳格【TAB键】
%H 小时(00-23)
%I 小时(01-12)
%M 分钟(00-60)
%S 秒(00-60)
%X 相当于%H:%M:%S
%Z 显示时区
%p 显示本地AM或PM
%A 星期几(Sunday-Saturday)
%a 星期几(sun-sat)
%B 完整月份
%b 缩写月份
%d 日(01-31)
%j 一年之中的第几天(01--365)
%m /月份(01-12)
%Y 完整的年份
reboot 命令用于重启系统(仅root用户可以使用)
格式为 reboot
wget 命令用于命令下载网络文件
格式为 wget [参数] 下载地址
参数 作用
-b 后台下载模式
-O 下载到指定目录
-t 最大尝试次数
-c 断点续传
-p 下载页面内所有资源,包括图片,视屏等等。
-r 递归下载
elinks 用于实现一个纯文本界面 的浏览器
格式为 elinks [参数] 网址
ifconfig 用于获取网卡配置与网络状态等信息
格式为 ifconfig [网络设备] {参数}
命令参数
up 启动指定网络设备/网卡。
down 关闭指定网络设备/网卡。该参数可以有效地阻止通过指定接口的IP信息流,如果想永久地关闭一个接口,我们还需要从核心路由表中将该接口的路由信息全部删除。
arp 设置指定网卡是否支持ARP协议。
-promisc 设置是否支持网卡的promiscuous模式,如果选择此参数,网卡将接收网络中发给它所有的数据包
-allmulti 设置是否支持多播模式,如果选择此参数,网卡将接收网络中所有的多播数据包
-a 显示全部接口信息
-s 显示摘要信息(类似于 netstat -i)
add 给指定网卡配置IPv6地址
del 删除指定网卡的IPv6地址
<硬件地址> 配置网卡最大的传输单元
mtu<字节数> 设置网卡的最大传输单元 (bytes)
netmask<子网掩码> 设置网卡的子网掩码。掩码可以是有前缀0x的32位十六进制数,也可以是用点分开的4个十进制数。如果不打算将网络分成子网,可以不管这一选项;如果要使用子网,那么请记住,网络中每一个系统必须有相同子网掩码。
tunel 建立隧道
dstaddr 设定一个远端地址,建立点对点通信
-broadcast<地址> 为指定网卡设置广播协议
-pointtopoint<地址> 为网卡设置点对点通讯协议
multicast 为网卡设置组播标志
address 为网卡设置IPv4地址
txqueuelen<长度> 为网卡设置传输列队的长度
uname 命令用于查看系统内核版本等信息
格式为 uname -参数
up 启动指定网络设备/网卡。
down 关闭指定网络设备/网卡。该参数可以有效地阻止通过指定接口的IP信息流,如果想永久地关闭一个接口,我们还需要从核心路由表中将该接口的路由信息全部删除。
arp 设置指定网卡是否支持ARP协议。
-promisc 设置是否支持网卡的promiscuous模式,如果选择此参数,网卡将接收网络中发给它所有的数据包
-allmulti 设置是否支持多播模式,如果选择此参数,网卡将接收网络中所有的多播数据包
-a 显示全部接口信息
-s 显示摘要信息(类似于 netstat -i)
add 给指定网卡配置IPv6地址
del 删除指定网卡的IPv6地址
<硬件地址> 配置网卡最大的传输单元
mtu<字节数> 设置网卡的最大传输单元 (bytes)
netmask<子网掩码> 设置网卡的子网掩码。掩码可以是有前缀0x的32位十六进制数,也可以是用点分开的4个十进制数。如果不打算将网络分成子网,可以不管这一选项;如果要使用子网,那么请记住,网络中每一个系统必须有相同子网掩码。
tunel 建立隧道
dstaddr 设定一个远端地址,建立点对点通信
-broadcast<地址> 为指定网卡设置广播协议
-pointtopoint<地址> 为网卡设置点对点通讯协议
multicast 为网卡设置组播标志
address 为网卡设置IPv4地址
txqueuelen<长度> 为网卡设置传输列队的长度
uptime命令用于查看系统的负载情况
格式为 uptime [选项]
-V:显示指令的版本信息free 命令用于显示当前系统内存的使用情况
格式为 free 【参数】
命令参数:
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-g 以GB为单位显示内存使用情况。
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
who 命令用于查看当前登入主机的用户情况
格式为 who [选项][参数]
选项
-H或--heading:显示各栏位的标题信息列;
-i或-u或--idle:显示闲置时间,若该用户在前一分钟之内有进行任何动作,将标示成"."号,如果该用户已超过24小时没有任何动作,则标示出"old"字符串;
-m:此参数的效果和指定"am i"字符串相同;
-q或--count:只显示登入系统的帐号名称和总人数;
-s:此参数将忽略不予处理,仅负责解决who指令其他版本的兼容性问题;
-w或-T或--mesg或--message或--writable:显示用户的信息状态栏;
--help:在线帮助;
--version:显示版本信息。
参数
指定查询文件
last 用于查看所有系统的登入记录。
格式为 last 【选项】 [参数]
选项
-a:把从何处登入系统的主机名称或ip地址,显示在最后一行;
-d:将IP地址转换成主机名称;
-f <记录文件>:指定记录文件。
-n <显示列数>或-<显示列数>:设置列出名单的显示列数;
-R:不显示登入系统的主机名称或IP地址;
-x:显示系统关机,重新开机,以及执行等级的改变等信息。参数
- 用户名:显示用户登录列表;
- 终端:显示从指定终端的登录列表。
history 用于显示历史执行过的命令
history(选项)(参数)
选项
-c:清空当前历史命令;
-a:将历史命令缓冲区中命令写入历史命令文件中;
-r:将历史命令文件中的命令读入当前历史命令缓冲区;
-w:将当前历史命令缓冲区命令写入历史命令文件中。参数
n:打印最近的n条历史命令。
sosreport 用于收集系统配置并诊断信息后输出结论文档。
命令使用前需要安装 sos
yum -y install sos
运行命令sosreport
这条命令正常情况下会在几分钟里完成。根据本地配置,在某些情况下,某些选项可能需要更长的时间才能完成。一旦完成,sosreport将在/ tmp目录目录中生成一个压缩文件。不同版本使用不同的压缩方案(** gz,bz2,或xz**)
注意:sosreport需要root权限才能运行
pwd 用于显示当前的工作目录 pwd -p 显示真实路径
cd 命令用于切换工作路径 cd [工作目录名称]
参数 作用
- 切换到上一次工作的目录
~ 切换到“家目录”
~username 切换到其他用户的家目录
.. 切换到上一级目录
ls 命令用于查看目录中有哪些文件
格式为 :ls [选项] 【文件】
-a, –all 列出目录下的所有文件,包括以 . 开头的隐含文件
-A 同-a,但不列出“.”(表示当前目录)和“..”(表示当前目录的父目录)。
-c 配合 -lt:根据 ctime 排序及显示 ctime (文件状态最后更改的时间)配合 -l:显示 ctime 但根据名称排序否则:根据 ctime 排序
-C 每栏由上至下列出项目
–color[=WHEN] 控制是否使用色彩分辨文件。WHEN 可以是'never'、'always'或'auto'其中之一
-d, –directory 将目录象文件一样显示,而不是显示其下的文件。
-D, –dired 产生适合 Emacs 的 dired 模式使用的结果
-f 对输出的文件不进行排序,-aU 选项生效,-lst 选项失效
-g 类似 -l,但不列出所有者
-G, –no-group 不列出任何有关组的信息
-h, –human-readable 以容易理解的格式列出文件大小 (例如 1K 234M 2G)
–si 类似 -h,但文件大小取 1000 的次方而不是 1024
-H, –dereference-command-line 使用命令列中的符号链接指示的真正目的地
–indicator-style=方式 指定在每个项目名称后加上指示符号<方式>:none (默认),classify (-F),file-type (-p)
-i, –inode 印出每个文件的 inode 号
-I, –ignore=样式 不印出任何符合 shell 万用字符<样式>的项目
-k 即 –block-size=1K,以 k 字节的形式表示文件的大小。
-l 除了文件名之外,还将文件的权限、所有者、文件大小等信息详细列出来。
-L, –dereference 当显示符号链接的文件信息时,显示符号链接所指示的对象而并非符号链接本身的信息
-m 所有项目以逗号分隔,并填满整行行宽
-o 类似 -l,显示文件的除组信息外的详细信息。
-r, –reverse 依相反次序排列
-R, –recursive 同时列出所有子目录层
-s, –size 以块大小为单位列出所有文件的大小
-S 根据文件大小排序
–sort=WORD 以下是可选用的 WORD 和它们代表的相应选项:
extension -X status -c
none -U time -t
size -S atime -u
time -t access -u
version -v use -u
-t 以文件修改时间排序
-u 配合 -lt:显示访问时间而且依访问时间排序
配合 -l:显示访问时间但根据名称排序
否则:根据访问时间排序
-U 不进行排序;依文件系统原有的次序列出项目
-v 根据版本进行排序
-w, –width=COLS 自行指定屏幕宽度而不使用目前的数值
-x 逐行列出项目而不是逐栏列出
-X 根据扩展名排序
-1 每行只列出一个文件
–help 显示此帮助信息并离开
–version 显示版本信息并离开
常用范例:
例一:列出/home/peidachang文件夹下的所有文件和目录的详细资料
命令:ls -l -R /home/peidachang
在使用 ls 命令时要注意命令的格式:在命令提示符后,首先是命令的关键字,接下来是命令参数,在命令参数之前要有一短横线“-”,所有的命令参数都有特定的作用,自己可以根据需要选用一个或者多个参数,在命令参数的后面是命令的操作对象。在以上这条命令“ ls -l -R /home/peidachang”中,“ls” 是命令关键字,“-l -R”是参数,“ /home/peidachang”是命令的操作对象。在这条命令中,使用到了两个参数,分别为“l”和“R”,当然,你也可以把他们放在一起使用,如下所示:
命令:ls -lR /home/peidachang
这种形式和上面的命令形式执行的结果是完全一样的。另外,如果命令的操作对象位于当前目录中,可以直接对操作对象进行操作;如果不在当前目录则需要给出操作对象的完整路径,例如上面的例子中,我的当前文件夹是peidachang文件夹,我想对home文件夹下的peidachang文件进行操作,我可以直接输入 ls -lR peidachang,也可以用 ls -lR /home/peidachang。
例二:列出当前目录中所有以“t”开头的目录的详细内容,可以使用如下命令:
命令:ls -l t*
可以查看当前目录下文件名以“t”开头的所有文件的信息。其实,在命令格式中,方括号内的内容都是可以省略的,对于命令ls而言,如果省略命令参数和操作对象,直接输入“ ls ”,则将会列出当前工作目录的内容清单。
例三:只列出文件下的子目录
命令:ls -F /opt/soft |grep /$
列出 /opt/soft 文件下面的子目录
输出:
[root@localhost opt]# ls -F /opt/soft |grep /$
jdk1.6.0_16/
subversion-1.6.1/
tomcat6.0.32/
命令:ls -l /opt/soft | grep "^d"
列出 /opt/soft 文件下面的子目录详细情况
输出:
[root@localhost opt]# ls -l /opt/soft | grep "^d"
drwxr-xr-x 10 root root 4096 09-17 18:17 jdk1.6.0_16
drwxr-xr-x 16 1016 1016 4096 10-11 03:25 subversion-1.6.1
drwxr-xr-x 9 root root 4096 2011-11-01 tomcat6.0.32
例四:列出目前工作目录下所有名称是s 开头的档案,愈新的排愈后面,可以使用如下命令:
命令:ls -ltr s*
输出:
[root@localhost opt]# ls -ltr s*
src:
总计 0
script:
总计 0
soft:
总计 350644
drwxr-xr-x 9 root root 4096 2011-11-01 tomcat6.0.32
-rwxr-xr-x 1 root root 81871260 09-17 18:15 jdk-6u16-linux-x64.bin
drwxr-xr-x 10 root root 4096 09-17 18:17 jdk1.6.0_16
-rw-r--r-- 1 root root 205831281 09-17 18:33 apache-tomcat-6.0.32.tar.gz
-rw-r--r-- 1 root root 5457684 09-21 00:23 tomcat6.0.32.tar.gz
-rw-r--r-- 1 root root 4726179 10-10 11:08 subversion-deps-1.6.1.tar.gz
-rw-r--r-- 1 root root 7501026 10-10 11:08 subversion-1.6.1.tar.gz
drwxr-xr-x 16 1016 1016 4096 10-11 03:25 subversion-1.6.1
例五:列出目前工作目录下所有档案及目录;目录于名称后加"/", 可执行档于名称后加"*"
命令:ls -AF
输出:
[root@localhost opt]# ls -AF
log/ script/ soft/ src/ svndata/ web/
例六:计算当前目录下的文件数和目录数
命令:
ls -l * |grep "^-"|wc -l ---文件个数
ls -l * |grep "^d"|wc -l ---目录个数
例七: 在ls中列出文件的绝对路径
命令:ls | sed "s:^:`pwd`/:"
输出:
[root@localhost opt]# ls | sed "s:^:`pwd`/:"
/opt/log
/opt/script
/opt/soft
/opt/src
/opt/svndata
/opt/web
例九:列出当前目录下的所有文件(包括隐藏文件)的绝对路径, 对目录不做递归
命令:find $PWD -maxdepth 1 | xargs ls -ld
输出:
[root@localhost opt]# find $PWD -maxdepth 1 | xargs ls -ld
drwxr-xr-x 8 root root 4096 10-11 03:43 /opt
drwxr-xr-x 2 root root 4096 2012-03-08 /opt/log
drwxr-xr-x 2 root root 4096 2012-03-08 /opt/script
drwxr-xr-x 5 root root 4096 10-11 03:21 /opt/soft
drwxr-xr-x 2 root root 4096 2012-03-08 /opt/src
drwxr-xr-x 4 root root 4096 10-11 05:22 /opt/svndata
drwxr-xr-x 4 root root 4096 10-09 00:45 /opt/web
例十:递归列出当前目录下的所有文件(包括隐藏文件)的绝对路径
命令: find $PWD | xargs ls -ld
例十一:指定文件时间输出格式
命令:
ls -tl --time-style=full-iso
输出:
[root@localhost soft]# ls -tl --time-style=full-iso
总计 350644
drwxr-xr-x 16 1016 1016 4096 2012-10-11 03:25:58.000000000 +0800 subversion-1.6.1
ls -ctl --time-style=long-iso
输出:
[root@localhost soft]# ls -ctl --time-style=long-iso
总计 350644
drwxr-xr-x 16 1016 1016 4096 2012-10-11 03:25 subversion-1.6.1
扩展:
1. 显示彩色目录列表
打开/etc/bashrc, 加入如下一行:
alias ls="ls --color"
下次启动bash时就可以像在Slackware里那样显示彩色的目录列表了, 其中颜色的含义如下:
1. 蓝色-->目录
2. 绿色-->可执行文件
3. 红色-->压缩文件
4. 浅蓝色-->链接文件
5. 灰色-->其他文件
cat 命令用于查看纯文本文件(较短的)
cat主要有三大功能:
1.一次显示整个文件:cat filename
2.从键盘创建一个文件:cat > filename 只能创建新文件,不能编辑已有文件.
