分布式作业系统 Elastic-Job-Lite 源码分析 —— 作业执行
点击上方“芋道源码”,选择“置顶公众号”
技术文章第一时间送达!
源码精品专栏
精尽 Dubbo 原理与源码专栏( 已经完成 69+ 篇,预计总共 75+ 篇 )
中文详细注释的开源项目
Java 并发源码合集
RocketMQ 源码合集
Sharding-JDBC 源码解析合集
Spring MVC 和 Security 源码合集
MyCAT 源码解析合集
摘要: 原创出处 http://www.iocoder.cn/Elastic-Job/job-execute/ 「芋道源码」欢迎转载,保留摘要,谢谢!
本文基于 Elastic-Job V2.1.5 版本分享
1. 概述
2. Lite调度作业
3. 执行器创建
4. 执行器执行
666. 彩蛋
1. 概述
本文主要分享 Elastic-Job-Lite 作业执行。
涉及到主要类的类图如下( 打开大图 ):
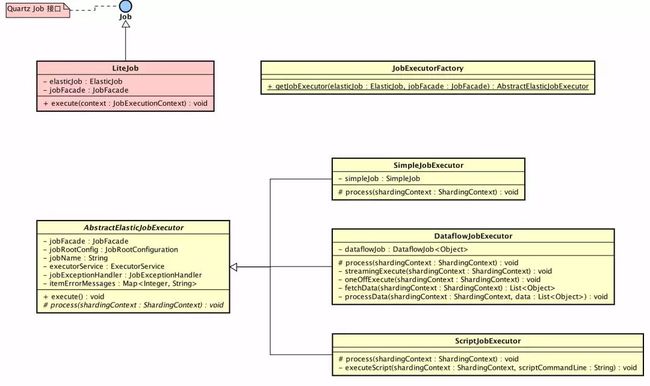
黄色的类在
elastic-job-common-core项目里,为 Elastic-Job-Lite、Elastic-Job-Cloud 公用作业执行类。
你行好事会因为得到赞赏而愉悦
同理,开源项目贡献者会因为 Star 而更加有动力
为 Elastic-Job 点赞!传送门
2. Lite调度作业
Lite调度作业( LiteJob ),作业被调度后,调用 #execute() 执行作业。
为什么是 LiteJob 作为入口呢?
在《Elastic-Job-Lite 源码分析 —— 作业初始化》的「3.2.3」创建作业调度控制器里,我们可以看到 Quartz 的 JobDetail 创建代码如下:
JobDetail result = JobBuilder.newJob(LiteJob.class).withIdentity(liteJobConfig.getJobName()).build();
#newJob() 里的参数是 LiteJob,因此,每次 Quartz 到达调度时间时,会创建该对象进行作业执行。
public final class LiteJob implements Job {
@Setter
private ElasticJob elasticJob;
@Setter
private JobFacade jobFacade;
@Override
public void execute(final JobExecutionContext context) throws JobExecutionException {
JobExecutorFactory.getJobExecutor(elasticJob, jobFacade).execute();
}
}
LiteJob 通过 JobExecutorFactory 获得到作业执行器( AbstractElasticJobExecutor ),并进行执行:
public final class JobExecutorFactory {/**
* 获取作业执行器.
