redis集群(服务端sharding)
前言
使用哨兵机制,redis每个实例也是全量存储,每个redis存储的内容都是完整的数据,浪费内存且有木桶效应,同时在数据量大的情况下,写入节点无法做水平扩展,所以为了最大化利用内存,可以采用集群模式,在redis在3.0版本后,官方支持了redis cluster,也就是集群,也叫服务端sharding分片
Redis Cluster设计要点
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
那么redis 是如何合理分配这些节点和数据的呢?
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。
所以,我们假设现在有3个节点已经组成了集群,分别是:A, B, C 三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽 (hash slot)的方式来分配16384个slot 的话,它们三个节点分别承担的slot 区间是:
节点A覆盖0-5460;
节点B覆盖5461-10922;
节点C覆盖10923-16383.
那么,现在我想设置一个key ,比如叫my_name:
set my_name yangyi
按照redis cluster的哈希槽算法:CRC16(‘my_name’)%16384 = 2412。 那么就会把这个key 的存储分配到 A 上了。
同样,当我连接(A,B,C)任何一个节点想获取my_name这个key时,也会这样的算法,然后内部跳转到B节点上获取数据。
这种哈希槽的分配方式有好也有坏,好处就是很清晰,比如我想新增一个节点D,redis cluster的这种做法是从各个节点的前面各拿取一部分slot到D上,我会在接下来的实践中实验。大致就会变成这样:
节点A覆盖1365-5460
节点B覆盖6827-10922
节点C覆盖12288-16383
节点D覆盖0-1364,5461-6826,10923-12287
同样删除一个节点也是类似,如果有key,不能直接删除,需要把key值迁移到其它节点,移动完成后就可以删除这个节点了。
Redis Cluster主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉。
上面那个例子里, 集群有ABC三个主节点, 如果这3个节点都没有加入从节点,如果B挂掉了,我们就无法访问整个集群了。A和C的slot也无法访问。
所以我们在集群建立的时候,一定要为每个主节点都添加了从节点, 比如像这样, 集群包含主节点A、B、C, 以及从节点A1、B1、C1, 那么即使B挂掉系统也可以继续正确工作。
B1节点替代了B节点,所以Redis集群将会选择B1节点作为新的主节点,集群将会继续正确地提供服务。 当B重新开启后,它就会变成B1的从节点。
不过需要注意,如果节点B和B1同时挂了,Redis集群就无法继续正确地提供服务了。
redis cluster 动手实践
**声明(重点):本人是在windows10系统下搭建linux虚拟机环境,所有安装包都是通过手动下载,解压安装,使用的虚拟机环境是VMware( ubuntu )
1、下载
官网下载redis3.0后的版本,本人使用的是最新的redis5.0稳定版本
redis-5.0.4.tar.gz
2、解压
tar xzf redis-5.0.4.tar.gz
3、安装(切换到root用户)
修改阿里源为Ubuntu 18.04默认的源
备份/etc/apt/sources.list
#备份
cp /etc/apt/sources.list /etc/apt/sources.list.bak
在/etc/apt/sources.list文件前面添加如下条目
#添加阿里源
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
-
使用如下命令更新源
apt-get update -
使用命令安装gcc
apt install gcc -
查看gcc版本

-
安装make
apt install make -
进入redis解压目录,安装
make && make install
4、将redis-trib.rb 复制到/usr/local/bin
![]()
5、开始集群搭建
[root@web3 redis-3.0.5]# vi redis.conf
#修改以下地方
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
新建6个节点:

将redis.conf 分别拷贝到这6个文件夹中,并修改成对应的端口号

启动这6个节点,
分别进入7000、7001、7002、7003、7004、7005目录下执行redis-server redis.conf命令启动(注意启动前把所有节点的redis.conf文件中将“daemonize no”修改为“daemonize yes”,设置为后台进行运行),查看启动状态,ok,都已经正常启动了

将6个节点连在一起构招成集群
需要用到的命令就是redis-trib.rb,这是官方的一个用ruby写的一个操作redis cluster的命令,所以,你的机器上需要安装ruby
- apt install ruby 默认安装最新版本
- 同步时安装ruby 和 redis的连接 gem install redis
- 最后一步,执行集群命令,因为redis-trib.rb目前不可用,所以上面两步跳过,不用操作,使用redis-cli --cluster搭建集群
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1