3.将几个文件合并为一个文件:cat file1 file2 > file
格式 cat [选项]【文件】
命令参数:
-A, --show-all 等价于 -vET
-b, --number-nonblank 对非空输出行编号
-e 等价于 -vE
-E, --show-ends 在每行结束处显示 $
-n, --number 对输出的所有行编号,由1开始对所有输出的行数编号
-s, --squeeze-blank 有连续两行以上的空白行,就代换为一行的空白行
-t 与 -vT 等价
-T, --show-tabs 将跳格字符显示为 ^I
-u (被忽略)
-v, --show-nonprinting 使用 ^ 和 M- 引用,除了 LFD 和 TAB 之外
more命令 用于查看纯文本文件(较长的)
more命令和cat的功能一样都是查看文件里的内容,但有所不同的是more可以按页来查看文件的内容,还支持直接跳转行等功能
命令参数:
+n 从笫n行开始显示
-n 定义屏幕大小为n行
+/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示
-c 从顶部清屏,然后显示
-d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
-l 忽略Ctrl+l(换页)字符
-p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似
-s 把连续的多个空行显示为一行
-u 把文件内容中的下画线去掉
4.常用操作命令:
Enter 向下n行,需要定义。默认为1行
Ctrl+F 向下滚动一屏
空格键 向下滚动一屏
Ctrl+B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
V 调用vi编辑器
!命令 调用Shell,并执行命令
q 退出more
head 命令用于查看纯文本文档的前N行,
格式【选项】【文件】
命令参数:
-q 隐藏文件名
-v 显示文件名
-c<字节> 显示字节数
-n<行数> 显示的行数
tail 命令用于查看纯文本文档的后N行
格式为 tail [选项]【文件】
命令参数:
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示行数
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束.
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
od 命令用于查看特殊格式的文件。
格式为 od 【选项】【文件】
参数:
- -a 此参数的效果和同时指定"-ta"参数相同。
- -A<字码基数> 选择要以何种基数计算字码。
- -b 此参数的效果和同时指定"-toC"参数相同。
- -c 此参数的效果和同时指定"-tC"参数相同。
- -d 此参数的效果和同时指定"-tu2"参数相同。
- -f 此参数的效果和同时指定"-tfF"参数相同。
- -h 此参数的效果和同时指定"-tx2"参数相同。
- -i 此参数的效果和同时指定"-td2"参数相同。
- -j<字符数目>或--skip-bytes=<字符数目> 略过设置的字符数目。
- -l 此参数的效果和同时指定"-td4"参数相同。
- -N<字符数目>或--read-bytes=<字符数目> 到设置的字符数目为止。
- -o 此参数的效果和同时指定"-to2"参数相同。
- -s<字符串字符数>或--strings=<字符串字符数> 只显示符合指定的字符数目的字符串。
- -t<输出格式>或--format=<输出格式> 设置输出格式。
- -v或--output-duplicates 输出时不省略重复的数据。
- -w<每列字符数>或--width=<每列字符数> 设置每列的最大字符数。
- -x 此参数的效果和同时指定"-h"参数相同。
- --help 在线帮助。
- --version 显示版本信息。
实例
创建 tmp 文件:
$ echo abcdef g > tmp
$ cat tmp
abcdef g使用 od 命令:
$ od -b tmp
0000000 141 142 143 144 145 146 040 147 012
0000011tr 命令用于转换文本文件的字符
格式 tr 【原始字符】【目标字符】
- -c,--complement:反选设定字符。也就是符合SET1的部份不做处理,不符合的剩余部份才进行转换
- -d, - delete:删除指令字符
- -s, - squeeze-repeats:缩减连续重复的字符成指定的单个字符
- -t, - struncate-set1:削减SET1指定范围,使之与SET2设定长度相等
- --help:显示程序用法信息
- --version:显示程序本身的版本信息
wc 命令用于统计指定文本的行数,字数,字节数
格式为 wc 【参数】 文本
命令参数:
-c 统计字节数。
-l 统计行数。
-m 统计字符数。这个标志不能与 -c 标志一起使用。
-w 统计字数。一个字被定义为由空白、跳格或换行字符分隔的字符串。
-L 打印最长行的长度。
-help 显示帮助信息
--version 显示版本信息
cut 命令用于通过列来提取文本字符
格式为 cut 【参数】 文本
-b:仅显示行中指定直接范围的内容;
-c:仅显示行中指定范围的字符;
-d:指定字段的分隔符,默认的字段分隔符为“TAB”;
-f:显示指定字段的内容;
-n:与“-b”选项连用,不分割多字节字符;
--complement:补足被选择的字节、字符或字段;
--out-delimiter=<字段分隔符>:指定输出内容是的字段分割符;
--help:显示指令的帮助信息;
--version:显示指令的版本信息。diff 命令用于比较多个文本文件的差异
格式为 diff 【参数】 文件
命令参数:
- 指定要显示多少行的文本。此参数必须与-c或-u参数一并使用。
-a或--text diff预设只会逐行比较文本文件。
-b或--ignore-space-change 不检查空格字符的不同。
-B或--ignore-blank-lines 不检查空白行。
-c 显示全部内文,并标出不同之处。
-C或--context 与执行"-c-"指令相同。
-d或--minimal 使用不同的演算法,以较小的单位来做比较。
-D或ifdef 此参数的输出格式可用于前置处理器巨集。
-e或--ed 此参数的输出格式可用于ed的script文件。
-f或-forward-ed 输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处。
-H或--speed-large-files 比较大文件时,可加快速度。
-l或--ignore-matching-lines 若两个文件在某几行有所不同,而这几行同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异。
-i或--ignore-case 不检查大小写的不同。
-l或--paginate 将结果交由pr程序来分页。
-n或--rcs 将比较结果以RCS的格式来显示。
-N或--new-file 在比较目录时,若文件A仅出现在某个目录中,预设会显示:Only in目录:文件A若使用-N参数,则diff会将文件A与一个空白的文件比较。
-p 若比较的文件为C语言的程序码文件时,显示差异所在的函数名称。
-P或--unidirectional-new-file 与-N类似,但只有当第二个目录包含了一个第一个目录所没有的文件时,才会将这个文件与空白的文件做比较。
-q或--brief 仅显示有无差异,不显示详细的信息。
-r或--recursive 比较子目录中的文件。
-s或--report-identical-files 若没有发现任何差异,仍然显示信息。
-S或--starting-file 在比较目录时,从指定的文件开始比较。
-t或--expand-tabs 在输出时,将tab字符展开。
-T或--initial-tab 在每行前面加上tab字符以便对齐。
-u,-U或--unified= 以合并的方式来显示文件内容的不同。
文件目录管理命令
touch 命令用于创建空白文件与修改文件时间
格式为 touch 【选项】 文件名
命令参数:
-a 或--time=atime或--time=access或--time=use 只更改存取时间。
-c 或--no-create 不建立任何文档。
-d 使用指定的日期时间,而非现在的时间。
-f 此参数将忽略不予处理,仅负责解决BSD版本touch指令的兼容性问题。
-m 或--time=mtime或--time=modify 只更改变动时间。
-r 把指定文档或目录的日期时间,统统设成和参考文档或目录的日期时间相同。
-t 使用指定的日期时间,而非现在的时间。
mkdir 用于创建空白的文件夹
格式为 mkdir 【选项】目录名
命令参数:
-m, --mode=模式,设定权限<模式> (类似 chmod),而不是 rwxrwxrwx 减 umask
-p, --parents 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不存在的目录,即一次可以建立多个目录;
-v, --verbose 每次创建新目录都显示信息
--help 显示此帮助信息并退出
--version 输出版本信息并退出
cp 命令用于复制文件或目录
格式为 cp 【选项】 源文件 目标文件
命令参数:
-a, --archive 等于-dR --preserve=all
--backup[=CONTROL 为每个已存在的目标文件创建备份
-b 类似--backup 但不接受参数
--copy-contents 在递归处理是复制特殊文件内容
-d 等于--no-dereference --preserve=links
-f, --force 如果目标文件无法打开则将其移除并重试(当 -n 选项
存在时则不需再选此项)
-i, --interactive 覆盖前询问(使前面的 -n 选项失效)
-H 跟随源文件中的命令行符号链接
-l, --link 链接文件而不复制
-L, --dereference 总是跟随符号链接
-n, --no-clobber 不要覆盖已存在的文件(使前面的 -i 选项失效)
-P, --no-dereference 不跟随源文件中的符号链接
-p 等于--preserve=模式,所有权,时间戳
--preserve[=属性列表 保持指定的属性(默认:模式,所有权,时间戳),如果
可能保持附加属性:环境、链接、xattr 等
-R, -r, --recursive 复制目录及目录内的所有项目
mv命令用于移动文件或者改名
格式为 mv 【选项】 文件名 【目标路径|目标文件名】
命令参数:
-b :若需覆盖文件,则覆盖前先行备份。
-f :force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖;
-i :若目标文件 (destination) 已经存在时,就会询问是否覆盖!
-u :若目标文件已经存在,且 source 比较新,才会更新(update)
rm 命令用于删除文件或目录
格式为 rm 【选项】 文件
命令参数:
-f, --force 忽略不存在的文件,从不给出提示。
-i, --interactive 进行交互式删除
-r, -R, --recursive 指示rm将参数中列出的全部目录和子目录均递归地删除。
-v, --verbose 详细显示进行的步骤
--help 显示此帮助信息并退出
--version 输出版本信息并退出
dd命令应用于指定大小的拷贝的文件或指定转换文件
格式 dd 【参数】
- if=文件名:输入文件名,缺省为标准输入。即指定源文件。< if=input file >
- of=文件名:输出文件名,缺省为标准输出。即指定目的文件。< of=output file >
- ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。
obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。
bs=bytes:同时设置读入/输出的块大小为bytes个字节。 - cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
- skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
- seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
注意:通常只用当输出文件是磁盘或磁带时才有效,即备份到磁盘或磁带时才有效。 - count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
- conv=conversion:用指定的参数转换文件。
- ascii:转换ebcdic为ascii
- ebcdic:转换ascii为ebcdic
- ibm:转换ascii为alternate ebcdic
- block:把每一行转换为长度为cbs,不足部分用空格填充
- unblock:使每一行的长度都为cbs,不足部分用空格填充
- lcase:把大写字符转换为小写字符
- ucase:把小写字符转换为大写字符
- swab:交换输入的每对字节
- noerror:出错时不停止
- notrunc:不截短输出文件
- sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
应用实例
1.将本地的/dev/hdb整盘备份到/dev/hdd
dd if=/dev/hdb of=/dev/hdd
2.将/dev/hdb全盘数据备份到指定路径的image文件
dd if=/dev/hdb of=/root/image
3.将备份文件恢复到指定盘
dd if=/root/image of=/dev/hdb
4.备份/dev/hdb全盘数据,并利用gzip工具进行压缩,保存到指定路径
dd if=/dev/hdb | gzip > /root/image.gz
5.将压缩的备份文件恢复到指定盘
gzip -dc /root/image.gz | dd of=/dev/hdb
6.备份磁盘开始的512个字节大小的MBR信息到指定文件
dd if=/dev/hda of=/root/image count=1 bs=512
count=1指仅拷贝一个块;bs=512指块大小为512个字节。
恢复:
dd if=/root/image of=/dev/hda
7.备份软盘
dd if=/dev/fd0 of=disk.img count=1 bs=1440k
(即块大小为1.44M)
8.拷贝内存内容到硬盘
dd if=/dev/mem of=/root/mem.bin bs=1024
(指定块大小为1k)
9.拷贝光盘内容到指定文件夹,并保存为cd.iso文件
dd if=/dev/cdrom(hdc) of=/root/cd.iso
10.增加swap分区文件大小
第一步:创建一个大小为256M的文件:
dd if=/dev/zero of=/swapfile bs=1024 count=262144
第二步:把这个文件变成swap文件:
mkswap /swapfile
第三步:启用这个swap文件:
swapon /swapfile
第四步:编辑/etc/fstab文件,使在每次开机时自动加载swap文件:
/swapfile swap swap defaults 0 0
11.销毁磁盘数据
dd if=/dev/urandom of=/dev/hda1
注意:利用随机的数据填充硬盘,在某些必要的场合可以用来销毁数据。
12.测试硬盘的读写速度
dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file
dd if=/root/1Gb.file bs=64k | dd of=/dev/null
通过以上两个命令输出的命令执行时间,可以计算出硬盘的读、写速度。
13.确定硬盘的最佳块大小:
dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file
dd if=/dev/zero bs=2048 count=500000 of=/root/1Gb.file
dd if=/dev/zero bs=4096 count=250000 of=/root/1Gb.file
dd if=/dev/zero bs=8192 count=125000 of=/root/1Gb.file
通过比较以上命令输出中所显示的命令执行时间,即可确定系统最佳的块大小。
14.修复硬盘
dd if=/dev/sda of=/dev/sda
用户与组管理命令
useradd 命令用于创建新用户
格式为 useradd 【选项】 用户名
-c<备注>:加上备注文字。备注文字会保存在passwd的备注栏位中;
-d<登入目录>:指定用户登入时的启始目录;
-D:变更预设值;
-e<有效期限>:指定帐号的有效期限;
-f<缓冲天数>:指定在密码过期后多少天即关闭该帐号;
-g<群组>:指定用户所属的群组;
-G<群组>:指定用户所属的附加群组;
-m:自动建立用户的登入目录;
-M:不要自动建立用户的登入目录;
-n:取消建立以用户名称为名的群组;
-r:建立系统帐号;
-s:指定用户登入后所使用的shell;
-u:指定用户id。 passwd命令用于修改用户的密码
格式为 passwd 【选项】 用户名
-d:删除密码,仅有系统管理者才能使用;
-f:强制执行;
-k:设置只有在密码过期失效后,方能更新;
-l:锁住密码;
-s:列出密码的相关信息,仅有系统管理者才能使用;
-u:解开已上锁的帐号。userdel 命令用于删除用户所有表格
格式为 userdel 【选项】用户
-f:强制删除用户,即使用户当前已登录;
-r:删除用户的同时,删除与用户相关的所有文件。
usermod命令用于修改用户属性
格式为 usermod 【选项】 用户名
-c<备注>:修改用户帐号的备注文字;
-d<登入目录>:修改用户登入时的目录;
-e<有效期限>:修改帐号的有效期限;
-f<缓冲天数>:修改在密码过期后多少天即关闭该帐号;
-g<群组>:修改用户所属的群组;
-G<群组>;修改用户所属的附加群组;
-l<帐号名称>:修改用户帐号名称;
-L:锁定用户密码,使密码无效;
-s:修改用户登入后所使用的shell;
-u:修改用户ID;
-U:解除密码锁定。 groupadd 命令用于创建群组
格式为 groupadd 【选项】 组名
-g:指定新建工作组的id;
-r:创建系统工作组,系统工作组的组ID小于500;
-K:覆盖配置文件“/ect/login.defs”;
-o:允许添加组ID号不唯一的工作组。打包压缩文件命令
tar 命令用于对文件打包压缩或解压
格式为 tar[必要参数][选择参数][文件]
命令功能:
用来压缩和解压文件。tar本身不具有压缩功能。他是调用压缩功能实现的
命令参数:
必要参数有如下:
-A 新增压缩文件到已存在的压缩
-B 设置区块大小
-c 建立新的压缩文件
-d 记录文件的差别
-r 添加文件到已经压缩的文件
-u 添加改变了和现有的文件到已经存在的压缩文件
-x 从压缩的文件中提取文件
-t 显示压缩文件的内容
-z 支持gzip解压文件
-j 支持bzip2解压文件
-Z 支持compress解压文件
-v 显示操作过程
-l 文件系统边界设置
-k 保留原有文件不覆盖
-m 保留文件不被覆盖
-W 确认压缩文件的正确性
可选参数如下:
-b 设置区块数目
-C 切换到指定目录
-f 指定压缩文件
--help 显示帮助信息
--version 显示版本信息
常见解压/压缩命令
tar
解包:tar xvf FileName.tar
打包:tar cvf FileName.tar DirName
(注:tar是打包,不是压缩!)
