pandas.get_dummies 的用法
get_dummies 是利用pandas实现one hot encode的方式。详细参数请查看官方文档
PS:针对非数值型数据处理,如想对数据型生效,比如类目特征,可将类目特征转为str,再进行one-hot编码,此时原列cate会新增为cate_1,cate_2等。
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)
例子:
import pandas as pd
df = pd.DataFrame([
['green' , 'A'],
['red' , 'B'],
['blue' , 'A']])
df.columns = ['color', 'class']
pd.get_dummies(df)
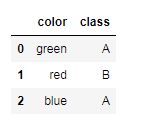
get_dummies 前:
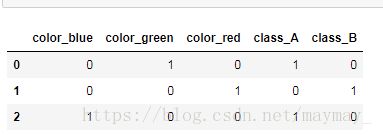
get_dummies 后:
上述执行完以后再打印df 出来的还是get_dummies 前的图,因为你没有写
df = pd.get_dummies(df)
可以对指定列进行get_dummies
pd.get_dummies(df.color)
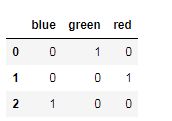
将指定列进行get_dummies 后合并到元数据中
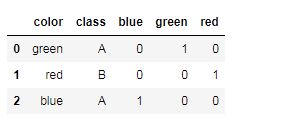
df = df.join(pd.get_dummies(df.color))
虚拟变量(dummy variables)
虚拟变量,也叫哑变量和离散特征编码,可用来表示分类变量、非数量因素可能产生的影响。
离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
使用pandas可以很方便的对离散型特征进行one-hot编码
[python] view plain copy
import pandas as pd
df = pd.DataFrame([
[‘green’, ‘M’, 10.1, ‘class1’],
[‘red’, ‘L’, 13.5, ‘class2’],
[‘blue’, ‘XL’, 15.3, ‘class1’]])
df.columns = [‘color’, ‘size’, ‘prize’, ‘class label’]
size_mapping = {
‘XL’: 3,
‘L’: 2,
‘M’: 1}
df[‘size’] = df[‘size’].map(size_mapping)
class_mapping = {label:idx for idx,label in enumerate(set(df[‘class label’]))}
df[‘class label’] = df[‘class label’].map(class_mapping)
说明:对于有大小意义的离散特征,直接使用映射就可以了,{‘XL’:3,‘L’:2,‘M’:1}
Using the get_dummies will create a new column for every unique string in a certain column:使用get_dummies进行one-hot编码
[python] view plain copy
pd.get_dummies(df)
————————————————
版权声明:本文为CSDN博主「maymay_」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/maymay_/article/details/80198468