爬取猫眼 TOP100 电影并以 excel 格式存储
爬取目标
本文将提取猫眼电影 TOP100 排行榜的电影名称、时间、评分、图片等信息,URL 为http://maoyan.com/board/4,提取的结果我们以 excel 格式保存下来。
准备工作
保证电脑安装了 python3.6 和已经安装好了 requests 库、beautifulsoup 库和 openpyxl 库。
前期安装步骤可以参考:https://germey.gitbooks.io/python3webspider/1-%E5%BC%80%E5%8F%91%E7%8E%AF%E5%A2%83%E9%85%8D%E7%BD%AE.html
爬取分析
打开http://maoyan.com/board/4我们会发现榜单主要显示 4 个数据:电影名、主演、上映时间和评分。
如图所示: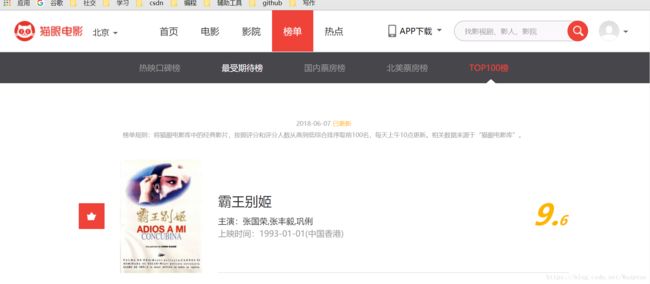
网页下滑到最下方可以发现有分页的列表,我们点击一下第二页会发现页面的 URL 变成了http://maoyan.com/board/4?offset=10,比之前的页面多了一个 offset=10 的参数,而且页面显示的是排行 11-20 名的电影。
由此我们可以总结出规律,offset 代表了一个偏移量值,如果偏移量为 n,则显示的电影序号就是 n+1 到 n+10,每页显示 10 个。所以我们如果想获取 TOP100 电影,只需要分开请求 10 次,而 10 次的 offset 参数设置为 0,10,20,…,90 即可,这样我们获取不同的页面结果之后再用正则表达式提取出相关信息就可以得到 TOP100 的所有电影信息了。
抓取首页
import requests
def get_one_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
def main():
url = 'http://maoyan.com/board/4'
html = get_one_page(url)
print(html)
main()这样我们就可以获取首页的源代码了,获取源代码之后我们要对页面进行解析,提取出我们想要的信息。
使用 BeautifulSoup 进行提取
接下来我们回到网页看一下页面的真实源码,在开发者工具中 Network 监听(建议使用谷歌浏览器,按 F12 即可查看网页信息),然后查看一下源代码。如图所示: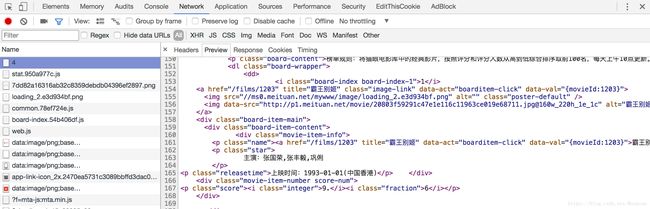
注意这里不要在 Elements 选项卡直接查看源码,此处的源码可能经过 JavaScript 的操作而和原始请求的不同,我们需要从Network选项卡部分查看原始请求得到的源码。
查看其中的一条源代码如图所示:
可以看到电影名、主演、上映时间和评分分别在属性 class=”name”、class=”star”、class=”release” 和 class=”score”的文本中
那么我们可以用 BeautifulSoup 的方法进行提取:
def parse_one_page(html):
soup = bs4.BeautifulSoup(html, 'lxml')
# 获取电影名
movies = []
targets = soup.find_all(class_='name')
for each in targets:
movies.append(each.get_text())
# 获取评分
scores = []
targets = soup.find_all(class_='score')
for each in targets:
scores.append(each.get_text())
# 获取主演信息
star_message = []
targets = soup.find_all(class_='star')
for each in targets:
star_message.append(each.get_text().split('\n')[1].strip())
print(each.get_text().split('\n')[1].strip())
# 获取上映时间
play_time = []
targets = soup.find_all(class_='releasetime')
for each in targets:
play_time.append(each.get_text())
result = []
length = len(movies)
for j in range(length):
result.append([movies[j], scores[j], star_message[j], play_time[j]])
return result这样我们就成功的将一页的 10 个电影信息都提取出来了
写入文件
随后我们将提取的结果做成 excel 表格形式
def save_to_excel(result):
wb = openpyxl.Workbook()
ws = wb.active
ws['A1'] = '电影名称'
ws['B1'] = '评分'
ws['C1'] = '主演'
ws['D1'] = '上映时间'
for item in result:
ws.append(item)
wb.save('猫眼电影TOP100.xlsx')分页爬取
但我们需要爬取的数据是 TOP100 的电影,所以我们还需要遍历一下给这个链接传入一个 offset 参数,实现其他 90 部电影的爬取
for i in range(10):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
}
url = 'http://maoyan.com/board/4?offset=' + str(i * 10)
html = get_one_page(url, headers)
result.extend(parse_one_page(html))整合代码
到此为止,我们的猫眼电影 TOP100 的爬虫就全部完成了,再稍微整理一下,完整的代码如下:
import requests
import bs4
from requests.exceptions import RequestException
import openpyxl
def get_one_page(url, headers):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
soup = bs4.BeautifulSoup(html, 'lxml')
# 获取电影名
movies = []
targets = soup.find_all(class_='name')
for each in targets:
movies.append(each.get_text())
# 获取评分
scores = []
targets = soup.find_all(class_='score')
for each in targets:
scores.append(each.get_text())
# 获取主演信息
star_message = []
targets = soup.find_all(class_='star')
for each in targets:
star_message.append(each.get_text().split('\n')[1].strip())
print(each.get_text().split('\n')[1].strip())
# 获取上映时间
play_time = []
targets = soup.find_all(class_='releasetime')
for each in targets:
play_time.append(each.get_text())
result = []
length = len(movies)
for j in range(length):
result.append([movies[j], scores[j], star_message[j], play_time[j]])
return result
def save_to_excel(result):
wb = openpyxl.Workbook()
ws = wb.active
ws['A1'] = '电影名称'
ws['B1'] = '评分'
ws['C1'] = '主演'
ws['D1'] = '上映时间'
for item in result:
ws.append(item)
wb.save('猫眼电影TOP100.xlsx')
def main():
result = []
for i in range(10):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
}
url = 'http://maoyan.com/board/4?offset=' + str(i * 10)
html = get_one_page(url, headers)
result.extend(parse_one_page(html))
save_to_excel(result)
if __name__ == '__main__':
main()运行结果如下图:

结语
本文参考崔庆才的《Python3 网络爬虫开发实战》代码部分将正则表达式解析换成 BeautifulSoup 解析。
本代码还有改进的地方,比如解析代码时有些代码重复了,使用的单进程爬取速度较慢,最近 requests 的作者新开发了一个库 request-html,集网页获取与解析与一体,使爬取更简单。有兴趣的可以看看官方文档传送门。希望大家多多交流。