.gz
解压1:gunzip FileName.gz
解压2:gzip -d FileName.gz
压缩:gzip FileName
.tar.gz 和 .tgz
解压:tar zxvf FileName.tar.gz
压缩:tar zcvf FileName.tar.gz DirName
.bz2
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
.tar.bz2
解压:tar jxvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
.bz
解压1:bzip2 -d FileName.bz
解压2:bunzip2 FileName.bz
压缩:未知
.tar.bz
解压:tar jxvf FileName.tar.bz
压缩:未知
.Z
解压:uncompress FileName.Z
压缩:compress FileName
.tar.Z
解压:tar Zxvf FileName.tar.Z
压缩:tar Zcvf FileName.tar.Z DirName
.zip
解压:unzip FileName.zip
压缩:zip FileName.zip DirName
.rar
解压:rar x FileName.rar
压缩:rar a FileName.rar DirName
使用实例
实例1:将文件全部打包成tar包
命令:
tar -cvf log.tar log2012.log
tar -zcvf log.tar.gz log2012.log
tar -jcvf log.tar.bz2 log2012.log
输出:
[root@localhost test]# ls -al log2012.log
---xrw-r-- 1 root root 302108 11-13 06:03 log2012.log
[root@localhost test]# tar -cvf log.tar log2012.log
log2012.log
[root@localhost test]# tar -zcvf log.tar.gz log2012.log
log2012.log
[root@localhost test]# tar -jcvf log.tar.bz2 log2012.log
log2012.log
[root@localhost test]# ls -al *.tar*
-rw-r--r-- 1 root root 307200 11-29 17:54 log.tar
-rw-r--r-- 1 root root 1413 11-29 17:55 log.tar.bz2
-rw-r--r-- 1 root root 1413 11-29 17:54 log.tar.gz
说明:
tar -cvf log.tar log2012.log 仅打包,不压缩!
tar -zcvf log.tar.gz log2012.log 打包后,以 gzip 压缩
tar -zcvf log.tar.bz2 log2012.log 打包后,以 bzip2 压缩
在参数 f 之后的文件档名是自己取的,我们习惯上都用 .tar 来作为辨识。 如果加 z 参数,则以 .tar.gz 或 .tgz 来代表 gzip 压缩过的 tar包; 如果加 j 参数,则以 .tar.bz2 来作为tar包名。
实例2:查阅上述 tar包内有哪些文件
命令:tar -ztvf log.tar.gz
输出:
[root@localhost test]# tar -ztvf log.tar.gz
---xrw-r-- root/root 302108 2012-11-13 06:03:25 log2012.log
说明:
由于我们使用 gzip 压缩的log.tar.gz,所以要查阅log.tar.gz包内的文件时,就得要加上 z 这个参数了。
实例3:将tar 包解压缩
命令:tar -zxvf /opt/soft/test/log.tar.gz
输出:
[root@localhost test3]# ll
总计 0[root@localhost test3]# tar -zxvf /opt/soft/test/log.tar.gz
log2012.log
[root@localhost test3]# ls
log2012.log
[root@localhost test3]#
说明:
在预设的情况下,我们可以将压缩档在任何地方解开的
实例4:只将 /tar 内的 部分文件解压出来
命令:tar -zxvf /opt/soft/test/log30.tar.gz log2013.log
输出:
[root@localhost test]# tar -zcvf log30.tar.gz log2012.log log2013.log
log2012.log
log2013.log
[root@localhost test]# ls -al log30.tar.gz
-rw-r--r-- 1 root root 1512 11-30 08:19 log30.tar.gz
[root@localhost test]# tar -zxvf log30.tar.gz log2013.log
log2013.log
[root@localhost test]# ll
-rw-r--r-- 1 root root 1512 11-30 08:19 log30.tar.gz
[root@localhost test]# cd test3
[root@localhost test3]# tar -zxvf /opt/soft/test/log30.tar.gz log2013.log
log2013.log
[root@localhost test3]# ll
总计 4
-rw-r--r-- 1 root root 61 11-13 06:03 log2013.log
[root@localhost test3]#
说明:
我可以透过 tar -ztvf 来查阅 tar 包内的文件名称,如果单只要一个文件,就可以透过这个方式来解压部分文件!
实例5:文件备份下来,并且保存其权限
命令:tar -zcvpf log31.tar.gz log2014.log log2015.log log2016.log
输出:
[root@localhost test]# ll
总计 0
-rw-r--r-- 1 root root 0 11-13 06:03 log2014.log
-rw-r--r-- 1 root root 0 11-13 06:06 log2015.log
-rw-r--r-- 1 root root 0 11-16 14:41 log2016.log
[root@localhost test]# tar -zcvpf log31.tar.gz log2014.log log2015.log log2016.log
log2014.log
log2015.log
log2016.log
[root@localhost test]# cd test6
[root@localhost test6]# ll
[root@localhost test6]# tar -zxvpf /opt/soft/test/log31.tar.gz
log2014.log
log2015.log
log2016.log
[root@localhost test6]# ll
总计 0
-rw-r--r-- 1 root root 0 11-13 06:03 log2014.log
-rw-r--r-- 1 root root 0 11-13 06:06 log2015.log
-rw-r--r-- 1 root root 0 11-16 14:41 log2016.log
[root@localhost test6]#
说明:
这个 -p 的属性是很重要的,尤其是当您要保留原本文件的属性时
实例6:在 文件夹当中,比某个日期新的文件才备份
命令:tar -N "2012/11/13" -zcvf log17.tar.gz test
输出:
[root@localhost soft]# tar -N "2012/11/13" -zcvf log17.tar.gz test
tar: Treating date `2012/11/13' as 2012-11-13 00:00:00 + 0 nanoseconds
test/test/log31.tar.gz
test/log2014.log
test/linklog.log
test/log2015.log
test/log2013.log
test/log2012.log
test/log2017.log
test/log2016.log
test/log30.tar.gz
test/log.tar
test/log.tar.bz2
test/log.tar.gz
说明:
实例7:备份文件夹内容是排除部分文件
命令:tar --exclude scf/service -zcvf scf.tar.gz scf/*
输出:
[root@localhost test]# tree scf
scf
|-- bin
|-- doc
|-- lib
`-- service
`-- deploy
|-- info
`-- product
7 directories, 0 files
[root@localhost test]# tar --exclude scf/service -zcvf scf.tar.gz scf/*
scf/bin/
scf/doc/
scf/lib/
[root@localhost test]#
文件查询搜索命令
grep命令用于对文本进行搜索‘
命令功能:用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
格式为 grep 【选项】文件
命令参数:
-a --text #不要忽略二进制的数据。
-A<显示行数> --after-context=<显示行数> #除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b --byte-offset #在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> --before-context=<显示行数> #除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count #计算符合样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> #除了显示符合样式的那一行之外,并显示该行之前后的内容。
-d <动作> --directories=<动作> #当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> #指定字符串做为查找文件内容的样式。
-E --extended-regexp #将样式为延伸的普通表示法来使用。
-f<规则文件> --file=<规则文件> #指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F --fixed-regexp #将样式视为固定字符串的列表。
-G --basic-regexp #将样式视为普通的表示法来使用。
-h --no-filename #在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H --with-filename #在显示符合样式的那一行之前,表示该行所属的文件名称。
-i --ignore-case #忽略字符大小写的差别。
-l --file-with-matches #列出文件内容符合指定的样式的文件名称。
-L --files-without-match #列出文件内容不符合指定的样式的文件名称。
-n --line-number #在显示符合样式的那一行之前,标示出该行的列数编号。
-q --quiet或--silent #不显示任何信息。
-r --recursive #此参数的效果和指定“-d recurse”参数相同。
-s --no-messages #不显示错误信息。
-v --revert-match #显示不包含匹配文本的所有行。
-V --version #显示版本信息。
-w --word-regexp #只显示全字符合的列。
-x --line-regexp #只显示全列符合的列。
-y #此参数的效果和指定“-i”参数相同。
规则表达式:
grep的规则表达式:
^ #锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ #锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
. #匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #锚定单词的开始,如:'\
\> #锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} #重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。
使用实例:
实例1:查找指定进程
命令:ps -ef|grep svn
输出:
[root@localhost ~]# ps -ef|grep svn
root 4943 1 0 Dec05 ? 00:00:00 svnserve -d -r /opt/svndata/grape/
root 16867 16838 0 19:53 pts/0 00:00:00 grep svn
[root@localhost ~]#
说明:第一条记录是查找出的进程;第二条结果是grep进程本身,并非真正要找的进程。
实例2:查找指定进程个数
命令:ps -ef|grep svn -c
ps -ef|grep -c svn
输出:
[root@localhost ~]# ps -ef|grep svn -c
2
[root@localhost ~]# ps -ef|grep -c svn
2
[root@localhost ~]#
说明:
实例3:从文件中读取关键词进行搜索
命令:cat test.txt | grep -f test2.txt
输出:
[root@localhost test]# cat test.txt
hnlinux
peida.cnblogs.com
ubuntu
ubuntu linux
redhat
Redhat
linuxmint
[root@localhost test]# cat test2.txt
linux
Redhat
[root@localhost test]# cat test.txt | grep -f test2.txt
hnlinux
ubuntu linux
Redhat
linuxmint
[root@localhost test]#
说明:输出test.txt文件中含有从test2.txt文件中读取出的关键词的内容行
实例3:从文件中读取关键词进行搜索 且显示行号
命令:cat test.txt | grep -nf test2.txt
输出:
[root@localhost test]# cat test.txt
hnlinux
peida.cnblogs.com
ubuntu
ubuntu linux
redhat
Redhat
linuxmint
[root@localhost test]# cat test2.txt
linux
Redhat
[root@localhost test]# cat test.txt | grep -nf test2.txt
1:hnlinux
4:ubuntu linux
6:Redhat
7:linuxmint
[root@localhost test]#
说明:输出test.txt文件中含有从test2.txt文件中读取出的关键词的内容行,并显示每一行的行号
实例5:从文件中查找关键词
命令:grep 'linux' test.txt
输出:
[root@localhost test]# grep 'linux' test.txt
hnlinux
ubuntu linux
linuxmint
[root@localhost test]# grep -n 'linux' test.txt
1:hnlinux
4:ubuntu linux
7:linuxmint
[root@localhost test]#
说明:
实例6:从多个文件中查找关键词
命令:grep 'linux' test.txt test2.txt
输出:
[root@localhost test]# grep -n 'linux' test.txt test2.txt
test.txt:1:hnlinux
test.txt:4:ubuntu linux
test.txt:7:linuxmint
test2.txt:1:linux
[root@localhost test]# grep 'linux' test.txt test2.txt
test.txt:hnlinux
test.txt:ubuntu linux
test.txt:linuxmint
test2.txt:linux
[root@localhost test]#
说明:多文件时,输出查询到的信息内容行时,会把文件的命名在行最前面输出并且加上":"作为标示符
实例7:grep不显示本身进程
命令:ps aux|grep \[s]sh
ps aux | grep ssh | grep -v "grep"
输出:
[root@localhost test]# ps aux|grep ssh
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
root 16901 0.0 0.0 61180 764 pts/0 S+ 20:31 0:00 grep ssh
[root@localhost test]# ps aux|grep \[s]sh]
[root@localhost test]# ps aux|grep \[s]sh
