Oracle DataGuard介绍
在默认情况下,redo传输服务使用arcn进程发送redo,不过arcn归档进程只支持最高性能的保护模式,如果备库处于其他保护模式,就必须使用lgwr传输redo数据。
Maximum Availability模式
最高可用性(Maximum availability):这种模式在不影响Primary数据库可用前提下,提供最高级别的数据保护策略。其实现方式与最大保护模式类似,也是要求本地事务在提交前必须至少写入一台Standby数据库的Standby Redologs中,不过与最大保护模式不同的是,如果出现故障导致Standby数据库无法访问,Primary数据库并不会被Shutdown,而是自动转为最高性能模式,等Standby数据库恢复正常之后,Primary数据库又会自动转换成最高可用性模式。
Maximum protection/AVAILABILITY模式必须满足以下条件:
(1)Redo Archival Process: LGWR
(2)Network Tranmission mode: SYNC
(3)Disk Write Option: AFFIRM
(4)Standby Redo Logs: Yes
(5)standby database type: Physical Only
即Standby Database 必须配置Standby Redo Log,而Primary Database必须使用LGWR,SYNC,AFFIRM 方式归档到Standby Database.
如:
SQL> alter system set log_archive_dest_2=’service=orcl_st lgwr sync AFFIRM’;
注意: 主库的保护模式修改之后,备库的模式也会改变,和主库保持一致。
在此对LGWR 进程的SYNC 方式做下说明:
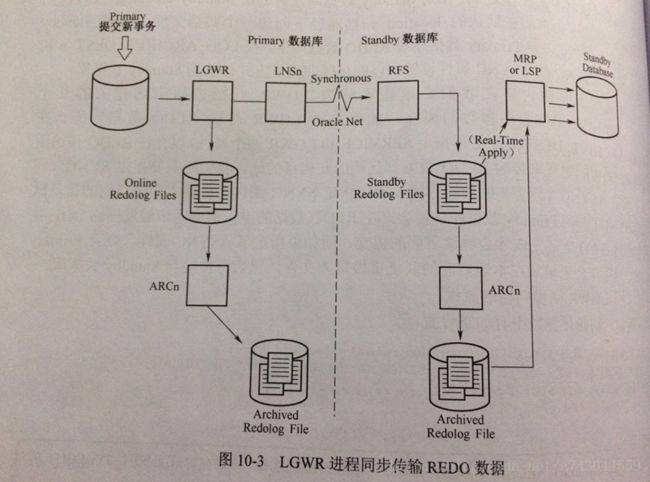
(1)Primary Database 产生的Redo 日志要同时写道日志文件和网络。也就是说LGWR进程把日志写到本地日志文件的同时还要发送给本地的LNSn进程(Network Server Process),再由LNSn(LGWR Network Server process)进程把日志通过网络发送给远程的目的地,每个远程目的地对应一个LNS进程,多个LNS进程能够并行工作。
(2)LGWR 必须等待写入本地日志文件操作和通过LNSn进程的网络传送都成功,Primary Database 上的事务才能提交,这也是SYNC的含义所在。
(3)Standby Database的RFS进程把接收到的日志写入到Standby Redo Log日志中。
(4) Primary Database的日志切换也会触发Standby Database 上的日志切换,即Standby Database 对Standby Redo Log的归档,然后触发Standby Database 的MRP或者LSP 进程恢复归档日志。
因为Primary Database 的Redo 是实时传递的,于是Standby Database 端可以使用两种恢复方法:
实时恢复(Real-Time Apply): 只要RFS把日志写入Standby Redo Log 就会立即进行恢复;
归档恢复: 在完成对Standby Redo Log 归档才触发恢复。
Primary Database默认使用ARCH进程,如果使用LGWR进程必须明确指定。使用LGWR SYNC方式时,可以同时使用NET_TIMEOUT参数,这个参数单位是秒,代表如果多长时间内网络发送没有响应,LGWR 进程会抛出错误。
最大性能模式:
当dg处于最大性能模式,主库提交事务,发生checkpoint动作,会触发LGWR一次写磁盘操作,当redolog达到条件后会触发ARCn归档操作,归档路径是log_archive_dest_n规定的路径,ARCn进程会触发archivelog 传输动作,ARCn把主库archivelog日志传输给备库的RFS(remote file system)进程,由RFS进程将传输过来的日志写入到standby redolog,直接由MRP(redo apply)或者LSP(sql apply)进程直接应用standby redolog同步数据库(如果配置了standby redolog)。如果没配置standby redolog,直接由RFS写入到备库的归档日志路径,然后由MRP(redo apply)或者LSP(sql apply)进程直接应用redolog同步数据库。