*
* @param elasticJob 分布式弹性作业
* @param jobFacade 作业内部服务门面服务
* @return 作业执行器
*/
@SuppressWarnings("unchecked")
public static AbstractElasticJobExecutor getJobExecutor(final ElasticJob elasticJob, final JobFacade jobFacade) {
// ScriptJob
if (null == elasticJob) {
return new ScriptJobExecutor(jobFacade);
}
// SimpleJob
if (elasticJob instanceof SimpleJob) {
return new SimpleJobExecutor((SimpleJob) elasticJob, jobFacade);
}
// DataflowJob
if (elasticJob instanceof DataflowJob) {
return new DataflowJobExecutor((DataflowJob) elasticJob, jobFacade);
}
throw new JobConfigurationException("Cannot support job type '%s'", elasticJob.getClass().getCanonicalName());
}}JobExecutorFactory,作业执行器工厂,根据不同的作业类型,返回对应的作业执行器。
| 作业 | 作业接口 | 执行器 |
|---|---|---|
| 简单作业 | SimpleJob | SimpleJobExecutor |
| 数据流作业 | DataflowJob | DataflowJobExecutor |
| 脚本作业 | ScriptJob | ScriptJobExecutor |
3. 执行器创建
AbstractElasticJobExecutor,作业执行器抽象类。不同作业执行器都继承该类,创建的过程是一致的。
// AbstractElasticJobExecutor.java
public abstract class AbstractElasticJobExecutor {
/**
* 作业门面对象
*/
@Getter(AccessLevel.PROTECTED)
private final JobFacade jobFacade;
/**
* 作业配置
*/
@Getter(AccessLevel.PROTECTED)
private final JobRootConfiguration jobRootConfig;
/**
* 作业名称
*/
private final String jobName;
/**
* 作业执行线程池
*/
private final ExecutorService executorService;
/**
* 作业异常处理器
*/
private final JobExceptionHandler jobExceptionHandler;
/**
* 分片错误信息集合
* key:分片序号
*/
private final Map itemErrorMessages;
protected AbstractElasticJobExecutor(final JobFacade jobFacade) {
this.jobFacade = jobFacade;
// 加载 作业配置
jobRootConfig = jobFacade.loadJobRootConfiguration(true);
jobName = jobRootConfig.getTypeConfig().getCoreConfig().getJobName();
// 获取 作业执行线程池
executorService = ExecutorServiceHandlerRegistry.getExecutorServiceHandler(jobName, (ExecutorServiceHandler) getHandler(JobProperties.JobPropertiesEnum.EXECUTOR_SERVICE_HANDLER));
// 获取 作业异常处理器
jobExceptionHandler = (JobExceptionHandler) getHandler(JobProperties.JobPropertiesEnum.JOB_EXCEPTION_HANDLER);
// 设置 分片错误信息集合
itemErrorMessages = new ConcurrentHashMap<>(jobRootConfig.getTypeConfig().getCoreConfig().getShardingTotalCount(), 1);
}
}
// SimpleJobExecutor.java
public final class SimpleJobExecutor extends AbstractElasticJobExecutor {
/**
* 简单作业实现
*/
private final SimpleJob simpleJob;
public SimpleJobExecutor(final SimpleJob simpleJob, final JobFacade jobFacade) {
super(jobFacade);
this.simpleJob = simpleJob;
}
}
// DataflowJobExecutor.java
public final class DataflowJobExecutor extends AbstractElasticJobExecutor {
/**
* 数据流作业对象
*/
private final DataflowJob 3.1 加载作业配置
从缓存中读取作业配置。在《Elastic-Job-Lite 源码分析 —— 作业配置》的「3.1」读取作业配置 已经解析。
3.2 获取作业执行线程池
作业每次执行时,可能分配到多个分片项,需要使用线程池实现并行执行。考虑到不同作业之间的隔离性,通过一个作业一个线程池实现。线程池服务处理器注册表( ExecutorServiceHandlerRegistry ) 获取作业线程池( #getExecutorServiceHandler(....) )代码如下:
public final class ExecutorServiceHandlerRegistry {
/**
* 线程池集合
* key:作业名字
*/
private static final Map REGISTRY = new HashMap<>();
/**
* 获取线程池服务.
*
* @param jobName 作业名称
* @param executorServiceHandler 线程池服务处理器
* @return 线程池服务
*/
public static synchronized ExecutorService getExecutorServiceHandler(final String jobName, final ExecutorServiceHandler executorServiceHandler) {
if (!REGISTRY.containsKey(jobName)) {
REGISTRY.put(jobName, executorServiceHandler.createExecutorService(jobName));
}
return REGISTRY.get(jobName);
}
}
ExecutorServiceHandlerRegistry 使用 ExecutorServiceHandler 创建线程池。ExecutorServiceHandler 本身是个接口,默认使用 DefaultExecutorServiceHandler 实现:
// ExecutorServiceHandler.java
public interface ExecutorServiceHandler {
/**
* 创建线程池服务对象.
*
* @param jobName 作业名
*
* @return 线程池服务对象
*/
ExecutorService createExecutorService(final String jobName);
}
// DefaultExecutorServiceHandler.java
public final class DefaultExecutorServiceHandler implements ExecutorServiceHandler {
@Override
public ExecutorService createExecutorService(final String jobName) {
return new ExecutorServiceObject("inner-job-" + jobName, Runtime.getRuntime().availableProcessors() * 2).createExecutorService();
}
}
调用 ExecutorServiceObject 的
#createExecutorService(....)方法创建线程池:public final class ExecutorServiceObject {private final ThreadPoolExecutor threadPoolExecutor;
private final BlockingQueue<Runnable> workQueue;
public ExecutorServiceObject(final String namingPattern, final int threadSize) {
workQueue = new LinkedBlockingQueue<>();
threadPoolExecutor = new ThreadPoolExecutor(threadSize, threadSize, 5L, TimeUnit.MINUTES, workQueue,
new BasicThreadFactory.Builder().namingPattern(Joiner.on("-").join(namingPattern, "%s")).build());
threadPoolExecutor.allowCoreThreadTimeOut(true);
}
/**
* 创建线程池服务对象.