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
[root@localhost test]# ps aux | grep ssh | grep -v "grep"
root 2720 0.0 0.0 62656 1212 ? Ss Nov02 0:00 /usr/sbin/sshd
root 16834 0.0 0.0 88088 3288 ? Ss 19:53 0:00 sshd: root@pts/0
说明:
实例8:找出已u开头的行内容
命令:cat test.txt |grep ^u
输出:
[root@localhost test]# cat test.txt |grep ^u
ubuntu
ubuntu linux
[root@localhost test]#
说明:
实例9:输出非u开头的行内容
命令:cat test.txt |grep ^[^u]
输出:
[root@localhost test]# cat test.txt |grep ^[^u]
hnlinux
peida.cnblogs.com
redhat
Redhat
linuxmint
[root@localhost test]#
说明:
实例10:输出以hat结尾的行内容
命令:cat test.txt |grep hat$
输出:
[root@localhost test]# cat test.txt |grep hat$
redhat
Redhat
[root@localhost test]#
说明:
实例11:
[root@localhost test]# ifconfig eth0|grep "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}"
inet addr:192.168.120.204 Bcast:192.168.120.255 Mask:255.255.255.0
[root@localhost test]# ifconfig eth0|grep -E "([0-9]{1,3}\.){3}[0-9]"
inet addr:192.168.120.204 Bcast:192.168.120.255 Mask:255.255.255.0
实例12:显示包含ed或者at字符的内容行
命令:cat test.txt |grep -E "ed|at"
输出:
[root@localhost test]# cat test.txt |grep -E "peida|com"
peida.cnblogs.com
[root@localhost test]# cat test.txt |grep -E "ed|at"
redhat
Redhat
实例13:显示当前目录下面以.txt 结尾的文件中的所有包含每个字符串至少有7个连续小写字符的字符串的行
命令:grep '[a-z]\{7\}' *.txt
输出:
[root@localhost test]# grep '[a-z]\{7\}' *.txt
test.txt:hnlinux
test.txt:peida.cnblogs.com
test.txt:linuxmint
管道命令符
| 管道命令符的作用也可以用一句话来概括:把前一个命令原本要输出到屏幕的标准正常数据当作是后一个命令的标准输入。
输入输出重定向
文件描述符
在linux shell执行命令时,每个进程都和三个打开的文件相联系,并使用文件描述符来引用这些文件。由于文件描述符不容易记忆,shell同时也给出了相应的文件名:
| 文件 | 文件描述符 |
| 输入文件—标准输入 | 0(缺省是键盘,为0时是文件或者其他命令的输出) |
| 输出文件—标准输出 | 1(缺省是屏幕,为1时是文件) |
| 错误输出文件—标准错误 | 2(缺省是屏幕,为2时是文件) |
.文件重定向:改变程序运行的输入来源和输出地点
输出重定向:
| Command > filename | 把标准输出重定向到一个新文件中 |
| Command >> filename | 把标准输出重定向到一个文件中(追加) |
| Command > filename | 把标准输出重定向到一个文件中 |
| Command > filename 2>&1 | 把标准输出和错误一起重定向到一个文件中 |
| Command 2 > filename | 把标准错误重定向到一个文件中 |
| Command 2 >> filename | 把标准输出重定向到一个文件中(追加) |
| Command >> filename2>&1 | 把标准输出和错误一起重定向到一个文件(追加) |
输入重定向
| Command < filename > filename2 | Command命令以filename文件作为标准输入,以filename2文件作为标准输出 |
| Command < filename | Command命令以filename文件作为标准输入 |
| Command << delimiter | 从标准输入中读入,知道遇到delimiter分界符 |
绑定重定向
| Command >&m | 把标准输出重定向到文件描述符m中 |
| Command < &- | 关闭标准输入 |
| Command 0>&- | 同上 |
命令通配符
shell常见通配符
| 字符 |
含义 |
实例 |
| * |
匹配 0 或多个字符 |
a*b a与b之间可以有任意长度的任意字符, 也可以一个也没有, 如aabcb, axyzb, a012b, ab。 |
| ? |
匹配任意一个字符 |
a?b a与b之间必须也只能有一个字符, 可以是任意字符, 如aab, abb, acb, a0b。 |
| [list] |
匹配 list 中的任意单一字符 |
a[xyz]b a与b之间必须也只能有一个字符, 但只能是 x 或 y 或 z, 如: axb, ayb, azb。 |
| [!list] |
匹配 除list 中的任意单一字符 |
a[!0-9]b a与b之间必须也只能有一个字符, 但不能是阿拉伯数字, 如axb, aab, a-b。 |
| [c1-c2] |
匹配 c1-c2 中的任意单一字符 如:[0-9] [a-z] |
a[0-9]b 0与9之间必须也只能有一个字符 如a0b, a1b... a9b。 |
| {string1,string2,...} |
匹配 sring1 或 string2 (或更多)其一字符串 |
a{abc,xyz,123}b a与b之间只能是abc或xyz或123这三个字符串之一。 |
shell 除了有通配符之外,由shell 负责预先先解析后,将处理结果传给命令行之外,shell还有一系列自己的其他特殊字符。
| 字符 | 说明 |
| IFS | 由 |
| CR | 由 |
| = | 设定变量。 |
| $ | 作变量或运算替换(请不要与 shell prompt 搞混了)。 |
| > | 重导向 stdout。 * |
| < | 重导向 stdin。 * |
| | | 命令管线。 * |
| & | 重导向 file descriptor ,或将命令置于背境执行。 * |
| ( ) | 将其内的命令置于 nested subshell 执行,或用于运算或命令替换。 * |
| { } | 将其内的命令置于 non-named function 中执行,或用在变量替换的界定范围。 |
| ; | 在前一个命令结束时,而忽略其返回值,继续执行下一个命令。 * |
| && | 在前一个命令结束时,若返回值为 true,继续执行下一个命令。 * |
| || | 在前一个命令结束时,若返回值为 false,继续执行下一个命令。 * |
| ! | 执行 history 列表中的命令。* |
shell转义符
有时候,我们想让 通配符,或者元字符 变成普通字符,不需要使用它。那么这里我们就需要用到转义符了。 shell提供转义符有三种
| 字符 | 说明 |
| ‘’(单引号) | 又叫硬转义,其内部所有的shell 元字符、通配符都会被关掉。注意,硬转义中不允许出现’(单引号)。 |
| “”(双引号) | 又叫软转义,其内部只允许出现特定的shell 元字符:$用于参数代换 `用于命令代替 |
| \(反斜杠) | 又叫转义,去除其后紧跟的元字符或通配符的特殊意义。 |
实用的PATH变量
alias命令用于设置命令的别名
格式 alias 别名=命令
unalias命令用于取消命令别名
格式为 unalias 别名
Linux环境变量分类
一、按照生命周期来分,Linux环境变量可以分为两类:
1、永久的:需要用户修改相关的配置文件,变量永久生效。
2、临时的:用户利用export命令,在当前终端下声明环境变量,关闭Shell终端失效。
二、按照作用域来分,Linux环境变量可以分为:
1、系统环境变量:系统环境变量对该系统中所有用户都有效。
2、用户环境变量:顾名思义,这种类型的环境变量只对特定的用户有效。
Linux设置环境变量的方法
一、在/etc/profile文件中添加变量 对所有用户生效(永久的)
用vim在文件/etc/profile文件中增加变量,该变量将会对Linux下所有用户有效,并且是“永久的”。
例如:编辑/etc/profile文件,添加CLASSPATH变量
vim /etc/profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想马上生效还要运行source /etc/profile不然只能在下次重进此用户时生效。
二、在用户目录下的.bash_profile文件中增加变量 【对单一用户生效(永久的)】
用vim ~/.bash_profile文件中增加变量,改变量仅会对当前用户有效,并且是“永久的”。
vim ~/.bash.profile
export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
注:修改文件后要想马上生效还要运行$ source ~/.bash_profile不然只能在下次重进此用户时生效。
三、直接运行export命令定义变量 【只对当前shell(BASH)有效(临时的)】
在shell的命令行下直接使用export 变量名=变量值
定义变量,该变量只在当前的shell(BASH)或其子shell(BASH)下是有效的,shell关闭了,变量也就失效了,再打开新shell时就没有这个变量,需要使用的话还需要重新定义。
Linux环境变量使用
一、Linux中常见的环境变量有:
- PATH:指定命令的搜索路径
PATH声明用法:
PATH=$PAHT:: : :--------:< PATH n >
export PATH
你可以自己加上指定的路径,中间用冒号隔开。环境变量更改后,在用户下次登陆时生效。
可以利用echo $PATH查看当前当前系统PATH路径。
- HOME:指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)。
- HISTSIZE:指保存历史命令记录的条数。
- LOGNAME:指当前用户的登录名。
- HOSTNAME:指主机的名称,许多应用程序如果要用到主机名的话,通常是从这个环境变量中来取得的
- SHELL:指当前用户用的是哪种Shell。
- LANG/LANGUGE:和语言相关的环境变量,使用多种语言的用户可以修改此环境变量。
- MAIL:指当前用户的邮件存放目录。
注意:上述变量的名字并不固定,如HOSTNAME在某些Linux系统中可能设置成HOST
二、Linux也提供了修改和查看环境变量的命令,下面通过几个实例来说明:
- echo 显示某个环境变量值 echo $PATH
- export 设置一个新的环境变量 export HELLO="hello" (可以无引号)
- env 显示所有环境变量
- set 显示本地定义的shell变量
- unset 清除环境变量 unset HELLO
- readonly 设置只读环境变量 readonly HELLO
vim文本编辑器
vim的三种模式:一般模式、编辑模式、命令模式
* 一般模式:当你vim filename 编辑一个文件时,一进入该文件就是一般模式了。在这个模式下,你可以做的操作有,上下移动光标;删除某个字符;删除某行;复制、粘贴一行或者多行。
* 编辑模式:一般模式下,是不可以修改某一个字符的,只能到编辑模式了。从一般模式进入编辑模式,只需你按一个键即可(i,I,a,A,o,O,r,R)。当进入编辑模式时,会在屏幕的最下一行出现“INSERT或REPLACE”的字样。从编辑模式回到一般模式只需要按一下键盘左上方的ESC键即可。
* 命令模式:在一般模式下,输入”:”或者”/”即可进入命令模式。在该模式下,你可以搜索某个字符或者字符串,也可以保存、替换、退出、显示行号等等。
| 一般模式下移动光标 |
| h或向左方向键 |
光标向左移动一个字符 |
| j或者向下方向键 |
光标向下移动一个字符 |
| K或者向上方向键 |
光标向上移动一个字符 |
| l或者向右方向键 |
光标向右移动一个字符 |
| Ctrl + f 或者pageUP键 |
屏幕向前移动一页 |
| Ctrl + b或者pageDOWN键 |
屏幕向后移动一页 |
| Ctrl + d |
屏幕向前移动半页 |
| Ctrl + u |
屏幕向后移动半页 |
| + |
光标移动到非空格符的下一列 |
| - |
光标移动到非空格符的上一列 |
| n空格(n是数字) |
按下数字n然后按空格,则光标向右移动n个字符,如果该行字符数小于n,则光标继续从下行开始向右移动,一直到n |
| 0(数字0)或者Shift+6 |
移动到本行行首 |
| Shift+4 |
即’$’移动到本行行尾 |
| H |
光标移动到当前屏幕的最顶行 |
| M |
光标移动到当前屏幕的中央那一行 |
| L |
光标移动到当前屏幕的最底行 |
| G |
光标移动到文本的最末行 |
| nG(n是数字) |
移动到该文本的第n行 |
| gg |
移动带该文本的首行 |
| n回车(n是数字) |
光标向下移动n行 |
| 一般模式下查找与替换 |
| /word |
向光标之后寻找一个字符串名为word的字符串,当找到第一个word后,按”n”继续搜后一个 |
| ?word |
想光标之前寻找一个字符串名为word的字符串,当找到第一个word后,按”n”继续搜前一个 |
| :n1,n2s/word1/word2/g |
在n1和n2行间查找word1这个字符串并替换为word2,你也可以把”/”换成”#” |
| :1,$s/word1/word2/g |
从第一行到最末行,查找word1并替换成word2 |
| :1,$s/word1/word2/gc |
加上c的作用是,在替换前需要用户确认 |
| 一般模式下删除复制粘贴 |
| x,X |
x为向后删除一个字符,X为向前删除一个字符 |
| nx(n为数字) |
向后删除n个字符 |
| dd |
删除光标所在的那一行 |
| ndd(n为数字) |
删除光标所在的向下n行 |
| d1G |
删除光标所在行到第一行的所有数据 |
| dG |
删除光标所在行到末行的所有数据 |
| yy |
复制光标所在的那行 |
| nyy |
复制从光标所在行起向下n行 |
| p,P |
p复制的数据从光标下一行粘贴,P则从光标上一行粘贴 |
| y1G |
复制光标所在行到第一行的所有数据 |
| yG |
复制光标所在行到末行的所有数据 |
| J |
讲光标所在行与下一行的数据结合成同一行 |
| u |
还原过去的操作 |
| 进入编辑模式 |
| i |
在当前字符前插入字符 |
| I |
在当前行行首插入字符 |
| a |
在当前字符后插入字符 |
| A |
在当前行行末插入字符 |
| o |
在当前行下插入新的一行 |
| O |
在当前行上插入新的一行 |
| r |
替换光标所在的字符,只替换一次 |
| R |
一直替换光标所在的字符,一直到按下ESC |
| 命令模式 |
| :w |
将编辑过的文本保存 |
| :w! |
若文本属性为只读时,强制保存 |
| :q |
退出vim |
| :q! |
不管编辑或未编辑都不保存退出 |
| :wq |
保存,退出 |
| :e! |
将文档还原成最原始状态 |
| ZZ |
若文档没有改动,则不储存离开,若文档改动过,则储存后离开,等同于:wq |
| :w [filename] |
编辑后的文档另存为filename |
| :r [filename] |
在当前光标所在行的下面读入filename文档的内容 |
| :set nu |
在每行的行首显示行号 |
| :set nonu |
取消行号 |
| n1,n2 w [filename] |
将n1到n2的内容另存为filename这个文档 |
| :! command |
暂时离开vim运行某个linux命令,例如 :! ls /home暂时列出/home目录下的文件,然后会提示按回车回到vim |
留一个小作业,希望认真完成
-
请把/etc/init.d/iptables 复制到/root/目录下,并重命名为test.txt
-
用vim打开test.txt并设置行号
-
分别向下、向右、向左、向右移动5个字符
-
分别向下、向上翻两页
-
把光标移动到第49行
-
让光标移动到行末,再移动到行首
-
移动到test.txt文件的最后一行
-
移动到文件的首行
-
搜索文件中出现的 iptables 并数一下一共出现多少个
-
把从第一行到第三行出现的iptables 替换成iptable
-
还原上一步操作
-
把整个文件中所有的iptables替换成iptable
-
把光标移动到50行,删除字符”$”
-
还原上一步操作
-
删除第50行
-
还原上一步操作
-
删除从37行到42行的所有内容
-
还原上一步操作
-
复制48行并粘贴到52行下面
-
还原上一步操作(按两次u)
-
复制从37行到42行的内容并粘贴到44行上面
-
还原上一步操作(按两次u)
-
把37行到42行的内容移动到19行下面
-
还原上一步操作(按两次u)
-
光标移动到首行,把/bin/sh 改成 /bin/bash
-
在第一行下面插入新的一行,并输入”# Hello!”