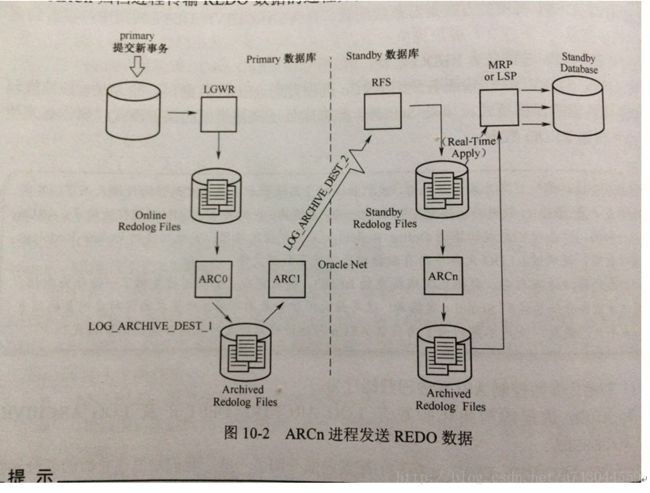
dg 主库进程:
SQL> select process,status,thread#,sequence#,block#,blocks from v$managed_standby;
PROCESS STATUS THREAD# SEQUENCE# BLOCK# BLOCKS
--------- ------------ ---------- ---------- ---------- ----------
ARCH CLOSING 2 9698 94209 2034
ARCH CLOSING 1 11022 1 1411
ARCH CLOSING 1 11019 1 261
ARCH CLOSING 2 9697 1 163
LNS WRITING 1 11033 420893 1
dg 备库进程
SQL> select process,status,thread#,sequence#,block#,blocks from v$managed_standby;
PROCESS STATUS THREAD# SEQUENCE# BLOCK# BLOCKS
--------- ------------ ---------- ---------- ---------- ----------
ARCH CONNECTED 0 0 0 0
ARCH CONNECTED 0 0 0 0
ARCH CLOSING 1 11032 53248 282
ARCH CONNECTED 0 0 0 0
RFS IDLE 0 0 0 0
RFS IDLE 1 11033 420959 1
MRP0 WAIT_FOR_LOG 1 11033 0 0
7 rows selected.如果dg不是处于最大性能模式,主库传输redolog到备库并不是由ARCn而是由LGWR来完成redolog传出任务,主库不必等到redolog发生归档就可以直接传输到备库(因为就不需要归档,也不传输archivelog),备库的LGWR进程会选择一个standby redolog去接收主库redolog传输过来的日志,如果备库没有创建standby redolog文件,则standby 数据库会自动在默认的路径下创建一个归档日志,替代standby redolog文件。当主库有redo数据产生,主库会根据log_archive_dest_n参数的 sync或async属性来同步或异步来传输日志到standby数据库。
log_archive_dest_n参数属性:
sync:同步传输redo数据到备库,意味着主库产生的redo数据必须实时传输到备库之后主库才能进行下一步操作,主库产生的redo数据由LNSn(LGWR Network Server processes)进程发送至备库,备库的RFS进程将接受到的redo数据写入standby redolog中。需要注意的是在此期间主库事务会一直保持,直到LGWR SYNC属性的log_archive_dest_n接收完成,如果由于网络或者其他什么原因到值备库无法接收到redolog数据,那么主库将会一直等待直至报错,所以此种场景下需要设置NET_TIMEOUT属性。
async:异步传输redo数据到备库,主库产生的redo数据会先记录在redolog中,然后在传输到备库
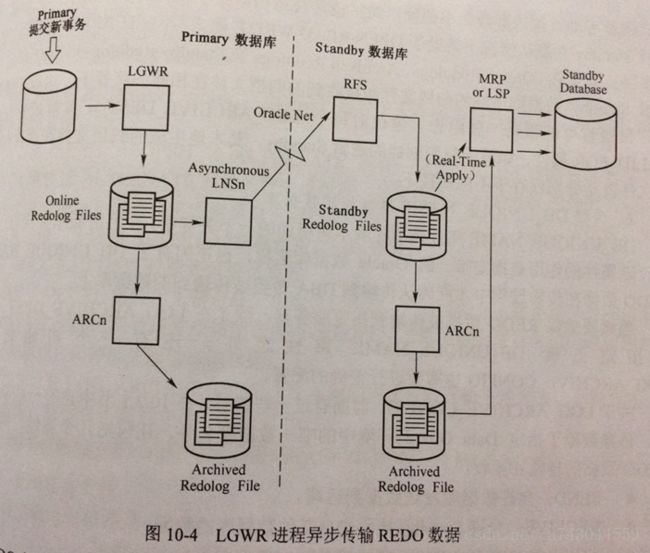
valid_for:规定传输内容,需要设置两个属性redo_log_type、database_type,默认值为valid_for=(all_logfiles,all_roles)
redo_log_type:可设置为 online_logfile、standby_logfile和all_logfiles
database_role:可设置为primary_role、standby_role和all_roles。
reopen:指向规定的目的地归档日志失败,在规定时间内重新发送。