*
* @return 线程池服务对象
*/
public ExecutorService createExecutorService() {
return MoreExecutors.listeningDecorator(MoreExecutors.getExitingExecutorService(threadPoolExecutor));
}}service.shutdown();
service.awaitTermination(terminationTimeout, timeUnit);MoreExecutors#listeningDecorator(…)在《Sharding-JDBC 源码分析 —— SQL 执行》 已经解析。MoreExecutors#getExitingExecutorService(…)方法逻辑:将 ThreadPoolExecutor 转换成 ExecutorService,并增加 JVM 关闭钩子,实现 120s 等待任务完成:
如何实现自定义 ExecutorServiceHandler ?
先看下 AbstractElasticJobExecutor 是如何获得每个作业的 ExecutorServiceHandler :
// AbstractElasticJobExecutor.java
/**
* 获得【自定义】处理器
*
* @param jobPropertiesEnum 作业属性枚举
* @return 处理器
*/
private Object getHandler(final JobProperties.JobPropertiesEnum jobPropertiesEnum) {
String handlerClassName = jobRootConfig.getTypeConfig().getCoreConfig().getJobProperties().get(jobPropertiesEnum);
try {
Class handlerClass = Class.forName(handlerClassName);
if (jobPropertiesEnum.getClassType().isAssignableFrom(handlerClass)) { // 必须是接口实现,才使用【自定义】
return handlerClass.newInstance();
}
return getDefaultHandler(jobPropertiesEnum, handlerClassName);
} catch (final ReflectiveOperationException ex) {
return getDefaultHandler(jobPropertiesEnum, handlerClassName);
}
}
/**
* 获得【默认】处理器
*
* @param jobPropertiesEnum 作业属性枚举
* @param handlerClassName 处理器类名
* @return 处理器
*/
private Object getDefaultHandler(final JobProperties.JobPropertiesEnum jobPropertiesEnum, final String handlerClassName) {
log.warn("Cannot instantiation class '{}', use default '{}' class.", handlerClassName, jobPropertiesEnum.getKey());
try {
return Class.forName(jobPropertiesEnum.getDefaultValue()).newInstance();
} catch (final ClassNotFoundException | InstantiationException | IllegalAccessException e) {
throw new JobSystemException(e);
}
}
每个处理器都会对应一个 JobPropertiesEnum,使用枚举获得处理器。优先从
JobProperties.map获取自定义的处理器实现类,如果不符合条件( 未实现正确接口 或者 创建处理器失败 ),使用默认的处理器实现。每个作业可以配置不同的处理器,在《Elastic-Job-Lite 源码分析 —— 作业配置》的「2.2.2」作业核心配置已经解析。
3.3 获取作业异常执行器
获取作业异常执行器( JobExceptionHandler )和 ExecutorServiceHandler( ExecutorServiceHandler )相同。
// ExecutorServiceHandler.java
public interface JobExceptionHandler {
/**
* 处理作业异常.
*
* @param jobName 作业名称
* @param cause 异常原因
*/
void handleException(String jobName, Throwable cause);
}
// DefaultJobExceptionHandler.java
public final class DefaultJobExceptionHandler implements JobExceptionHandler {
@Override
public void handleException(final String jobName, final Throwable cause) {
log.error(String.format("Job '%s' exception occur in job processing", jobName), cause);
}
}
默认实现 DefaultJobExceptionHandler 打印异常日志,不会抛出异常。
4. 执行器执行
执行逻辑主流程如下图( 打开大图 ):
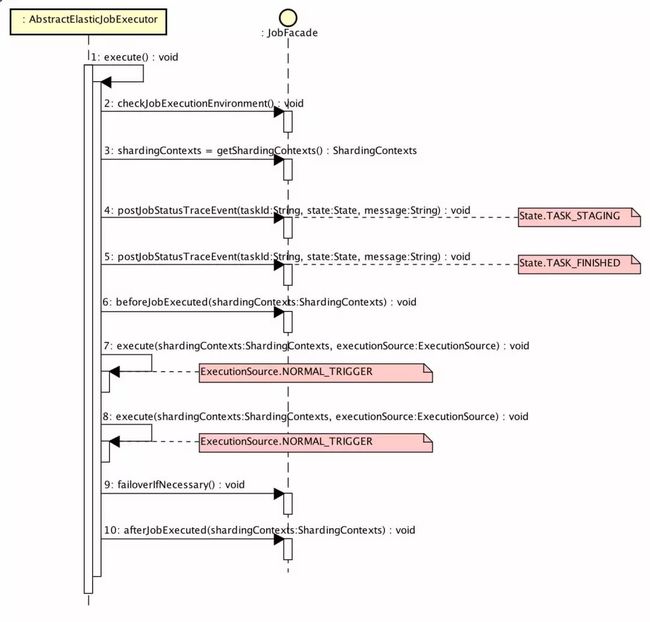
// AbstractElasticJobExecutor.java
public final void execute() {
// 检查 作业执行环境
try {
jobFacade.checkJobExecutionEnvironment();
} catch (final JobExecutionEnvironmentException cause) {
jobExceptionHandler.handleException(jobName, cause);