- 保存文档并退出
配置主机名
在centos系列的主机名称保存在/etc/hostname文件中。
用vim 修改配置文件即可
或者用命令直接修改
hostnamectl set-hostname 主机名 这样也可以达到永久修改主机名的效果
配置网卡信息
网卡配置文件存放在/etc/sysconfig/network-scripts 中
网卡类型TYPE=Ethernet
地址分配模式BOOTPROTO=static
网卡名称NAME=en33
是否启动ONBOOT=yes
IP地址IPADDR=
网关地址GATEWAY=
子网掩码NETMASK=
DNS地址DNS1=
或者用命令的模式快速配置IP;DNS;网关
nmcli connection modify 网卡名 \
ipv4.addresses IP/子网掩码 \
ipv4.gateway 网关 \
ipv4.dns dns \
ipv4.method manual yes
然后启动网卡 nmcli connection 网卡名 up
查看网卡 信息 nmcli connection show
配置yum仓库
配置yum仓库的步骤
1.切换到/etc/yum.repos.d/目录中 因为该目录存放着yum仓库的配置文件
2.使用vim编辑器创建一个一.repo结尾的新文件,名称可以自定义,但后缀名必须要以.repo结尾
3.写入配置参数,保存退出。(包括:仓库名,仓库描述,仓库地址,启用仓库,不启用签名检查等信息)
4.按配置参数的路径将光盘挂载
5.将光盘挂载信息写入到 /etc/fstab/文件中
检查仓库配置是否正确
yum -y install httpd 安装一个软件,看看是否可以正常安装,可以安装就说明配置没有问题。
也可以用命令的方式快速建立yum仓库
yum-config-manager –add-repo “仓库路径” 添加仓库
yum-config-manager –disable “仓库名" 禁用仓库
yum-config-manager –enable “仓库名” 启用仓库
yum -y install 软件名 安装软件
yum clean all 清楚所有缓存
yum repolist 显示软件列表
yum update 软件名 更新软件
脚本
shell作为用户与系统通讯的媒介,自身有人定义了各种变量与参数,并提供诸如循环,分支等高级语言才有的控制结构特性。如何正确使用这些功能,准确下达命令就显得很重要。
shell的工作模式分为两种一种以交互式(Interactive)和批量处理(Batch)
查看系统中所有可用的shell解析器:cat /etc/shells
/bin/sh
/bin/bash
/sbin/nologin
/usr/bin/sh
/usr/bin/bash
/usr/sbin/nologin
/bin/tcsh
/bin/csh
查看当前的shell解析器:echo $SHELL
shell 脚本的编写要使用到vim文本编辑器,按照命令的执行顺序依次编写,每行一条linux命令。并且一个完整的shell脚本则应该包括:脚本声明;注释信息;可执行语句。
脚本声明(#!) 告知系统用何种解析器来解析
可执行语句:执行的具体命令
最后写完脚本要为脚本设置可执行权限后才可以顺利执行 chmod +x 脚本名
脚本的预定义变量
$0 当前执行shell脚本的程序名。
$1-3,${10},${11}............ 参数的位置变量
$# 一共有多少个参数
$* 所有位置变量的值
$? 判断上一条命令是否执行成功,0为成功,非0为失败
文件测试
-e 文件存在
-a 文件存在
这个选项的效果与-e相同. 但是它已经被"弃用"了, 并且不鼓励使用.
-f 表示这个文件是一个一般文件(并不是目录或者设备 文件)
-s 文件大小不为零
-d 表示这是一个目录
-b 表示这是一个块设备(软盘, 光驱, 等等.)
-c 表示这是一个字符设备(键盘, modem, 声卡, 等等.)
-p 这个文件是一个管 道
-h 这是一个符 号链接
-L 这是一个符号链接
-S 表示这是一个socket
-t 文件(描 述符)被关联到一个终端设备上
这个测试选项一般被用来检测脚本中的stdin([ -t 0 ]) 或者stdout([ -t 1 ])是否来自于一个终端.
-r 文件是否具有可读权限(指的是正在运 行这个测试命令的用户是否具有读权限)
-w 文件是否具有可写权限(指的是正在运行这个测试命令的用户是否具有写权限)
-x 文件是否具有可执行权限(指的是正在运行这个测试命令的用户是否具有可执行权限)
-g set-group-id(sgid)标记被设置到文件或目录上
如果目录具有sgid标 记的话, 那么在这个目录下所创建的文件将属于拥有这个目录的用户组, 而不必是创建这个文件的用户组. 这个特性对于在一个工作组中共享目录非常有用.
-u set-user-id (suid)标记被设置到文件上
如果一个root用户所拥有的二进制可执行文件设置了set-user-id标记位的话, 那么普通用户也会以root权限来 运行这个文件. [1] 这对于需要访问系统硬件的执行程序(比如pppd和cdrecord)非常有用. 如果没有suid标志的话, 这些二进制执行程序是不能够被非root用户调用的.
-O 判断你是否是文件的拥有者
-G 文件的group-id是否与你的相同
-N 从文件上一次被读取到现在为止, 文件是否被修改过
f1 -nt f2
文件f1比 文件f2新
f1 -ot f2
文件f1比 文件f2旧
f1 -ef f2
文件f1和 文件f2是相同文件的 硬链接
!
"非" -- 反转上边所有测试的结果(如果没给出条件, 那么返回真)
例子 测试/etc/fstab是否为目录
[-d /etc/fsatab ]
显示上一条命令的返回值,非0则为失败,即不是目录
逻辑测试 [表达式1] 操作符 [表达式2]
&& 逻辑的与,而且的意思
|| 逻辑的或,或者的意思
! 逻辑的非。
整数值比较[整数1] 操作符 [整数2]
-eq 等于
-ne 不等于
-gt 大于
-lt 小于
-le 等于或小于
-ge 大于或等于
字符串比较:[字符串1 操作符 字符串2]
= 比较字符串内容是否相同
!= 比较字符串内容是否不同
-z 判断字符串内容是否为空
条件测试语句
if条件语句可分为单分支结构,双分支结构,多分支结构,复杂度逐步上升,但却可以让shell脚本更加的灵活
单分支结构 仅用 if then fi 关键词组成,只在条件成立后执行。
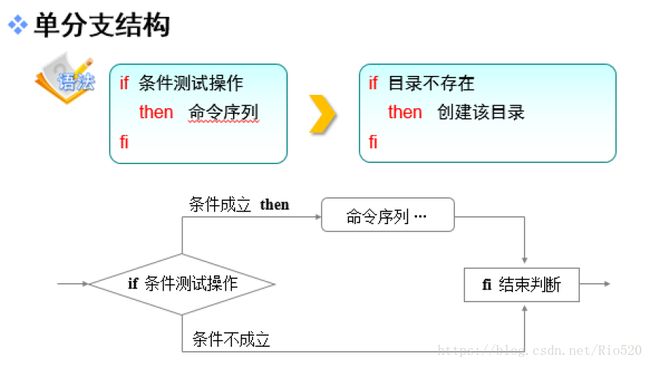
双分支结构是由if then else fi 关键词组成,做条件成立或条件不成立的判断
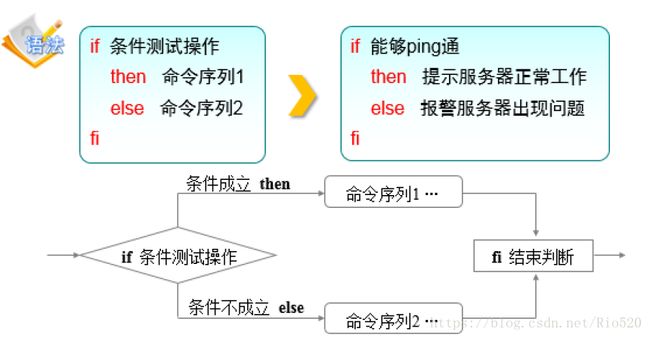
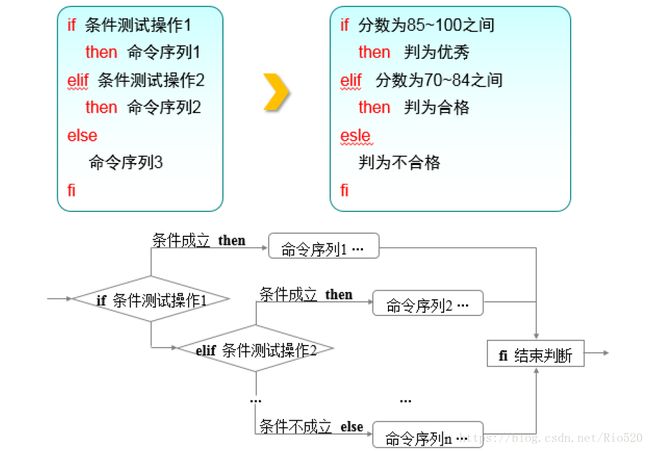
多分支结构相对比较复杂了,是由if then else elif fi 关键词组成,根据多种条件成立的可能性执行不同的操作
read命令用于将用户的输入参数赋值给指定变量,格式为:“read -p [提示语句] 变量名”
for条件语句
for条件语句先读取多个不同的变量值,然后逐一执行同一组命令。
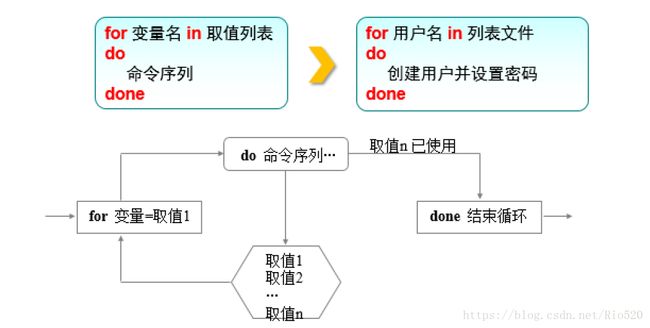
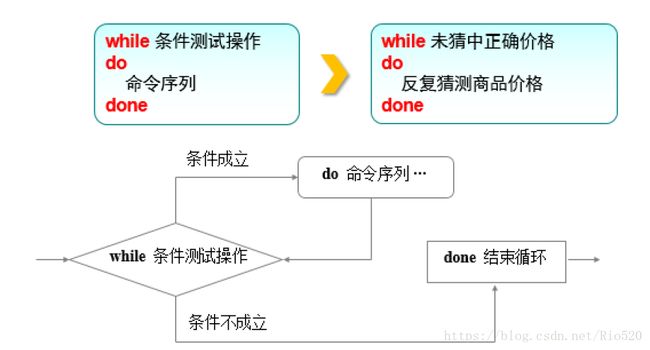
while条件语句
whille 条件语句用于重复测试某个条件,当条件成立时则继续重复执行
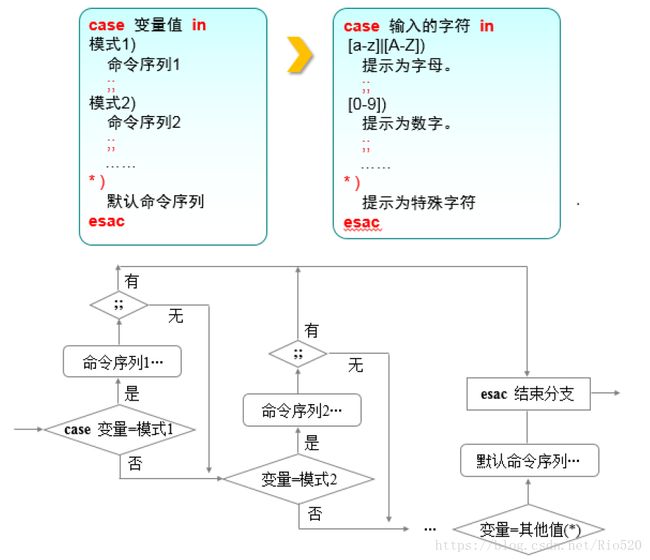
case条件语句
case条件可以依据标量的不同,分别执行不同的命令动作
周期性计划任务crontab
一次性任务,是由atd服务/进程来实现的,计划的管理操作是"at"命令。具体参数如下
at <时间> 安排一次性任务
atq或at -l 查看任务表
at -c 序号 预览任务与设置环境
atrm 序号 删除任务
对于创建长期可循环的计划任务,则需要用到cron服务,具体使用方法如下。
crontab命令:
crontab [-u user] [-l | -r | -e] [-i]
-e:编辑任务;
-l:列出所有任务;
-r:移除所有任务;即删除/var/spool/cron/USERNAME文件;
-i:在使用-r选项移除所有任务时提示用户确认;
-u user:root用户可为指定用户管理cron任务;
Example of job definition:
# .---------------- minute (0 - 59)分
# | .------------- hour (0 - 23)时
# | | .---------- day of month (1 - 31)日
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...月
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat周
# | | | | |
# * * * * * command to be executed
分 时 日 月 周
用户身份与文件权限
UID 每个用户都有对应的UID值,就像我们的身份证号码
超级用户UID:默认为0
系统用户UID1-999:系统中服务由不同用户运行,更加安全,默认被限制登录系统
普通用户UID1000~:即管理员创建的用于 日常工作而不能管理系统的普通用户
账户与UID保存在/etc/passwd 账户密码则保存在/etc/ shadow 中
GID:可将多个用户加入某个组中,方便指派任务或工作 (其GID与 UID相同俗称,基本组) 而后加入的则叫扩展组。
用户组名称与GID保存在/etc/group文件中。
文件权限与属性


文件的特殊权限
SUIDD:让执行者临时拥有属主的权限(仅对拥有执行权限的二进制程序有效)
GUIDD功能一:让执行者临时拥有属主的权限(对拥有执行权限的二进制程序设置)
功能二:在该目录中创建的文件自动继承此目录用户组(只可以对目录设置)
chmod 命令用于修改文件或目录的权限,格式为 chmod [参数] 权限 文件或目录
chown 命令用于修改文件或目录的所属主与所属组,格式为 chown[参数] 所属主:所属组 文件或目录
SBIT:只可管理自己的数据而不能删除他人的文件(仅对目录有效)
文件对的隐藏属性
chattr 命令用于设置文件的隐藏权限,格式为 chattr [参数] 文件
- a:让文件或目录仅供附加用途。
- b:不更新文件或目录的最后存取时间。
- c:将文件或目录压缩后存放。
- d:将文件或目录排除在倾倒操作之外。
- i:不得任意更动文件或目录。
- s:保密性删除文件或目录。
- S:即时更新文件或目录。
- u:预防意外删除。
lsattr 命令用于显示文件的隐藏权限 格式: lsattr [参数] 文件
参数:
- -a 显示所有文件和目录,包括以"."为名称开头字符的额外内建,现行目录"."与上层目录".."。
- -d 显示,目录名称,而非其内容。
- -l 此参数目前没有任何作用。
- -R 递归处理,将指定目录下的所有文件及子目录一并处理。
- -v 显示文件或目录版本。
- -V 显示版本信息。
su命令与sudo服务
su 命令用于变更使用者的身份(切换登录者) 格式为: su [-] 用户名 若需将环境变量改变为新用户的加[-]
sudo命令用来以其他身份来执行命令,预设的身份为root。
格式为 sudo [参数] 命令名称
-b:在后台执行指令;
-h:显示帮助;
-H:将HOME环境变量设为新身份的HOME环境变量;
-k:结束密码的有效期限,也就是下次再执行sudo时便需要输入密码;。
-l:列出目前用户可执行与无法执行的指令;
-p:改变询问密码的提示符号;
-s:执行指定的shell;
-u<用户>:以指定的用户作为新的身份。若不加上此参数,则预设以root作为新的身份;
-v:延长密码有效期限5分钟;
-V :显示版本信息。 文件访问控制列表
setfacl命令是用来在命令行里设置ACL(访问控制列表)。
格式为: setfacl [参数] 文件
-b:--remove-all:删除所有扩展的acl规则,基本的acl规则(所有者,群组,其他)将被保留。
-k:--remove-default:删除缺省的acl规则。如果没有缺省规则,将不提示。
-n:--no-mask:不要重新计算有效权限。setfacl默认会重新计算ACL mask,除非mask被明确的制定。
-m:--mask:重新计算有效权限,即使ACL mask被明确指定。
-d:--default:设定默认的acl规则。
-r:--restore=file:从文件恢复备份的acl规则(这些文件可由getfacl -R产生)。通过这种机制可以恢复整个目录树的acl规则。此参数不能和除--test以外的任何参数一同执行。
-t:--test:测试模式,不会改变任何文件的acl规则,操作后的acl规格将被列出。
-R:--recursive:递归的对所有文件及目录进行操作。
-L:--logical:跟踪符号链接,默认情况下只跟踪符号链接文件,跳过符号链接目录。
-P:--physical:跳过所有符号链接,包括符号链接文件。
-v:--version:输出setfacl的版本号并退出。
-h:--help:输出帮助信息。
--:标识命令行参数结束,其后的所有参数都将被认为是文件名