通过上图可知,默认搭建集群的主从关系如下:
master(7000)->slave(7004)
master(7001)->slave(7005)
master(7002)->slave(7003)
3个主节点[M]是:
7000(b072c875468b7a1668e7589830c6bffff47ec0e2)
7001(3aedb80d126c93a1a893e4a6dfa1cc8dc46678e7)
7002(69dfb1a4db5eaa41043f6a78744e75b5dc3e85c7)
3个从节点 【S】是:
7004(0b83b96fb420ad6b24f3fc115bebfcf9fd985072)
7005(6eeab6147fa6ebf6cd8b8d85533d2934a7852d4a)
7003(a333ee1bef30c371b3ce56c7e1eabff9f93d25b9)
6、测试集群连接
刚才集群搭建成功了。按照redis cluster的特点,它是去中心化,每个节点都是对等的,所以,你连接哪个节点都可以获取和设置数据,我们来试一下。
redis-cli是redis默认的客户端工具,启动时加上`-c`参数,就可以连接到集群。
连接任意一个节点端口:

前面理论知识我们知道了,分配key的时候,它会使用CRC16(‘my_name’)%16384算法,来计算,将这个key 放到哪个节点,这里分配到了12803slot 就分配到了7002(10923-16383)这个节点上。
redis cluster 采用的方式很直接,它直接跳转到7002 节点了,而不是还在自身的7000节点。
好,现在我们连接7005这个从节点:

我们同样是获取my_name的值,它同样也是跳转到了7002上。
7、测试集群中的节点挂掉
上面我们建立来了一个集群。3个主节点[7000-7002]提供数据存粗和读取,3个从节点[7003-7005]则是负责把[7000-7002]的数据同步到自己的节点上来,上面示例的key my_name 在节点7002中,现在模拟7002节点挂掉,看7003节点是否会变成master节点
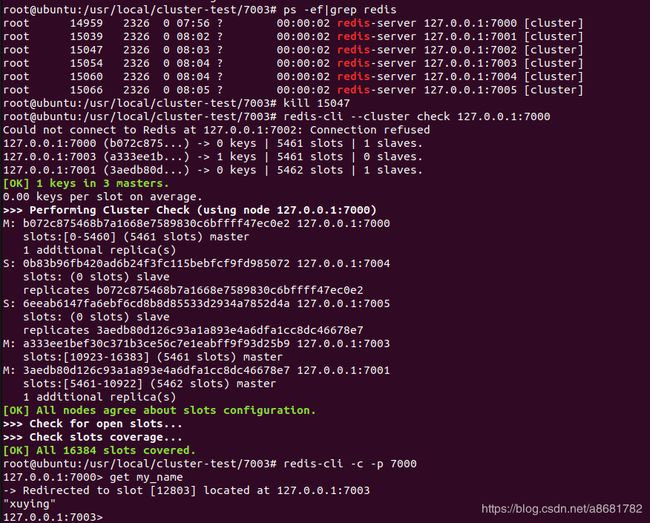
从图中结果发现 7003节点升级为主节点,同时 get my_name 返回xuying,说明数据并没有丢失,并且key是落在了7003节点,
OK。我们再来模拟 7002节点重新启动了的情况,那么它还会自动加入到集群中吗?那么,7002这个节点上充当什么角色呢? 我们试一下:
重新启动 7002节点:

7002节点启动起来了,它却作为了 7003 的从节点了
一定要保证有3个master 节点,不然,集群就挂掉了。
8、集群中新加入节点
我们再来测试一下,新加入一个节点,分2种情况,1是作为主节点,2是作为一个节点的从节点。我们分别来试一下:
- 新建一个 7006 节点 作为一个新的主节点加入