}
// 获取 当前作业服务器的分片上下文
ShardingContexts shardingContexts = jobFacade.getShardingContexts();
// 发布作业状态追踪事件(State.TASK_STAGING)
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_STAGING, String.format("Job '%s' execute begin.", jobName));
}
// 跳过 存在运行中的被错过作业
if (jobFacade.misfireIfRunning(shardingContexts.getShardingItemParameters().keySet())) {
// 发布作业状态追踪事件(State.TASK_FINISHED)
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_FINISHED, String.format(
"Previous job '%s' - shardingItems '%s' is still running, misfired job will start after previous job completed.", jobName,
shardingContexts.getShardingItemParameters().keySet()));
}
return;
}
// 执行 作业执行前的方法
try {
jobFacade.beforeJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
// 执行 普通触发的作业
execute(shardingContexts, JobExecutionEvent.ExecutionSource.NORMAL_TRIGGER);
// 执行 被跳过触发的作业
while (jobFacade.isExecuteMisfired(shardingContexts.getShardingItemParameters().keySet())) {
jobFacade.clearMisfire(shardingContexts.getShardingItemParameters().keySet());
execute(shardingContexts, JobExecutionEvent.ExecutionSource.MISFIRE);
}
// 执行 作业失效转移
jobFacade.failoverIfNecessary();
// 执行 作业执行后的方法
try {
jobFacade.afterJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
}
代码步骤比较多,我们一步一步往下看。
4.1 检查作业执行环境
// LiteJobFacade.java
@Override
public void checkJobExecutionEnvironment() throws JobExecutionEnvironmentException {
configService.checkMaxTimeDiffSecondsTolerable();
}
调用
ConfigService#checkMaxTimeDiffSecondsTolerable()方法校验本机时间是否合法,在《Elastic-Job-Lite 源码分析 —— 作业配置》的「3.3」校验本机时间是否合法 已经解析。当校验本机时间不合法时,抛出异常。若使用 DefaultJobExceptionHandler 作为异常处理,只打印日志,不会终止作业执行。如果你的作业对时间精准度有比较高的要求,期望作业终止执行,可以自定义 JobExceptionHandler 实现对异常的处理。
4.2 获取当前作业服务器的分片上下文
调用 LiteJobFacade#getShardingContexts() 方法获取当前作业服务器的分片上下文。通过这个方法,作业获得其所分配执行的分片项,在《Elastic-Job-Lite 源码解析 —— 作业分片》详细分享。
4.3 发布作业状态追踪事件
调用 LiteJobFacade#postJobStatusTraceEvent() 方法发布作业状态追踪事件,在《Elastic-Job-Lite 源码解析 —— 作业事件追踪》详细分享。
4.4 跳过正在运行中的被错过执行的作业
该逻辑和「4.7」执行被错过执行的作业,一起解析,可以整体性的理解 Elastic-Job-Lite 对被错过执行( misfired )的作业处理。
4.5 执行作业执行前的方法
// LiteJobFacade.java
@Override
public void beforeJobExecuted(final ShardingContexts shardingContexts) {
for (ElasticJobListener each : elasticJobListeners) {
each.beforeJobExecuted(shardingContexts);
}
}
调用作业监听器执行作业执行前的方法,在《Elastic-Job-Lite 源码解析 —— 作业监听器》详细分享。
4.6 执行普通触发的作业
这个小节的标题不太准确,其他作业来源( ExecutionSource )也是执行这样的逻辑。本小节执行作业会经历 4 个方法,方法顺序往下调用,我们逐个来看。
// AbstractElasticJobExecutor.java
/**
* 执行多个作业的分片
*
* @param shardingContexts 分片上下文集合
* @param executionSource 执行来源
*/
private void execute(final ShardingContexts shardingContexts, final JobExecutionEvent.ExecutionSource executionSource) {
}
/**
* 执行多个作业的分片
*
* @param shardingContexts 分片上下文集合
* @param executionSource 执行来源
*/
private void process(final ShardingContexts shardingContexts, final JobExecutionEvent.ExecutionSource executionSource) {
}
/**
* 执行单个作业的分片
*