-:如果文件名是-,则setfacl将从标准输入读取文件名。getfacl 命令用于显示文件的ACL规则,格式为: getfacl 文件
df命令用于查看挂载点信息与磁盘使用情况 格式为: df 【选项】 文件
-a 全部文件系统列表
-h 方便阅读方式显示
-H 等于“-h”,但是计算式,1K=1000,而不是1K=1024
-i 显示inode信息
-k 区块为1024字节
-l 只显示本地文件系统
-m 区块为1048576字节
--no-sync 忽略 sync 命令
-P 输出格式为POSIX
--sync 在取得磁盘信息前,先执行sync命令
-T 文件系统类型
选择参数:
--block-size=<区块大小> 指定区块大小
-t<文件系统类型> 只显示选定文件系统的磁盘信息
-x<文件系统类型> 不显示选定文件系统的磁盘信息
--help 显示帮助信息
--version 显示版本信息
du命令用于查看磁盘的使用量,格式为 du [选项] 文件
a或-all 显示目录中个别文件的大小。
-b或-bytes 显示目录或文件大小时,以byte为单位。
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和。
-k或--kilobytes 以KB(1024bytes)为单位输出。
-m或--megabytes 以MB为单位输出。
-s或--summarize 仅显示总计,只列出最后加总的值。
-h或--human-readable 以K,M,G为单位,提高信息的可读性。
-x或--one-file-xystem 以一开始处理时的文件系统为准,若遇上其它不同的文件系统目录则略过。
-L<符号链接>或--dereference<符号链接> 显示选项中所指定符号链接的源文件大小。
-S或--separate-dirs 显示个别目录的大小时,并不含其子目录的大小。
-X<文件>或--exclude-from=<文件> 在<文件>指定目录或文件。
--exclude=<目录或文件> 略过指定的目录或文件。
-D或--dereference-args 显示指定符号链接的源文件大小。
-H或--si 与-h参数相同,但是K,M,G是以1000为换算单位。
-l或--count-links 重复计算硬件链接的文件。
磁盘管理磁盘分区
分区工具fdisk用法介绍
fdisk命令参数介绍
p、打印分区表。
n、新建一个新分区。
d、删除一个分区。
q、退出不保存。
w、把分区写进分区表,保存并退出。
[root@localhost ~]# fdisk /dev/hdd
按"p"键打印分区表
这块硬磁尚未分区
按"n"键新建一个分区。
出现两个菜单e表示扩展分区,p表示主分区
按"p"键出现提示:"Partition number (1-4): "选择主分区号
输入"1"表示第一个主分区。
直接按回车表示1柱面开始分区。
提示最后一个柱面或大小。
输入+5620M 按回车
表示第一个分区为5G空间。
按"p"查看一下分区
这样一个主分区就分好了。
接下来分第二个主分区,把剩余空间都给第二个主分区。
按"n"
键新增一个分区
按"p"键设为主分区
输入"2"把主分区编号设为2
按两下回车把剩余空间分给第二个主分区。
按"p"键打印分区
按"w"键保存退出。
可根据自己的硬盘大小来划分合适的分区。
4、使用分区
在使用硬盘之前必须对其分区进行格式化,并挂载。
[root@localhost ~]#mkfs.ext3 /dev/hdd1
[root@localhost ~]#mkfs.ext3 /dev/hdd2
创建挂载目录
[root@localhost ~]#mkdir /hdd1 /hdd2
挂载/dev/hdd1 /dev/hdd2
[root@localhost ~]#mount /dev/hdd1 /hdd1
[root@localhost ~]#mount /dev/hdd2 /hdd2
查看
[root@localhost ~]#df -h
Filesystem Size Used Avail Use% Mounted on
/dev/hda3 7.5G 2.8G 4.3G 40% /
/dev/hda1 99M 17M 78M 18% /boot
tmpfs 62M 0 62M 0% /dev/shm
/dev/hdd1 2.5G 68M 2.3G 3% /hdd1
/dev/hdd2 2.5G 68M 2.3G 3% /hdd2
lvm逻辑卷管理
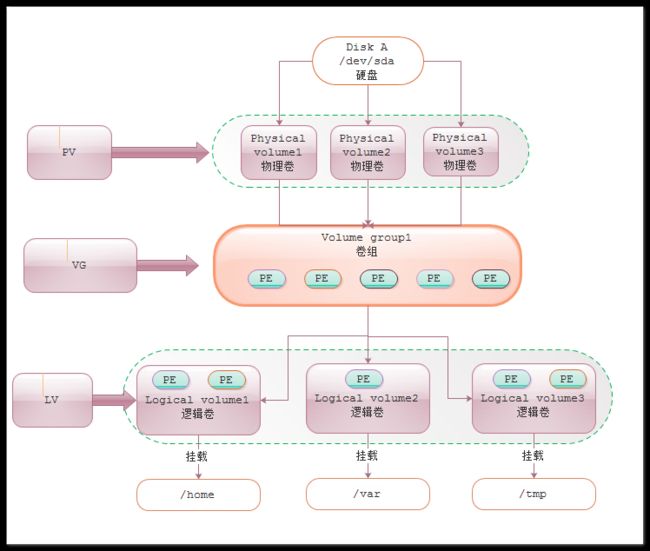
LVM的基本组成块(building blocks)如下:
物理卷Physical volume (PV) :可以在上面建立卷组的媒介,可以是硬盘分区,也可以是硬盘本身或者回环文件(loopback file)。物理卷包括一个特殊的header,其余部分被切割为一块块物理区域(physical extents)。 Think of physical volumes as big building blocks which can be used to build your hard drive.
卷组Volume group (VG) :将一组物理卷收集为一个管理单元。Group of physical volumes that are used as storage volume (as one disk). They contain logical volumes. Think of volume groups as hard drives.
逻辑卷Logical volume (LV) :虚拟分区,由物理区域(physical extents)组成。A “virtual/logical partition” that resides in a volume group and is composed of physical extents. Think of logical volumes as normal partitions.
物理区域Physical extent (PE) :硬盘可供指派给逻辑卷的最小单位(通常为4MB)。A small part of a disk (usually 4MB) that can be assigned to a logical Volume. Think of physical extents as parts of disks that can be allocated to any partition.
优点
比起正常的硬盘分区管理,LVM更富于弹性:
- 使用卷组(VG),使众多硬盘空间看起来像一个大硬盘。
- 使用逻辑卷(LV),可以创建跨越众多硬盘空间的分区。
- 可以创建小的逻辑卷(LV),在空间不足时再动态调整它的大小。
- 在调整逻辑卷(LV)大小时可以不用考虑逻辑卷在硬盘上的位置,不用担心没有可用的连续空间。It does not depend on the position of the LV within VG, there is no need to ensure surrounding available space.
- 可以在线(online)对逻辑卷(LV)和卷组(VG)进行创建、删除、调整大小等操作。LVM上的文件系统也需要重新调整大小,某些文件系统也支持这样的在线操作。
- 无需重新启动服务,就可以将服务中用到的逻辑卷(LV)在线(online)/动态(live)迁移至别的硬盘上。
- 允许创建快照,可以保存文件系统的备份,同时使服务的下线时间(downtime)降低到最小。
LVM
|
|
LVM扩展
LVM特点就是支持在线动态扩容,如果为了稳妥也可以先umount
|
|
LVM缩减
注意减少的大小,实施前umount逻辑卷
|
|
扩展卷组
步骤和创建VG类似
|
|
删除卷组
|
|
lvchange
在做HA共享存储时需要配合lvchange激活lv
|
|
命令总结
| 任务 | PV 阶段 | VG 阶段 | LV 阶段 |
|---|---|---|---|
| 搜寻 (scan) | pvscan | vgscan | lvscan |
| 创建 (create) | pvcreate | vgcreate | lvcreate |
| 列出 (display) | pvdisplay | vgdisplay | lvdisplay |
| 扩展 (extend) | vgextend | lvextend (lvresize) | |
| 减少 (reduce) | vgreduce | lvreduce (lvresize) | |
| 删除 (remove) | pvremove | vgremove | lvremove |
| 改变容量 (resize) | lvresize | ||
| 改变属性 (attribute) | pvchange | vgchange | lvchange |
RAID磁盘阵列
RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,通常简称为磁盘阵列。简单地说, RAID 是由多个独立的高性能磁盘驱动器组成的磁盘子系统,从而提供比单个磁盘更高的存储性能和数据冗余的技术。
RAID 中主要有三个关键概念和技术:镜像( Mirroring )、数据条带( Data Stripping )和数据校验( Data parity )。镜像,将数据复制到多个磁盘,一方面可以提高可靠性,另一方面可并发从两个或多个副本读取数据来提高读性能。
RAID 主要优势有如下几点:(1) 大容量 (2) 高性能 (3) 可靠性 (4) 可管理性
常见的RAID类型
| RAID 等级 | RAID0 | RAID1 | RAID5 | RAID6 | RAID10 |
|---|---|---|---|---|---|
| 别名 | 条带 | 镜像 | 分布奇偶校验条带 | 双重奇偶校验条带 | 镜像加条带 |
| 容错性 | 无 | 有 | 有 | 有 | 有 |
| 冗余类型 | 无 | 有 | 有 | 有 | 有 |
| 热备盘 | 无 | 有 | 有 | 有 | 有 |
| 读性能 | 高 | 低 | 高 | 高 | 高 |
| 随机写性能 | 高 | 低 | 一般 | 低 | 一般 |
| 连续写性能 | 高 | 低 | 低 | 低 | 一般 |
| 需要磁盘数 | n≥1 | 2n (n≥1) | n≥3 | n≥4 | 2n(n≥2)≥4 |
| 可用容量 | 全部 | 50% | (n-1)/n | (n-2)/n | 50% |
创建软件RAID是通过 mdadm 这个命令来创建的,例如我们创建一个 RAID 0,其语法格式如下:
创建RAID 0: mdadm -C /dev/md0 -a yes -l 0 -n 2 /dev/sdb /dev sdc
创建RAID 1: mdadm -C /dev/md1 -a yes -l 1 -n 2 /dev/sdb /dev/sdc
创建RAID 5: mdadm -C /dev/md2 -a yes -l 5 -n 3 /dev/sdb /dev/sdc /dev/sdd
创建RAID 6: mdadm -C /dev/md3 -a yes -l 6 -n 4 /dev/sdb /dev/sdc /dev/sdd /dev/sde
可以使用 -x 参数来指定一个备份磁盘,备份磁盘一般不使用,当出现一个磁盘故障的时候,指定的备份磁盘可以自动上线工作:
mdadm -C /dev/md0 -a yes -l 5 -n 3 -x /dev/sdb /dev/sdc /dev/sdd /dev/sde①-C 创建一个新的RAID 我们这里就是创建第一个RAID,名字叫做 /dev/md0
② -a 自动创建对应的设备 yes表示会自动在/dev下创建该RAID设备
③ -l 指定要创建的RAID级别 0我们这里创建RAID 0
④ -n 指定硬盘数量 2表示使用2块硬盘来创建这个RAID0,分别是 /dev/sdb 和 /dev/sdc
到,我们创建了一个RAID5,使用了三块硬盘,此时我们指定了参数 -x ,表示我们指定了一块硬盘来作为备份磁盘,当其他三块磁盘中一块出现问题时,这个指定备份硬盘就可以自动上线工作了。
接下来我们通过来创建一个RAID 0来看看 mdadm 命令的使用:
[root@xiaoluo ~]# mdadm -C /dev/md0 -a yes -l 0 -n 2 /dev/sdb /dev/sdc
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@xiaoluo ~]# ls -l /dev/md0
brw-rw----. 1 root disk 9, 0 May 25 22:36 /dev/md0此时我们就创建好了一个RAID 0,我们发现 /dev 下也存在了一个叫做 md0的设备了,我们可以使用 mdadm -D 这个命令来查看刚创建的RAID的详细信息,或者来查看 /proc/mdstat这个文件来查看RAID的信息
[root@xiaoluo ~]# cat /proc/mdstat
Personalities : [raid0]
md0 : active raid0 sdc[1] sdb[0]
2096128 blocks super 1.2 512k chunks
unused devices:
[root@xiaoluo ~]# mdadm -D
mdadm: No devices given.
