prophet 预测销量及参数调整
prophet是一个比较自动的时间序列模型,在时间足够长的情况下,可以捕捉到年周期,月周期,季度周期,一周内的周期等,以及长期趋势,它可以通过图直观地展示各个因素对预测结果的影响,也可以在单一的数据序列(例如销量)之外加入其它影响序列的因素,比如说节日的影响,我们可以给各个节日的影响强度自定义数字,以及节日的前期预热,和节日的延续时间窗
prophet一个重要特性是changepoint,它会自动检测先前固定趋势发生改变的时间点,然后弱化之前对周期的参数设置,例如比较强的年周期,月周期,这时候模型预测的结果会更多考虑近期趋势,changepoint参数设置的越大,模型越灵活地应对近期趋势
prophet对短期预测效果更好,如果要做长期预测,只对周期稳定的数据表现良好,如果销量在去年4-6月是上升趋势,而今年是下降趋势,但是今年4月之前的销量都跟去年差不多,或者近期趋势呈上升状态,它是预测不到4-6月的下降的
下面是最近做的例子,数据是一些产品从18年1月到19年6月的日销量,目的是预测4-6月的总销量,训练数据可以用18年1月开始到19年3月中旬
data_ds.columns = ["ds", "y"]
data_ds["y"] = np.where(data_ds["ds"].isin(holidays_df["ds"].unique()), np.nan, data_ds["y"])
prophet_predict_model = Prophet_Model(data_ds, 2019, 'SU', holidays_df)
prophet_predict_model.train_ds["y"].describe()
m = Prophet(holidays=holidays_df, changepoint_prior_scale=0.08)
m.add_seasonality(name="yearly", period=365, fourier_order=1)
m.add_seasonality(name='quarterly', period=91.5, fourier_order=2)
m.add_seasonality(name='monthly', period=30.5, fourier_order=1)
m.add_seasonality(name='weekly', period=7, fourier_order=2)
m.add_country_holidays(country_name='CN')
m.fit(prophet_predict_model.train_ds)
future = m.make_future_dataframe(periods=len(prophet_predict_model.test_ds)) # concat future dates after history data
forecast = m.predict(future)
compare_result = pd.merge(forecast, prophet_predict_model.test_ds, on="ds")
non_nan_data = compare_result[compare_result["y"].notnull()]
mape = abs(non_nan_data["yhat"].sum() - non_nan_data["y"].sum()) / non_nan_data["y"].sum()
fig1 = m.plot(forecast)