* @param shardingContexts 分片上下文集合
* @param item 分片序号
* @param startEvent 执行事件(开始)
*/
private void process(final ShardingContexts shardingContexts, final int item, final JobExecutionEvent startEvent) {
}
/**
* 执行单个作业的分片【子类实现】
*
* @param shardingContext 分片上下文集合
*/
protected abstract void process(ShardingContext shardingContext);
ps:作业事件相关逻辑,先统一跳过,在《Elastic-Job-Lite 源码解析 —— 作业事件追踪》详细分享。
private void execute(shardingContexts, executionSource)
// AbstractElasticJobExecutor.java
private void execute(final ShardingContexts shardingContexts, final JobExecutionEvent.ExecutionSource executionSource) {
// 无可执行的分片,发布作业状态追踪事件(State.TASK_FINISHED)
if (shardingContexts.getShardingItemParameters().isEmpty()) {
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_FINISHED, String.format("Sharding item for job '%s' is empty.", jobName));
}
return;
}
// 注册作业启动信息
jobFacade.registerJobBegin(shardingContexts);
// 发布作业状态追踪事件(State.TASK_RUNNING)
String taskId = shardingContexts.getTaskId();
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(taskId, State.TASK_RUNNING, "");
}
//
try {
process(shardingContexts, executionSource);
} finally {
// TODO 考虑增加作业失败的状态,并且考虑如何处理作业失败的整体回路
// 注册作业完成信息
jobFacade.registerJobCompleted(shardingContexts);
// 根据是否有异常,发布作业状态追踪事件(State.TASK_FINISHED / State.TASK_ERROR)
if (itemErrorMessages.isEmpty()) {
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(taskId, State.TASK_FINISHED, "");
}
} else {
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(taskId, State.TASK_ERROR, itemErrorMessages.toString());
}
}
}
}
方法参数
executionSource代表执行来源( ExecutionSource ),一共有三种:public enum ExecutionSource {
/**
* 普通触发执行
*/
NORMAL_TRIGGER,
/**
* 被错过执行
*/
MISFIRE,
/**
* 失效转移执行
*/
FAILOVER
}调用
LiteJobFacade#registerJobBegin(...)方法注册作业启动信息:// LiteJobFacade.java
@Override
public void registerJobBegin(final ShardingContexts shardingContexts) {
executionService.registerJobBegin(shardingContexts);
}
// ExecutionService.java
public void registerJobBegin(final ShardingContexts shardingContexts) {
JobRegistry.getInstance().setJobRunning(jobName, true);
if (!configService.load(true).isMonitorExecution()) {
return;
}
for (int each : shardingContexts.getShardingItemParameters().keySet()) {
jobNodeStorage.fillEphemeralJobNode(ShardingNode.getRunningNode(each), "");
}
}仅当作业配置设置监控作业运行时状态(
LiteJobConfiguration.monitorExecution = true)时,记录作业运行状态。调用
JobNodeStorage#fillEphemeralJobNode(…)方法记录分配的作业分片项正在运行中。如何记录的,在《Elastic-Job-Lite 源码解析 —— 作业数据存储》详细分享。
调用
LiteJobFacade#registerJobCompleted(...)方法注册作业完成信息:// LiteJobFacade.java
@Override
public void registerJobCompleted(final ShardingContexts shardingContexts) {
executionService.registerJobCompleted(shardingContexts);
if (configService.load(true).isFailover()) {
failoverService.updateFailoverComplete(shardingContexts.getShardingItemParameters().keySet());
}
}
// ExecutionService.java
/**
* 注册作业完成信息.