[root@xiaoluo ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sat May 25 22:36:15 2013
Raid Level : raid0
Array Size : 2096128 (2047.34 MiB 2146.44 MB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Sat May 25 22:36:15 2013
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Chunk Size : 512K
Name : xiaoluo:0 (local to host xiaoluo)
UUID : fe746431:4d77f0e9:e1c1a06f:1d341790
Events : 0
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb //创建好的RAID 0使用了 /dev/sdb /dev/sdc这两块硬盘
1 8 32 1 active sync /dev/sdc
【注意:】我们在创建好RAID以后,需要将RAID的信息保存到 /etc/mdadm.conf 这个文件里,这样在下次操作系统重新启动的时候,系统就会自动加载这个文件来启用我们的RAID
[root@xiaoluo ~]# mdadm -D --scan > /etc/mdadm.conf
[root@xiaoluo ~]# cat /etc/mdadm.conf
ARRAY /dev/md0 metadata=1.2 name=xiaoluo:0 UUID=fe746431:4d77f0e9:e1c1a06f:1d341790
这样我们在下次系统重新启动的时候,RAID也会自动启用了
在创建了这个RAID 0以后,我们就不能再去使用 /dev/sdb 和 /dev/sdc 这个硬盘了,一旦对其进行任何操作,都会损坏我们刚创建好的RAID,所以我们此时就是使用RAID 0这个设备来对其进行文件系统格式化和挂载使用了
[root@xiaoluo ~]# mkfs.ext4 /dev/md0
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=128 blocks, Stripe width=256 blocks
131072 inodes, 524032 blocks
26201 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=536870912
16 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 24 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
[root@xiaoluo ~]# mount /dev/md0 /mnt
[root@xiaoluo ~]# mount
/dev/sda2 on / type ext4 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
tmpfs on /dev/shm type tmpfs (rw,rootcontext="system_u:object_r:tmpfs_t:s0")
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
/dev/md0 on /mnt type ext4 (rw) // 我们的/dev/md0 已经挂载上可以使用了
[root@xiaoluo ~]# cd /mnt/
[root@xiaoluo mnt]# ls
lost+found这个时候我们就是使用RAID来进行文件的操作了,创建的时候使用的是RAID哪个级别,那么该RAID就会具有该级别的读写特性。在创建完RAID以后,我们就可以像使用分区一样来使用这个RAID了
我们也可以通过 mdadm -S 这命令来关闭我们的 RAID ,当然在关闭RAID之前,我们需要先卸载掉RAID
[root@xiaoluo mnt]# cd
[root@xiaoluo ~]# umount /mnt
[root@xiaoluo ~]# mdadm -S /dev/md0
mdadm: stopped /dev/md0
通常如果我们要重新启动我们的RAID,可以使用 mdadm -R 这个命令,但是可能是由于操作系统或者是软件的版本,在关闭RAID以后,使用这个命令会提示找不到该文件
[root@xiaoluo ~]# mdadm -R /dev/md0
mdadm: error opening /dev/md0: No such file or directory这个时候我们只需要重新启动一下操作系统即可,因为我们刚才已经经RAID的信息保存在了 /etc/mdadm.conf 这个文件里了
[root@xiaoluo ~]# ls -l /dev/md0
brw-rw----. 1 root disk 9, 0 May 25 22:57 /dev/md0我们看到在重新启动操作系统后,刚才那个RAID设备又有了。
如果说我此时需要从该设备中拿走一块硬盘,或者说我要完全的删除这个RAID,从而像以前那样正常使用我们刚用作RAID的硬盘,这个时候我们应该怎么做呢?
通过 mdadm --zero-superblock 这个命令即可,但是我们首先必须要停止我们的RAID,即使用 mdadm -S 命令。例如我要将刚才创建的RAID 0 的两块硬盘完全移除,就可以使用如下命令:
[root@xiaoluo ~]# mdadm -S /dev/md0
mdadm: stopped /dev/md0
[root@xiaoluo ~]# mdadm --zero-superblock /dev/sdb
[root@xiaoluo ~]# mdadm --zero-superblock /dev/sdc这个时候,我们的RAID 0的信息就全部被清除掉了,刚才那两块硬盘我们也就能够正常的单独使用了。
我们这里再来实验一下创建一个 RAID 5,然后来讲解一下如何模拟故障的命令
[root@xiaoluo ~]# mdadm -C /dev/md0 -a yes -l 5 -n 3 /dev/sdb /dev/sdc /dev/sdd
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@xiaoluo ~]# cat /proc/mdstat
Personalities : [raid0] [raid6] [raid5] [raid4]
md0 : active raid5 sdd[3] sdc[1] sdb[0]
2095104 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [UU_]
[=================>...] recovery = 87.2% (915204/1047552) finish=0.0min speed=91520K/sec // 操作未完毕
unused devices: 【注意:】我们在创建RAID 5 或者RAID 6的时候,因为其还要对硬盘进行一些检查的操作,而且根据硬盘的大小时间可能会不同,我们在输入完 mdadm 命令以后,还必须要去查看 /proc/mdstat 这个文件,查看这个文件里面的进度信息是否已经完整,例如上面创建时进度才只有 87.2% ,我们必须要等进度显示完整以后才能做接下来的操作
[root@xiaoluo ~]# cat /proc/mdstat
Personalities : [raid0] [raid6] [raid5] [raid4]
md0 : active raid5 sdd[3] sdc[1] sdb[0]
2095104 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU] // 操作完毕
unused devices: 通过mdadm -D 可以查看RAID详细信息:
[root@xiaoluo ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sat May 25 23:07:06 2013
Raid Level : raid5
Array Size : 2095104 (2046.34 MiB 2145.39 MB)
Used Dev Size : 1047552 (1023.17 MiB 1072.69 MB)
Raid Devices : 3
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Sat May 25 23:07:18 2013
State : clean
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Name : xiaoluo:0 (local to host xiaoluo)
UUID : 029e2fe7:8c9ded40:f5079536:d249ccf7
Events : 18
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
3 8 48 2 active sync /dev/sdd
实验环境下,我们还可以通过 mdadm 命令来模拟RAID故障,通过 mdadm /dev/md0 -f /dev/sdd 命令
[root@xiaoluo ~]# mdadm /dev/md0 -f /dev/sdd
mdadm: set /dev/sdd faulty in /dev/md0我们可以再查看一下这个RAID的信息:
[root@xiaoluo ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sat May 25 23:07:06 2013
Raid Level : raid5
Array Size : 2095104 (2046.34 MiB 2145.39 MB)
Used Dev Size : 1047552 (1023.17 MiB 1072.69 MB)
Raid Devices : 3
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Sat May 25 23:13:44 2013
State : clean, degraded
Active Devices : 2
Working Devices : 2
Failed Devices : 1
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Name : xiaoluo:0 (local to host xiaoluo)
UUID : 029e2fe7:8c9ded40:f5079536:d249ccf7
Events : 19
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
2 0 0 2 removed
3 8 48 - faulty spare /dev/sdd // 这块硬盘被标志成了坏的硬盘
我们看到 /dev/sdd 这块硬盘被标志成了坏的硬盘,因为我们使用的是RAID 5这个级别,所以一块硬盘损坏了,并不会对数据造成损坏,数据还是完好无整的
我们可以通过 mdadm /dev/md0 -r /dev/sdd 来移除这块硬盘
[root@xiaoluo ~]# mdadm /dev/md0 -r /dev/sdd
mdadm: hot removed /dev/sdd from /dev/md0
[root@xiaoluo ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sat May 25 23:07:06 2013
Raid Level : raid5
Array Size : 2095104 (2046.34 MiB 2145.39 MB)
Used Dev Size : 1047552 (1023.17 MiB 1072.69 MB)
Raid Devices : 3
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Sat May 25 23:17:12 2013
State : clean, degraded
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Name : xiaoluo:0 (local to host xiaoluo)
UUID : 029e2fe7:8c9ded40:f5079536:d249ccf7
Events : 22
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
2 0 0 2 removed // /dev/sdd 已经被移除掉了
如果我们要换上新的硬盘,则可以使用 mdadm /dev/md0 -a /dev/sde 这个命令
[root@xiaoluo ~]# mdadm /dev/md0 -a /dev/sde
mdadm: added /dev/sde
[root@xiaoluo ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sat May 25 23:07:06 2013
Raid Level : raid5
Array Size : 2095104 (2046.34 MiB 2145.39 MB)
Used Dev Size : 1047552 (1023.17 MiB 1072.69 MB)
Raid Devices : 3
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Sat May 25 23:19:15 2013
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Rebuild Status : 90% complete
Name : xiaoluo:0 (local to host xiaoluo)
UUID : 029e2fe7:8c9ded40:f5079536:d249ccf7
Events : 40
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
3 8 64 2 spare rebuilding /dev/sde // 新的/dev/sde硬盘已经增加进来软硬方式连接
ln 命令用于创建链接文件 格式 ln [选项] 目标
创建硬链接 ln 文件名 链接名
创建软链接 ln 文件名 链接名
-s 创建“符号链接”(默认是硬链接)
-f 强制创建文件或目录的链接
-i 覆盖前先询问
-v 显示创建链接的过程
iptables 与Firewalld防火墙
iptables(选项)(参数)
| 参数 | 作用 | |
|---|---|---|
| -P | 设置默认策略:iptables -P INPUT (DROP | ACCEPT) |
| -F | 清空规则链 | |
| -L | 查看规则链 | |
| -A | 在规则链的末尾加入新规则 | |
| -I | num 在规则链的头部加入新规则 | |
| -D | num 删除某一条规则 | |
| -s | 匹配来源地址IP/MASK,加叹号"!"表示除这个IP外。 | |
| -d | 匹配目标地址 | |
| -i | 网卡名称 匹配从这块网卡流入的数据 | |
| -o | 网卡名称 匹配从这块网卡流出的数据 | |
| -p | 匹配协议,如tcp,udp,icmp | |
| --dport num | 匹配目标端口号 | |
| --sport num | 匹配来源端口号 |
命令选项输入顺序
iptables -t 表名 <-A/I/D/R> 规则链名 [规则号] <-i/o 网卡名> -p 协议名 <-s 源IP/源子网> --sport 源端口 <-d 目标IP/目标子网> --dport 目标端口 -j 动作
规则链名包括(也被称为五个钩子函数(hook functions)):
- INPUT链 :处理输入数据包。
- OUTPUT链 :处理输出数据包。
- PORWARD链 :处理转发数据包。
- PREROUTING链 :用于目标地址转换(DNAT)。
- POSTOUTING链 :用于源地址转换(SNAT)
防火墙策略一般分为两种,一种叫通策略,一种叫堵策略,通策略,默认门是关着的,必须要定义谁能进。堵策略则是,大门是洞开的,但是你必须有身份认证,否则不能进。所以我们要定义,让进来的进来,让出去的出去,所以通,是要全通,而堵,则是要选择。
现在用的比较多个功能有3个:
- filter 定义允许或者不允许的,只能做在3个链上:INPUT ,FORWARD ,OUTPUT
- nat 定义地址转换的,也只能做在3个链上:PREROUTING ,OUTPUT ,POSTROUTING
- mangle功能:修改报文原数据,是5个链都可以做:PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING
小扩展:
- 对于filter来讲一般只能做在3个链上:INPUT ,FORWARD ,OUTPUT
- 对于nat来讲一般也只能做在3个链上:PREROUTING ,OUTPUT ,POSTROUTING
- 而mangle则是5个链都可以做:PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING
表名包括:
- raw :高级功能,如:网址过滤。
- mangle :数据包修改(QOS),用于实现服务质量。
- net :地址转换,用于网关路由器。
- filter :包过滤,用于防火墙规则。
动作包括:
- ACCEPT :接收数据包。
- DROP :丢弃数据包。
- REDIRECT :重定向、映射、透明代理。
- SNAT :源地址转换。
- DNAT :目标地址转换。
- MASQUERADE :IP伪装(NAT),用于ADSL。
- LOG :日志记录。
┏╍╍╍╍╍╍╍╍╍╍╍╍╍╍╍┓
┌───────────────┐ ┃ Network ┃
│ table: filter │ ┗━━━━━━━┳━━━━━━━┛
│ chain: INPUT │◀────┐ │
└───────┬───────┘ │ ▼
│ │ ┌───────────────────┐
┌ ▼ ┐ │ │ table: nat │
│local process│ │ │ chain: PREROUTING │
└ ┘ │ └─────────┬─────────┘
│ │ │