plt.scatter(prophet_predict_model.test_ds["ds"].values, prophet_predict_model.test_ds["y"], c='black', s=5)
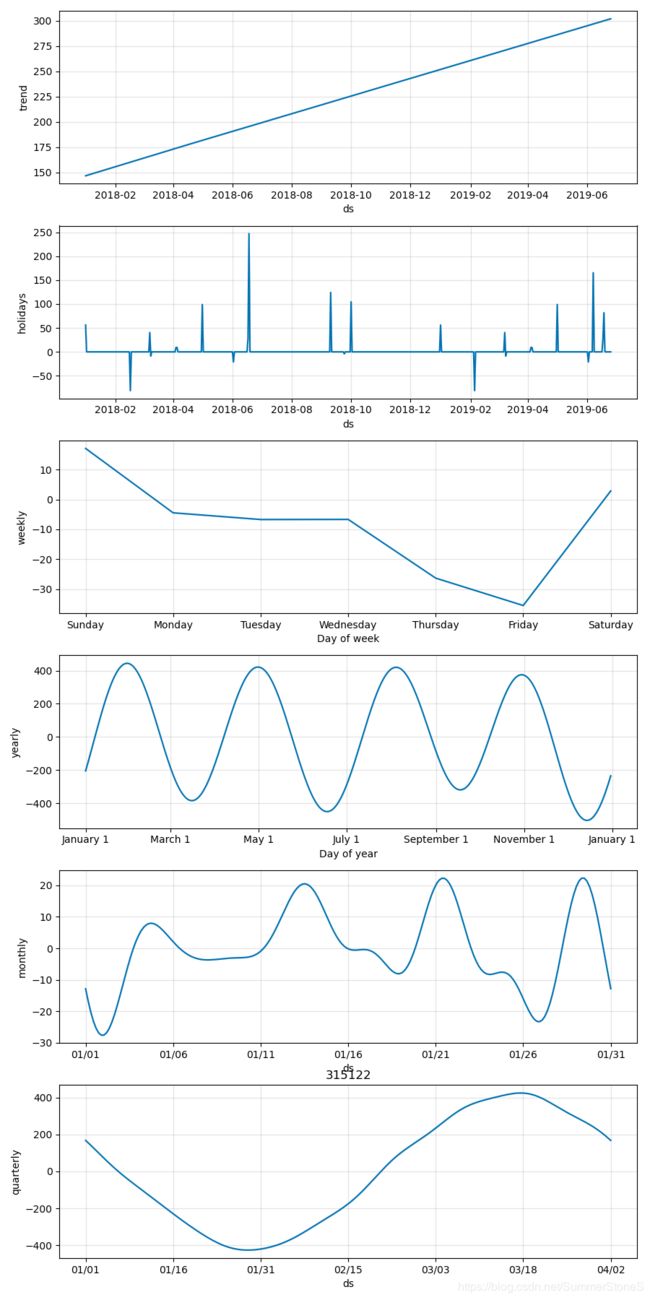
fig2 = m.plot_components(forecast)
plt.show()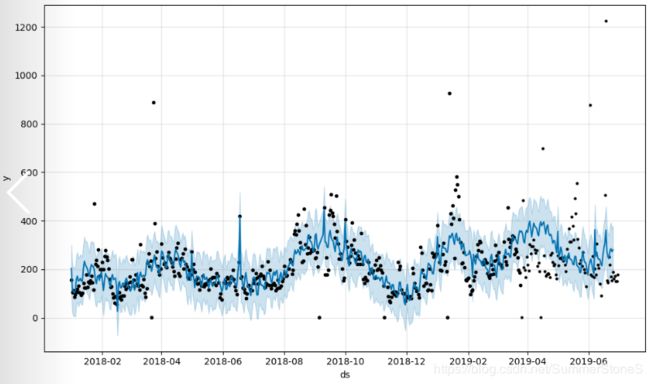
其中一个商品的销量跑完的结果如图所示
由于大促(双十一,618等)销量是日常的十几甚至上百倍,导致trend会把大促的向量上升考虑进来,使得trend在某些时间点(如12月,1月)预测会受到先前大促的影响,变呈强势上升趋势,故而在预测中,把所有大促时间点的销量设置成了缺失值,prophet允许缺失值的存在,它会自动插值;但是由于大促日前后,销量也会有所上升,我并不希望把所有大促日附近的销量都置空,所以大促前后几天我还是添加进了holidays,并设置了holidays effect值
但是固定的参数并不适用所有的产品,有些产品的销量在平时比较稳定,周期性并没有很明显,大促的时候量很大,这样的产品可以弱化周期强度,甚至去掉这个周期作用,比如下面这个产品
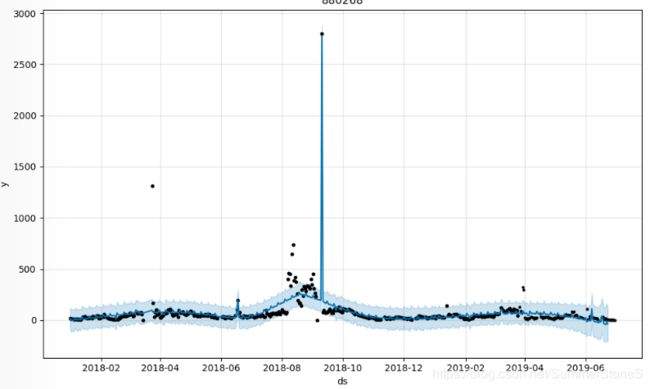
我设置的系数是changepoint_scale=0.08, yearly_seasonality是1,结果如图,trend在6-9月有一个上升, 猜测如果调大holiday effect的系数,是不是不会对trend影响这么大,因为这段时间毕竟还是有一些节日如9.9支撑,以及考虑是不是不光将大促当天设置成缺失值,大促前后也设置成缺失值,如此模型更能捕捉一个正常的周期,然后我们再叠加模型拟合大促的时候销量爆表行为
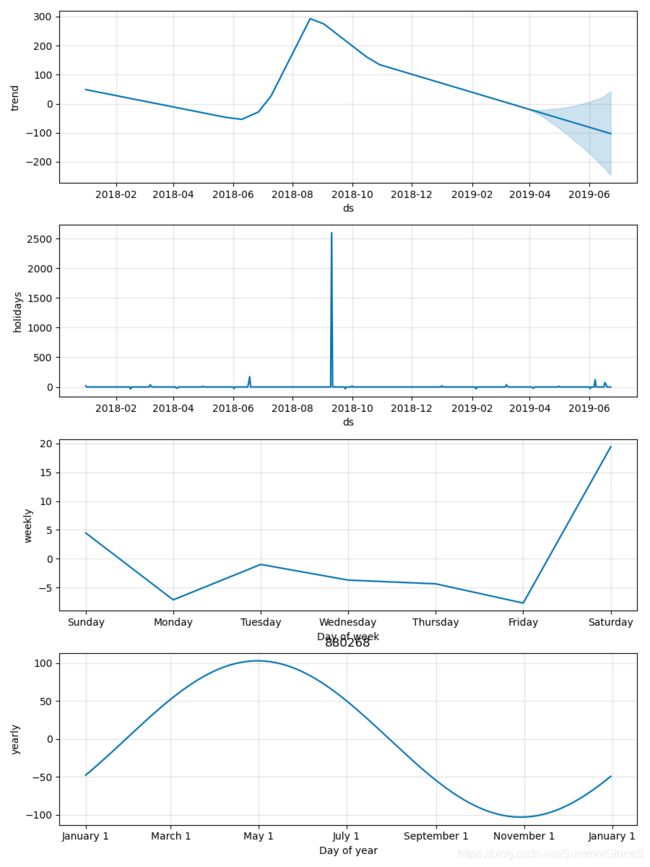
有的产品虽然monthly,weekly作用可能不明显,yearly作用比较显著,但是变化也比较大,这时候需要changepoint_scale适当放大,比如上面的模型对下面这个产品就没有那么适用

我们能看到它过度的捕捉了18年5-7月的上升趋势,忽略了3月下降的趋势,于是我把changepoint_scale调成0.5,yearly_seasonlity还保持1,就会变成如下,能看到模型更能应对近期发生的下降趋势,而不是过度捕捉yearly seasonality
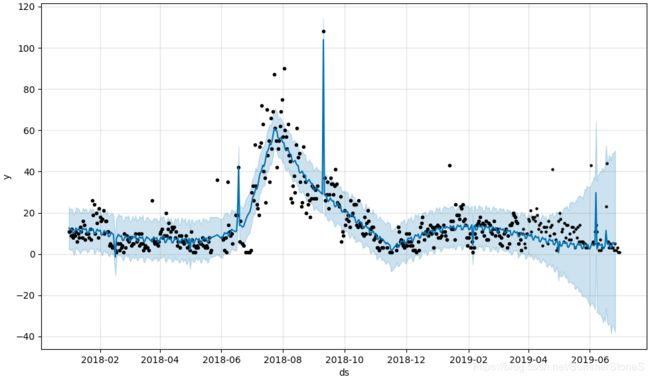
由于在预测的时候事先并不知道用什么样的参数能使4-6月你的预测结果比较好,比较直接的想法是如果有18年19年两年的数据,对20年4-6月做预测,似乎比较合理的做法是用对19年4-6月的预测做训练,找到合适的参数,但是现在目标是预测19年的4-6月,3月份因为有3.8大促,导致销量偏高,所以我尝试了用19年1月或2月,或19年1-3月三种情况,做训练找到最优参数组合,对4-6月做预测。结论是单用1月的效果比较好,2月和3月一个有过年,一个有3.8,似乎都加入了过强的扰动。不过即使用1月的做训练,也有一些产品效果不理想,一方面1月的拟合效果好,不一定4-6月效果好,毕竟4-6月有三个月,其中又有两个大促6.1,6.18,另外,有的产品去年4-6月的走势和19年4-6月的走势可能完全不一样,比如下面这个产品
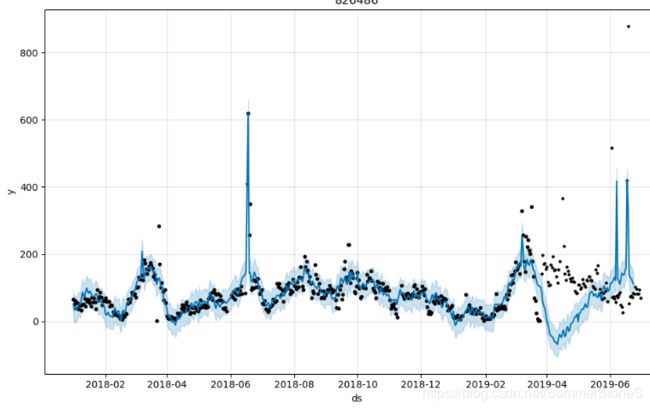
18年的4-6月这个产品是上升趋势,而19年是下降趋势,模型考虑了19年3月中下旬的下降趋势,但它依然认定4-6月的周期是保持去年的走势,对于这种情况,暂时还没有想到很好的处理办法