*
* @param shardingContexts 分片上下文
*/
public void registerJobCompleted(final ShardingContexts shardingContexts) {
JobRegistry.getInstance().setJobRunning(jobName, false);
if (!configService.load(true).isMonitorExecution()) {
return;
}
for (int each : shardingContexts.getShardingItemParameters().keySet()) {
jobNodeStorage.removeJobNodeIfExisted(ShardingNode.getRunningNode(each));
}
}仅当作业配置设置监控作业运行时状态(
LiteJobConfiguration.monitorExecution = true),移除作业运行状态。调用
JobNodeStorage#removeJobNodeIfExisted(…)方法移除分配的作业分片项正在运行中的标记,表示作业分片项不在运行中状态。调用
FailoverService#updateFailoverComplete(…)方法更新执行完毕失效转移的分片项状态,在《Elastic-Job-Lite 源码解析 —— 作业失效转移》详细分享。
private void process(shardingContexts, executionSource)
// AbstractElasticJobExecutor.java
private void process(final ShardingContexts shardingContexts, final JobExecutionEvent.ExecutionSource executionSource) {
Collection items = shardingContexts.getShardingItemParameters().keySet();
// 单分片,直接执行
if (1 == items.size()) {
int item = shardingContexts.getShardingItemParameters().keySet().iterator().next();
JobExecutionEvent jobExecutionEvent = new JobExecutionEvent(shardingContexts.getTaskId(), jobName, executionSource, item);
// 执行一个作业
process(shardingContexts, item, jobExecutionEvent);
return;
}
// 多分片,并行执行
final CountDownLatch latch = new CountDownLatch(items.size());
for (final int each : items) {
final JobExecutionEvent jobExecutionEvent = new JobExecutionEvent(shardingContexts.getTaskId(), jobName, executionSource, each);
if (executorService.isShutdown()) {
return;
}
executorService.submit(new Runnable() {
@Override
public void run() {
try {
// 执行一个作业
process(shardingContexts, each, jobExecutionEvent);
} finally {
latch.countDown();
}
}
});
}
// 等待多分片全部完成
try {
latch.await();
} catch (final InterruptedException ex) {
Thread.currentThread().interrupt();
}
}
分配单分片项时,直接执行,无需使用线程池,性能更优。
分配多分片项时,使用线程池并发执行,通过 CountDownLatch 实现等待分片项全部执行完成。
private void process(shardingContexts, item, startEvent)
protected abstract void process(shardingContext)
// AbstractElasticJobExecutor.java
private void process(final ShardingContexts shardingContexts, final int item, final JobExecutionEvent startEvent) {
// 发布执行事件(开始)
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobExecutionEvent(startEvent);
}
log.trace("Job '{}' executing, item is: '{}'.", jobName, item);
JobExecutionEvent completeEvent;
try {
// 执行单个作业
process(new ShardingContext(shardingContexts, item));
// 发布执行事件(成功)
completeEvent = startEvent.executionSuccess();
log.trace("Job '{}' executed, item is: '{}'.", jobName, item);
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobExecutionEvent(completeEvent);
}
// CHECKSTYLE:OFF
} catch (final Throwable cause) {
// CHECKSTYLE:ON
// 发布执行事件(失败)
completeEvent = startEvent.executionFailure(cause);
jobFacade.postJobExecutionEvent(completeEvent);
// 设置该分片执行异常信息
itemErrorMessages.put(item, ExceptionUtil.transform(cause));
//
jobExceptionHandler.handleException(jobName, cause);
}
}
protected abstract void process(ShardingContext shardingContext);
不同作业执行器实现类通过实现
#process(shardingContext)抽象方法,实现对单个分片项作业的处理。不同作业执行器实现类通过实现
#process(shardingContext)抽象方法,实现对单个分片项作业的处理。不同作业执行器实现类通过实现
#process(shardingContext)抽象方法,实现对单个分片项作业的处理。
4.6.1 简单作业执行器
SimpleJobExecutor,简单作业执行器
public final class SimpleJobExecutor extends AbstractElasticJobExecutor {
/**
* 简单作业实现
*/
private final SimpleJob simpleJob;
@Override
protected void process(final ShardingContext shardingContext) {
simpleJob.execute(shardingContext);
}
}
调用
SimpleJob#execute()方法对单个分片项作业进行处理。