alternate:指定一个替补的归档目的地,当主归档路径发生错误时,可以把redolog数据写到另外一个路径。
例如:
log_archive_dest_1=’location=/desk1 alternate=log_archive_dest_2’
log_archive_dest_2=’location=/desk2’
log_archive_dest_state=’alternate’
上述参数设置归档路径/desk1,当/desk1无法完成归档时将自动尝试向/desk2写归档。如果设置了reopen参数,则先尝试在规定的时间内发送数据,如果在规定时间没没有归档成功则尝试向备用路径归档。
max_failure:用来指定最大失败尝试次数。
dg参数详解:
log_archive_dest_2=’location=+archive valid_for=(all_logfiles,all_roles) db_unique_name=pydb’;//本地归档路径
log_archive_dest_3=’service=stydb valid_for=(online_logfiles,primary_role) db_unique_name=stydb’;//远程归档路径
log_file_name_covert=’+DATA/pydb/’,’+DATA/stydb/’;//主–备库日志文件传输路径转换
db_file_name_convert=’+DATA/pydb/’,’+DATA/stydb’;//主–备数据文件传输路径转换
standby_file_management=’auto’;//备库角色传输日志,创建数据文件为数据库自动控制。
fal_client=’rac1’,’rac2’;//发生故障转移,客户端为自己。指定客户端Net服务器名
fal_server=’jhdb_dg’;//发生故障转移,服务端为对方。指定服务端Net服务器名
db_name=’jhdb’//保持同一个dataguard中db_name一致,
db_unique_name=’pydb’;//一个数据库唯一名字,RAC中节点名字应保持一致,dg中主备库应区分开来。
log_archive_config=’dg_config=(pydb,stydb)’;//该参数用来控制从远端接受或发送redolog数据,通过此参数来控制参与dg的所有db_unique_name的成员。
remote_login_passwordfile=’exclusive’;//远程登录方式,官方推荐设置为exclusive或shared,确保一个dg中所有的库的sys一致,强制使用密码文件来验证口令。
fal_server=’stydb’;//指定一个Net server服务名,fal是fetch archive log的缩写,一般是发生角色转换时,获取redolog的服务端是哪个,一般填对端的tnsnames名称。
fal_client=’pydb’;// 指定一个Net server服务名,fal是fetch archive log的缩写,一般是发生角色转换时,获取redolog的客户端是哪个,一般填对端的tnsnames名称。
db_file_name_convert=’remote_file_path’,’local_file_path’;//standby数据库的数据文件路径与primary数据库路径不一致时,可以通过此参数来控制让其自动转换,前面的值表示转换前的路径, 表示转换后的路径。
log_file_name_convert=’remote_log_path’,’local_log_path’;//
standby_file_management=’auto’;//如果primary数据库文件发现修改,备库自动管理相应文件,不需要手动维护。可以自动维护主备库绝大多数DML操作(文件重命名、改变路径,redolog文件删除或添加除外)。
注意:
db_file_name_convert、log_file_name_convert是做主备切换时用到,这两参数要重启后才能生效。
为了文件存储格式的,这两参数的值是成对出现的。
在ASM的RAC中不要更改db_unique_name的值,因为ASM的文件存储方式是按些值存放的。
更多请参考 http://blog.csdn.net/liqfyiyi/article/details/52127121。