最后一个问题,对于这么多产品,如何自动调参,一种方法是grid search, 把每种参数组合都放进模型训练,这样可能很慢,而且过拟合也比较严重,试了一下最后发现效率太低下,而且也没有比另一种方法好多少(真的慢了太多,但因为每个产品需要的参数range真的差很多,这是前期通过对某些产品反复调试发现的,并不能太narrow这些参数的range或者step)
import itertools
parameters = {
"changepoint_prior_scale": list(np.arange(0.05, 8, 0.5)),
"weekly_order": list(np.arange(8, 0, -1)),
"monthly_order": list(np.arange(8, 0, -1)),
"quarterly_order": list(np.arange(8, 0, -1)),
"yearly_order": list(np.arange(8, 0, -1))
}
names = parameters.keys()
setups = itertools.product(*parameters.values())
for setup in setups:
data = dict(zip(names, setup))另一种方法是,考虑每个参数对模型结果得影响是线性的,只要这个参数变大了,对模型的结果没有正影响, 就调整下一个参数
class Searcher:
def __init__(self, parameters):
self.names = parameters.keys()
self.setups = [list(param) for param in parameters.values()]
self.i = len(self.setups) - 1 # refer to which param, starting from the last param
self.j = 0 # refer to which value of param i
self.best_mape = float("inf")
self.best_params = None
self.last_mape = 10000000000
def run(self):
current_setup = [s[0] for s in self.setups]
# while self.best_mape > 0.1:
while self.best_mape > 0.001:
if self.i >= 0 and self.j >= len(self.setups[self.i]): # all values of this param have been tried
self.j = 1
self.i -= 1
if self.i < 0: # no param could adjust
break
current_setup[self.i] = self.setups[self.i][self.j]
params = dict(zip(self.names, current_setup))
print(params, self.i, self.j)
mape = self.func(**params)
# prophet_search_model.build_prophet(**params)
# _, sn_performance_result = prophet_search_model.compare_result()
# mape = sn_performance_result[2]
print(f"mape: {mape}")