4.6.2 数据流作业执行器
DataflowJobExecutor,数据流作业执行器。
public final class DataflowJobExecutor extends AbstractElasticJobExecutor {
/**
* 数据流作业对象
*/
private final DataflowJob当作业配置设置流式处理数据(
DataflowJobConfiguration.streamingProcess = true) 时,调用#streamingExecute()不断加载数据,不断处理数据,直到数据为空 或者 作业不适合继续运行:// LiteJobFacade.java
@Override
public boolean isEligibleForJobRunning() {
LiteJobConfiguration liteJobConfig = configService.load(true);
if (liteJobConfig.getTypeConfig() instanceof DataflowJobConfiguration) {
return !shardingService.isNeedSharding() // 作业不需要重新分片
&& ((DataflowJobConfiguration) liteJobConfig.getTypeConfig()).isStreamingProcess();
}
return !shardingService.isNeedSharding(); // 作业不需要重新分片
}如果采用流式作业处理方式,建议processData处理数据后更新其状态,避免fetchData再次抓取到,从而使得作业永不停止。 流式数据处理参照TbSchedule设计,适用于不间歇的数据处理。
作业需要重新分片,所以不适合继续流式数据处理。
当作业配置不设置流式处理数据(
DataflowJobConfiguration.streamingProcess = false) 时,调用#oneOffExecute()一次加载数据,一次处理数据。调用
#fetchData()方法加载数据;调用#processData(...)方法处理数据:// DataflowJobExecutor.java
/**
* 加载数据
*
* @param shardingContext 分片上下文
* @return 数据
*/
private List{
return dataflowJob.fetchData(shardingContext);
}
/**
* 处理数据
*
* @param shardingContext 分片上下文
* @param data 数据
*/
private void processData(final ShardingContext shardingContext, final List {
dataflowJob.processData(shardingContext, data);
}
4.6.3 脚本作业执行器
ScriptJobExecutor,脚本作业执行器。
public final class ScriptJobExecutor extends AbstractElasticJobExecutor {
@Override
protected void process(final ShardingContext shardingContext) {
final String scriptCommandLine = ((ScriptJobConfiguration) getJobRootConfig().getTypeConfig()).getScriptCommandLine();
if (Strings.isNullOrEmpty(scriptCommandLine)) {
throw new JobConfigurationException("Cannot find script command line for job '%s', job is not executed.", shardingContext.getJobName());
}
executeScript(shardingContext, scriptCommandLine);
}
/**
* 执行脚本
*
* @param shardingContext 分片上下文
* @param scriptCommandLine 执行脚本路径
*/
private void executeScript(final ShardingContext shardingContext, final String scriptCommandLine) {
CommandLine commandLine = CommandLine.parse(scriptCommandLine);
// JSON 格式传递参数
commandLine.addArgument(GsonFactory.getGson().toJson(shardingContext), false);
try {
new DefaultExecutor().execute(commandLine);
} catch (final IOException ex) {
throw new JobConfigurationException("Execute script failure.", ex);
}
}
}
scriptCommandLine传递的是脚本路径。使用 Apache Commons Exec 工具包实现脚本调用:Script类型作业意为脚本类型作业,支持shell,python,perl等所有类型脚本。只需通过控制台或代码配置scriptCommandLine即可,无需编码。执行脚本路径可包含参数,参数传递完毕后,作业框架会自动追加最后一个参数为作业运行时信息。
脚本参数传递使用 JSON 格式。
4.7 执行被错过触发的作业
当作业执行过久,导致到达下次执行时间未进行下一次作业执行,Elastic-Job-Lite 会设置该作业分片项为被错过执行( misfired )。下一次作业执行时,会补充执行被错过执行的作业分片项。
标记作业被错过执行
// JobScheduler.java
private Scheduler createScheduler() {
Scheduler result;
// 省略部分代码
result.getListenerManager().addTriggerListener(schedulerFacade.newJobTriggerListener());
return result;
}
private Properties getBaseQuartzProperties() {
// 省略部分代码
result.put("org.quartz.jobStore.misfireThreshold", "1");
return result;
}
// JobScheduleController.class
private CronTrigger createTrigger(final String cron) {
return TriggerBuilder.newTrigger()
.withIdentity(triggerIdentity)
.withSchedule(CronScheduleBuilder.cronSchedule(cron)
.withMisfireHandlingInstructionDoNothing())
.build();
}
org.quartz.jobStore.misfireThreshold设置最大允许超过 1 毫秒,作业分片项即被视为错过执行。#withMisfireHandlingInstructionDoNothing()设置 Quartz 系统不会立刻再执行任务,而是等到距离目前时间最近的预计时间执行。重新执行被错过执行的作业交给 Elastic-Job-Lite 处理。使用 TriggerListener 监听被错过执行的作业分片项:
// JobTriggerListener.java