▼ │ ▼ ┌─────────────────┐
┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅ │ ┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅ │table: nat │
Routing decision └───── outing decision ─────▶│chain: PREROUTING│
┅┅┅┅┅┅┅┅┅┳┅┅┅┅┅┅┅┅┅ ┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅ └────────┬────────┘
│ │
▼ │
┌───────────────┐ │
│ table: nat │ ┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅┅ │
│ chain: OUTPUT │ ┌─────▶ outing decision ◀──────────────┘
└───────┬───────┘ │ ┅┅┅┅┅┅┅┅┳┅┅┅┅┅┅┅┅
│ │ │
▼ │ ▼
┌───────────────┐ │ ┌────────────────────┐
│ table: filter │ │ │ chain: POSTROUTING │
│ chain: OUTPUT ├────┘ └──────────┬─────────┘
└───────────────┘ │
▼
┏╍╍╍╍╍╍╍╍╍╍╍╍╍╍╍┓
┃ Network ┃
┗━━━━━━━━━━━━━━━┛实例
空当前的所有规则和计数
iptables -F # 清空所有的防火墙规则
iptables -X # 删除用户自定义的空链
iptables -Z # 清空计数
配置允许ssh端口连接
iptables -A INPUT -s 192.168.1.0/24 -p tcp --dport 22 -j ACCEPT
# 22为你的ssh端口, -s 192.168.1.0/24表示允许这个网段的机器来连接,其它网段的ip地址是登陆不了你的机器的。 -j ACCEPT表示接受这样的请求
允许本地回环地址可以正常使用
iptables -A INPUT -i lo -j ACCEPT
#本地圆环地址就是那个127.0.0.1,是本机上使用的,它进与出都设置为允许
iptables -A OUTPUT -o lo -j ACCEPT
设置默认的规则
iptables -P INPUT DROP # 配置默认的不让进
iptables -P FORWARD DROP # 默认的不允许转发
iptables -P OUTPUT ACCEPT # 默认的可以出去
配置白名单
iptables -A INPUT -p all -s 192.168.1.0/24 -j ACCEPT # 允许机房内网机器可以访问
iptables -A INPUT -p all -s 192.168.140.0/24 -j ACCEPT # 允许机房内网机器可以访问
iptables -A INPUT -p tcp -s 183.121.3.7 --dport 3380 -j ACCEPT # 允许183.121.3.7访问本机的3380端口
开启相应的服务端口
iptables -A INPUT -p tcp --dport 80 -j ACCEPT # 开启80端口,因为web对外都是这个端口
iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT # 允许被ping
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT # 已经建立的连接得让它进来
保存规则到配置文件中
cp /etc/sysconfig/iptables /etc/sysconfig/iptables.bak # 任何改动之前先备份,请保持这一优秀的习惯
iptables-save > /etc/sysconfig/iptables
cat /etc/sysconfig/iptables
列出已设置的规则
iptables -L [-t 表名] [链名]
- 四个表名
raw,nat,filter,mangle - 五个规则链名
INPUT、OUTPUT、FORWARD、PREROUTING、POSTROUTING - filter表包含
INPUT、OUTPUT、FORWARD三个规则链
iptables -L -t nat # 列出 nat 上面的所有规则
# ^ -t 参数指定,必须是 raw, nat,filter,mangle 中的一个
iptables -L -t nat --line-numbers # 规则带编号
iptables -L INPUT
iptables -L -nv # 查看,这个列表看起来更详细
清除已有规则
iptables -F INPUT # 清空指定链 INPUT 上面的所有规则
iptables -X INPUT # 删除指定的链,这个链必须没有被其它任何规则引用,而且这条上必须没有任何规则。
# 如果没有指定链名,则会删除该表中所有非内置的链。
iptables -Z INPUT # 把指定链,或者表中的所有链上的所有计数器清零。
删除已添加的规则
# 添加一条规则
iptables -A INPUT -s 192.168.1.5 -j DROP
将所有iptables以序号标记显示,执行:
iptables -L -n --line-numbers
比如要删除INPUT里序号为8的规则,执行:
iptables -D INPUT 8
开放指定的端口
iptables -A INPUT -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT #允许本地回环接口(即运行本机访问本机)
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT #允许已建立的或相关连的通行
iptables -A OUTPUT -j ACCEPT #允许所有本机向外的访问
iptables -A INPUT -p tcp --dport 22 -j ACCEPT #允许访问22端口
iptables -A INPUT -p tcp --dport 80 -j ACCEPT #允许访问80端口
iptables -A INPUT -p tcp --dport 21 -j ACCEPT #允许ftp服务的21端口
iptables -A INPUT -p tcp --dport 20 -j ACCEPT #允许FTP服务的20端口
iptables -A INPUT -j reject #禁止其他未允许的规则访问
iptables -A FORWARD -j REJECT #禁止其他未允许的规则访问
屏蔽IP
iptables -A INPUT -p tcp -m tcp -s 192.168.0.8 -j DROP # 屏蔽恶意主机(比如,192.168.0.8
iptables -I INPUT -s 123.45.6.7 -j DROP #屏蔽单个IP的命令
iptables -I INPUT -s 123.0.0.0/8 -j DROP #封整个段即从123.0.0.1到123.255.255.254的命令
iptables -I INPUT -s 124.45.0.0/16 -j DROP #封IP段即从123.45.0.1到123.45.255.254的命令
iptables -I INPUT -s 123.45.6.0/24 -j DROP #封IP段即从123.45.6.1到123.45.6.254的命令是
指定数据包出去的网络接口
只对 OUTPUT,FORWARD,POSTROUTING 三个链起作用。
iptables -A FORWARD -o eth0
查看已添加的规则
iptables -L -n -v
Chain INPUT (policy DROP 48106 packets, 2690K bytes)
pkts bytes target prot opt in out source destination
5075 589K ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0
191K 90M ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:22
1499K 133M ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
4364K 6351M ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
6256 327K ACCEPT icmp -- * * 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 3382K packets, 1819M bytes)
pkts bytes target prot opt in out source destination
5075 589K ACCEPT all -- * lo 0.0.0.0/0 0.0.0.0/0
启动网络转发规则
公网210.14.67.7让内网192.168.188.0/24上网
iptables -t nat -A POSTROUTING -s 192.168.188.0/24 -j SNAT --to-source 210.14.67.127
端口映射
本机的 2222 端口映射到内网 虚拟机的22 端口
iptables -t nat -A PREROUTING -d 210.14.67.127 -p tcp --dport 2222 -j DNAT --to-dest 192.168.188.115:22
字符串匹配
比如,我们要过滤所有TCP连接中的字符串test,一旦出现它我们就终止这个连接,我们可以这么做:
iptables -A INPUT -p tcp -m string --algo kmp --string "test" -j REJECT --reject-with tcp-reset
iptables -L
# Chain INPUT (policy ACCEPT)
# target prot opt source destination
# REJECT tcp -- anywhere anywhere STRING match "test" ALGO name kmp TO 65535 reject-with tcp-reset
#
# Chain FORWARD (policy ACCEPT)
# target prot opt source destination
#
# Chain OUTPUT (policy ACCEPT)
# target prot opt source destination
阻止Windows蠕虫的攻击
iptables -I INPUT -j DROP -p tcp -s 0.0.0.0/0 -m string --algo kmp --string "cmd.exe"
防止SYN洪水攻击
iptables -A INPUT -p tcp --syn -m limit --limit 5/second -j ACCEPTiptables内容来自:http://wangchujiang.com/linux-command/c/iptables.html
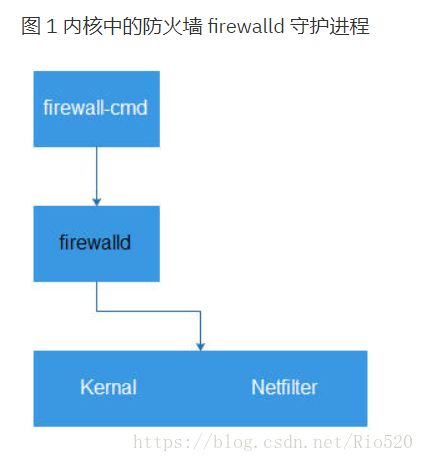
firewalld 主要功能 实现动态管理,对于规则的更改不再需要重新创建整个防火墙。
安装firewalld
# yum install firewalld firewall-config
启动服务
# systemctl enable firewalld.service
# systemctl start firewalld.service
查看状态
#systemctl status firewalld
在 /etc/firewalld/ 的区域设定是一系列可以被快速执行到网络接口的预设定。有几种不同的初始化区域:
drop(丢弃) 任何接收的网络连接都被 IPv4 的 icmp-host-prohibited 信息和 IPv6 的 icmp6-adm-prohibited 信息所拒绝。
public(公共) 在公共区域内使用,不能相信网络内的其他计算机不会对您的计算机造成危害,只能接收经过选取的连接。
external(外部) 特别是为路由器启用了伪装功能的外部网。您不能信任来自网络的其他计算,不能相信它们不会对您的计算机造成危害,只能接收经过选择的连接。
dmz(非军事区) 用于您的非军事区内的电脑,此区域内可公开访问,可以有限地进入您的内部网络,仅仅接收经过选择的连接。
work(工作) 用于工作区。您可以基本相信网络内的其他电脑不会危害您的电脑。仅仅接收经过选择的连接。
home(家庭) 用于家庭网络。您可以基本信任网络内的其他计算机不会危害您的计算机。仅仅接收经过选择的连接。
internal(内部) 用于内部网络。您可以基本上信任网络内的其他计算机不会威胁您的计算机。仅仅接受经过选择的连接。
trusted(信任) 可接受所有的网络连接。
显示支持的区域列表 firewall-cmd --get-zones
设置为家庭区域 firewall-cmd --set-default-zone=home
查看当前的区域 #firewall-cmd --get-active-zones
设置当前的区域的接口 #firewall-cmd --get-zone-of-interface=enp03s
显示所有公共区域(public) # firewall-cmd --zone=public --list-all
临时修改网络接口 enp0s3 为 内部区域(internal) firewall-cmd --zone=internal --change-interface=enp03s
永久修改网络接口 enp0s3 为 内部区域(internal) firewall-cmd --permanent --zone=internal --change-interface=enp03s
服务管理
显示服务列表 firewall-cmd --get-services
允许 ssh 服务通过 # firewall-cmd --enable service=ssh
禁止 ssh 服务通过 # firewall-cmd --disable service=ssh
临时允许 samba 服务通过 600 秒 # firewall-cmd --enable service=samba --timeout=600
显示当前服务 # firewall-cmd --list-services
添加 http 服务到内部区域(internal)firewall-cmd --permanent --zone=internal --add-service=http
# firewall-cmd – reload
将一个服务加入到分区
要把一个服务加入到分区,例如允许 SMTP 接入工作区
# firewall-cmd --zone=work --add-service=smtp
# firewall-cmd --reload
要从分区移除服务,比如从工作区移除 SMTP:
# firewall-cmd --zone=work --remove-service=smtp
# firewall-cmd --reload
端口管理
打开 443/tcp 端口在内部区域(internal):
# firewall-cmd --zone=internal --add-port=443/tcp
# firewall-cmd – reload
端口转发
# firewall-cmd --zone=external --add-masquerade
# firewall-cmd --zone=external --add-forward-port=port=22:proto=tcp:toport=3777
上面的两个命令的意思是,首先启用伪装(masquerade),然后把外部区域(external)的 22 端口转发到 3777。
关闭 firewalld 服务
# systemctl stop firewalld
# systemctl disable firewalld
# yum install iptables-services
# systemctl start iptables
# systemctl enable iptables
查看端口状态
ss 命令用于 查看本机的端口链接状态。
ss(Socket Statistics的缩写)命令可以用来获取 socket统计信息,此命令输出的结果类似于 netstat输出的内容,但它能显示更多更详细的 TCP连接状态的信息,且比 netstat 更快速高效。
格式 命令 【参数】
-h:--help 帮助信息
-V:--version 程序版本信息
-n: --numeric 不解析服务名称
-r: --resolve 解析主机名
-a: --all 显示所有套接字(sockets)
-l: --listening 显示监听状态的套接字(sockets)
-o: --options 显示计时器信息
-e: --extended 显示详细的套接字(sockets)信息
-m: --memory 显示套接字(socket)的内存使用情况
-p: --processes 显示使用套接字(socket)的进程
-i: --info 显示 TCP内部信息
-s: --summary 显示套接字(socket)使用概况
-4: --ipv4 仅显示IPv4的套接字(sockets)
-6: --ipv6 仅显示IPv6的套接字(sockets)
-0: --packet 显示 PACKET 套接字(socket)
-t: --tcp 仅显示 TCP套接字(sockets)
-u: --udp 仅显示 UCP套接字(sockets)
-d: --dccp 仅显示 DCCP套接字(sockets)
-w: --raw 仅显示 RAW套接字(sockets)
-x: --unix 仅显示 Unix套接字(sockets)
-f: --family=FAMILY 显示 FAMILY类型的套接字(sockets),FAMILY可选,支持 unix, inet, inet6, link, netlink
-A: --query=QUERY, --socket=QUERY QUERY := {all|inet|tcp|udp|raw|unix|packet|netlink}[,QUERY]
-D: --diag=FILE 将原始TCP套接字(sockets)信息转储到文件
-F: --filter=FILE 从文件中都去过滤器信息