if mape < self.best_mape:
self.best_mape = mape
self.best_params = params
# if mape > self.last_mape*1.2 and self.i > 0: # leave changepoint full grid search
if mape > self.last_mape*1.2: # cp_cut, consider all parameter is linear correlated with mape
self.i -= 1
self.j = 1
continue
self.last_mape = mape
self.j += 1
print(self.best_mape, self.best_params)
## Usage:
class MySearcher(Searcher):
def __init__(self, prophet_model, parameters):
super().__init__(parameters)
self.model = prophet_model
def func(self, **params): # minimize loss func
self.model.build_prophet(**params)
predict_result, sn_performance_result = self.model.compare_result()
mape = sn_performance_result[2]
return mape
class MySearcher_simple(Searcher):
def __init__(self, prophet_model, parameters):
super().__init__(parameters)
self.model = prophet_model
def func(self, **params): # minimize loss func
self.model.build_auto_prophet(**params)
predict_result, sn_performance_result = self.model.compare_result()
mape = sn_performance_result[2]
return mape这里每个产品1月份预测总量和实际的总量的MAPE是我的evaluation metric, 只要一个参数往大调一次,mape没有比前一次变好20%,我就认为这个参数可以不用再调了,开始调下一个参数, 因为有些产品周期性强,有些产品周期性弱,所以我设了两种模型,一种是有monthly seasonality,quarterly seasonality和weekly seasonality的,一种是只有yearly的
关于如何确定什么产品适合什么模型配置,通过观察,发现日常销量本身就比较大(每天有近百、几百的),周期性作用比较强,用第一种模型的参数配置;对于日常销量比较小(每天少于50)大促的时候销量可能是平时的600倍+,甚至1400多倍的,这种用第二个模型,只考虑yearly seasonality和changepoint_scale; 对于第二类仔细观察其实也能分成两种情况,一种情况是平时波动比较大(用变异系数和max_over_min来区分),changepoint_scale可以一开始就设的较大,我设的是和yearly_seasonality的scale一样大,另一种情况是日常没什么波动,changepoint就从一个较小的取值开始,最后让所有产品通过自动化寻参取得较好的综合表现