public final class JobTriggerListener extends TriggerListenerSupport {@Override
public void triggerMisfired(final Trigger trigger) {
if (null != trigger.getPreviousFireTime()) {
executionService.setMisfire(shardingService.getLocalShardingItems());
}
}}
// ExecutionService.java
public void setMisfire(final Collectionitems) {
for (int each : items) {
jobNodeStorage.createJobNodeIfNeeded(ShardingNode.getMisfireNode(each));
}
}调用
#setMisfire(…)设置作业分片项被错过执行。
跳过正在运行中的被错过执行的作业
// LiteJobFacade.java
@Override
public boolean misfireIfRunning(final Collection shardingItems) {
return executionService.misfireIfHasRunningItems(shardingItems);
}
// ExecutionService.java
public boolean misfireIfHasRunningItems(final Collection items) {
if (!hasRunningItems(items)) {
return false;
}
setMisfire(items);
return true;
}
public boolean hasRunningItems(final Collection items) {
LiteJobConfiguration jobConfig = configService.load(true);
if (null == jobConfig || !jobConfig.isMonitorExecution()) {
return false;
}
for (int each : items) {
if (jobNodeStorage.isJobNodeExisted(ShardingNode.getRunningNode(each))) {
return true;
}
}
return false;
}
当分配的作业分片项里存在任意一个分片正在运行中,设置分片项都被错过执行(
misfired),并不执行这些作业分片。如果不进行跳过,则可能导致同时运行某个作业分片。该功能依赖作业配置监控作业运行时状态(
LiteJobConfiguration.monitorExecution = true)时生效。
执行被错过执行的作业分片项
// AbstractElasticJobExecutor.java
public final void execute() {
// .... 省略部分代码
// 执行 被跳过触发的作业
while (jobFacade.isExecuteMisfired(shardingContexts.getShardingItemParameters().keySet())) {
jobFacade.clearMisfire(shardingContexts.getShardingItemParameters().keySet());
execute(shardingContexts, JobExecutionEvent.ExecutionSource.MISFIRE);
}
// .... 省略部分代码
}
// LiteJobFacade.java
@Override
public boolean isExecuteMisfired(final Collection shardingItems) {
return isEligibleForJobRunning() // 合适继续运行
&& configService.load(true).getTypeConfig().getCoreConfig().isMisfire() // 作业配置开启作业被错过触发
&& !executionService.getMisfiredJobItems(shardingItems).isEmpty(); // 所执行的作业分片存在被错过( misfired )
}
@Override
public void clearMisfire(final Collection shardingItems) {
executionService.clearMisfire(shardingItems);
}
清除分配的作业分片项被错过执行的标识,并执行作业分片项。
为什么此处使用 while(…)?防御性编程,
#isExecuteMisfired(…)判断使用内存缓存的数据,而该数据的更新依赖 Zookeeper 通知进行异步更新,可能因为各种情况,例如网络,数据可能未及时更新导致数据不一致。使用 while(…) 进行防御编程,保证内存缓存的数据已经更新。
4.8 执行作业失效转移
// LiteJobFacade.java
@Override
public void failoverIfNecessary() {
if (configService.load(true).isFailover()) {
failoverService.failoverIfNecessary();
}
}
调用作业失效转移服务( FailoverService )执行作业失效转移(
#failoverIfNecessary()),在《Elastic-Job-Lite 源码解析 —— 作业失效转移》详细分享。
4.9 执行作业执行后的方法
// LiteJobFacade.java
@Override
public void afterJobExecuted(final ShardingContexts shardingContexts) {
for (ElasticJobListener each : elasticJobListeners) {
each.afterJobExecuted(shardingContexts);
}
}
调用作业监听器执行作业执行后的方法,在《Elastic-Job-Lite 源码解析 —— 作业监听器》详细分享。
666. 彩蛋
呼!略长略长略长!
下面会更新如下两篇文章,为后续的主节点选举、失效转移、作业分片策略等文章做铺垫:
《Elastic-Job-Lite 源码解析 —— 注册中心》
《Elastic-Job-Lite 源码解析 —— 作业数据存储》
道友,赶紧上车,分享一波朋友圈!
啊啊啊,我好想马上拜读 Elastic-Job-Cloud。为了你们,我忍住了心碎。
旁白君:煞笔笔者已经偷偷在读了。
芋道君:旁白君,你大爷!
如果你对 Dubbo 感兴趣,欢迎加入我的知识星球一起交流。
目前在知识星球(https://t.zsxq.com/2VbiaEu)更新了如下 Dubbo 源码解析如下:
01. 调试环境搭建
02. 项目结构一览
03. 配置 Configuration
04. 核心流程一览
05. 拓展机制 SPI
06. 线程池
07. 服务暴露 Export
08. 服务引用 Refer
09. 注册中心 Registry
10. 动态编译 Compile
11. 动态代理 Proxy
12. 服务调用 Invoke
13. 调用特性
14. 过滤器 Filter
15. NIO 服务器
16. P2P 服务器
17. HTTP 服务器
18. 序列化 Serialization
19. 集群容错 Cluster
20. 优雅停机
21. 日志适配
22. 状态检查
23. 监控中心 Monitor
24. 管理中心 Admin
25. 运维命令 QOS
26. 链路追踪 Tracing
...
一共 60 篇++
源码不易↓↓↓↓↓
点赞支持老艿艿↓↓