- 查看集群状态
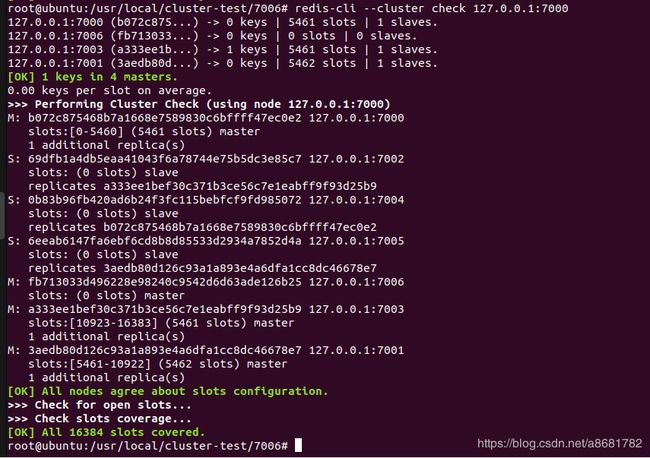
可以看到了,7006 已经成为了主节点。
我们也可以连接到客户端后,来看这个集群节点情况:

可以看到7006节点并没有分片slot,看来,redis cluster 不是在新加节点的时候帮我们做好了迁移工作,需要我们手动对集群进行重新分片迁移,也是这个命令
redis-cli --cluster reshard 127.0.0.1:7000
- 它提示我们需要迁移多少slot到7006上,我们可以算一下:16384/4 =
4096,也就是说,为了平衡分配起见,我们需要移动4096个槽点到7006
好,那输入4096: - 它又提示我们,接受的node ID是多少,7006的id
- 接着, redis-trib 会向你询问重新分片的源节点(source node), 也即是, 要从哪个节点中取出 4096 个哈希槽,
并将这些槽移动到7006节点上面
如果我们不打算从特定的节点上取出指定数量的哈希槽, 那么可以向 redis-trib 输入 all , 这样的话, 集群中的所有主节点都会成为源节点, redis-trib 将从各个源节点中各取出一部分哈希槽, 凑够 4096 个, 然后移动到7006节点上: - 输入 yes 并使用按下回车之后,redis-trib 就会正式开始执行重新分片操作,将指定的哈希槽从源节点一个个地移动到7006节点上面。
迁移完毕之后,我们来检查下:

我们着重看7006:
0-1364,5461-6826,10923-12287 (4096 slots)
新建一个 7007从节点,作为7006的从节点
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7006 --cluster-slave --cluster-master-id fb713033d496228e98240c9542d6d63ade126b25
add-node: 后面的分别跟着新加入的slave和slave对应的master
cluster-slave:表示加入的是slave节点
–cluster-master-id:表示slave对应的master的node ID
9、在集群中删除节点
尝试删除主节点7001
由于7001已经分配了槽(slot),不能被移除,不管该节点key * 是不是为empty,也就是说得重新分片,用上面增加新节点后的分片方式一样
redis-cli --cluster reshard 127.0.0.1:7000
- 迁移的槽数量:4096
- 目标节点的runId,这里选择节点7003
- 源节点的runId,这里选择节点7001
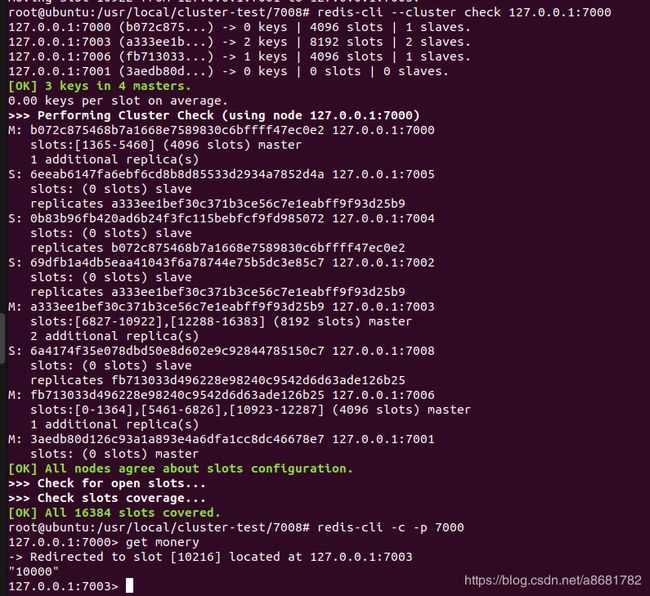
key=monery原来在节点7001上,迁移后,数据成功存储到节点7003,说明数据迁移成功
同时 7005变成了7003的从节点(原来是7001的从节点),此时7003主节点下面有两个从节点:
7005 和 7002

如果是移除从节点,就不需要数据的迁移
至此,整个redis集群的搭建、槽分配、新增节点、移除节点结束