pytorch学习十 ---- 优化器
1、什么是优化器?
首先我们回忆一下机器学习的五大模块:数据、模型、损失函数、优化器、迭代训练

在损失函数中我们会得到一个loss值,即真实标签与预测标签的差异值,对于loss我们通常会采用pytorch中的autograd自动求导机制进行求导,优化器拿到每个参数的导数会根据优化策略去更新我们的模型的参数,并使得模型的loss值呈下降趋势。因此优化器的主要作用是采用梯度去更新我们模型中的可学习参数,使得模型的输出与真实差异更小,即让loss值下降。
pytorch的优化器:管理 并更新 模型中可学习参数的值,使得模型输出更接近真实标签。
管理:指优化器去管理哪部分参数,可修改哪部分参数;
更新:优化器中有一些优化的策略,我们采用这些策略去更新模型中可学习参数的值;在神经网络中通常采用梯度下降的策略方法去更新我们的参数。
什么是梯度下降,为什么梯度下降会使得loss值降低?想了解梯度下降就得先了解什么是梯度。梯度是一个向量,梯度的方向是使得方向导数最大的那个方向。那什么是方向导数?什么是导数呢?
导数:函数在指定坐标轴上的变化率;
方向导数:指定方向上的变化率
梯度:一个向量,方向为方向导数取得最大值的方向。
梯度下降:梯度的负方向
pytorch中的优化器

基本属性:
- defaults:优化器超参数
- state:参数的缓存,如momentum的缓存
- param_groups:管理的参数组,为一个list,每个元素为一个字典
- _step_count:记录更新次数,学习率调整中使用
基本方法:
- zero_grad():清空所管理参数的梯度
class Optimizer(object):
def zero_grad(self):
for group in self.param_groups:
for p in group["params"]:
if p.grad in not None:
p.grad.detach_()
p.grad.zero_()pytorch特性:张量梯度不自动清零
- step():执行一步更新
class Optimizer(object):
def __init__(self,params,defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []- add_param_group():添加一组参数到优化器中
class Optimizer(object):
def add_param_group(self,param_group):
for group in self.param_groups:
param_set.update(set(group['params']))
self.param_groups.append(param_group)- state_dict():获取优化器当前状态信息字典
- load_state_dict():加载状态信息字典
class Optimizer(object):
def state_dict(self):
return{
"self":packed_state,
"param_groups":param_groups,
}
def load_state_dict(self,state_dict)这两个方法主要用在断点时能通常保存的信息直接获取模型最近的状态,而不需要从头开始。load_state_dict是在间隔一定epoch时,保存模型信息,state_dict():获取保存中最新的状态信息。
在人民币分类模型训练中:
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略debug进入optimizer中:
def __init__(self, params, lr=required, momentum=0, dampening=0,
weight_decay=0, nesterov=False):
if lr is not required and lr < 0.0:
raise ValueError("Invalid learning rate: {}".format(lr))
if momentum < 0.0:
raise ValueError("Invalid momentum value: {}".format(momentum))
if weight_decay < 0.0:
raise ValueError("Invalid weight_decay value: {}".format(weight_decay))
defaults = dict(lr=lr, momentum=momentum, dampening=dampening,
weight_decay=weight_decay, nesterov=nesterov)
if nesterov and (momentum <= 0 or dampening != 0):
raise ValueError("Nesterov momentum requires a momentum and zero dampening")
super(SGD, self).__init__(params, defaults)最后依据debug进入:
def __init__(self, params, defaults):
torch._C._log_api_usage_once("python.optimizer")
self.defaults = defaults
if isinstance(params, torch.Tensor):
raise TypeError("params argument given to the optimizer should be "
"an iterable of Tensors or dicts, but got " +
torch.typename(params))
self.state = defaultdict(dict)
self.param_groups = []
param_groups = list(params)
if len(param_groups) == 0:
raise ValueError("optimizer got an empty parameter list")
if not isinstance(param_groups[0], dict):
param_groups = [{'params': param_groups}]
for param_group in param_groups:
self.add_param_group(param_group)这是看下面的defaults:
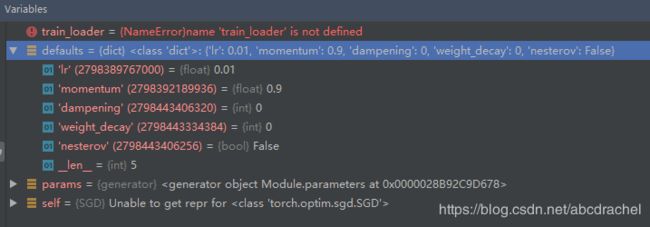
那下面学习五个方法的具体使用:
首先构建可学习参数:
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
import torch
import torch.optim as optim
from tools.common_tools import set_seed
set_seed(1) # 设置随机种子
weight = torch.randn((2, 2), requires_grad=True)
weight.grad = torch.ones((2, 2))
然后构建优化器,将可学习参数放进去,同时设置一个学习率:
optimizer = optim.SGD([weight], lr=0.1)然后我们采用梯度下降的方法,梯度下降就是让可学习参数朝着参数梯度的负方向更新,即让参数值加上负梯度值。
# ----------------------------------- step -----------------------------------
# flag = 0
flag = 1
if flag:
print("weight before step:{}".format(weight.data))
optimizer.step() # 修改lr=1 0.1观察结果
print("weight after step:{}".format(weight.data))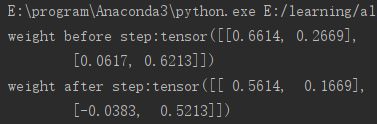
即用梯度-lr*weigt.grad
下面观察zero_grad的使用,zero_grad是清空我们的梯度:
# ----------------------------------- zero_grad -----------------------------------
# flag = 0
flag = 1
if flag:
print("weight before step:{}".format(weight.data))
optimizer.step() # 修改lr=1 0.1观察结果
print("weight after step:{}".format(weight.data))
print("weight in optimizer:{}\nweight in weight:{}\n".format(id(optimizer.param_groups[0]['params'][0]), id(weight)))
print("weight.grad is {}\n".format(weight.grad))
optimizer.zero_grad()
print("after optimizer.zero_grad(), weight.grad is\n{}".format(weight.grad))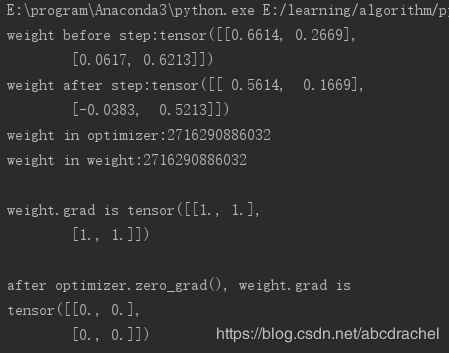
这里保存参数是保存参数的地址
下面是add_param_group:
# ----------------------------------- add_param_group -----------------------------------
# flag = 0
flag = 1
if flag:
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))
w2 = torch.randn((3, 3), requires_grad=True)
optimizer.add_param_group({"params": w2, 'lr': 0.0001})
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))
# ----------------------------------- state_dict -----------------------------------
# flag = 0
flag = 1
if flag:
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9)
opt_state_dict = optimizer.state_dict()
print("state_dict before step:\n", opt_state_dict)
for i in range(10):
optimizer.step()
print("state_dict after step:\n", optimizer.state_dict())
torch.save(optimizer.state_dict(), os.path.join(BASE_DIR, "optimizer_state_dict.pkl"))
# -----------------------------------load state_dict -----------------------------------
# flag = 0
flag = 1
if flag:
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9)
state_dict = torch.load(os.path.join(BASE_DIR, "optimizer_state_dict.pkl"))
print("state_dict before load state:\n", optimizer.state_dict())
optimizer.load_state_dict(state_dict)
print("state_dict after load state:\n", optimizer.state_dict())
优化器Optimizer(二)
学习率 learning rate
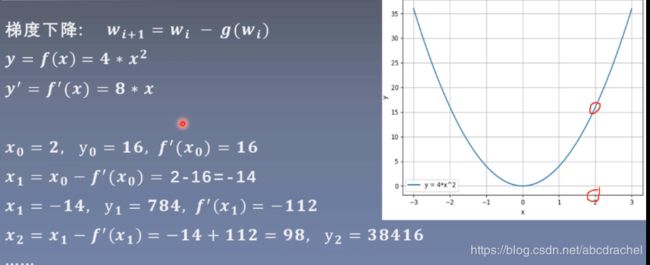
梯度下降:![]() ,其中
,其中![]() 为其梯度;
为其梯度;
首先定义函数,并绘制函数:
import torch
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(1)
def func(x_t):
"""
y = (2x)^2 = 4*x^2 dy/dx = 8x
"""
return torch.pow(2*x_t, 2)
# init
x = torch.tensor([2.], requires_grad=True)
# ------------------------------ plot data ------------------------------
# flag = 0
flag = 1
if flag:
x_t = torch.linspace(-3, 3, 100)
y = func(x_t)
plt.plot(x_t.numpy(), y.numpy(), label="y = 4*x^2")
plt.grid()
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.show()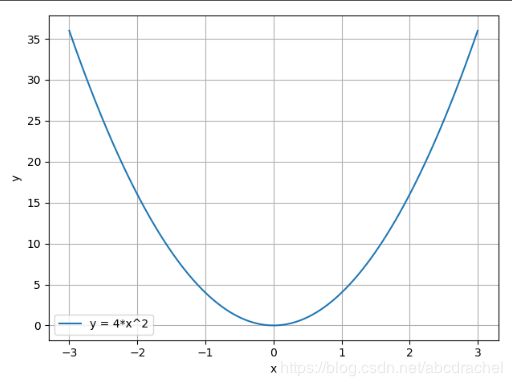
下面用代码演示梯度下降的过程:
# ------------------------------ gradient descent ------------------------------
# flag = 0
flag = 1
if flag:
iter_rec, loss_rec, x_rec = list(), list(), list()
lr = 1 # /1. /.5 /.2 /.1 /.125
max_iteration = 4 # /1. 4 /.5 4 /.2 20 200
for i in range(max_iteration):
y = func(x)
y.backward()
print("Iter:{}, X:{:8}, X.grad:{:8}, loss:{:10}".format(
i, x.detach().numpy()[0], x.grad.detach().numpy()[0], y.item()))
x_rec.append(x.item())
x.data.sub_(lr * x.grad) # x -= x.grad 数学表达式意义: x = x - x.grad # 0.5 0.2 0.1 0.125
x.grad.zero_() #对张量梯度清零,因为pytorch是不会自动清零的,而会累加
iter_rec.append(i)
loss_rec.append(y)
plt.subplot(121).plot(iter_rec, loss_rec, '-ro')
plt.xlabel("Iteration")
plt.ylabel("Loss value")
x_t = torch.linspace(-3, 3, 100)
y = func(x_t)
plt.subplot(122).plot(x_t.numpy(), y.numpy(), label="y = 4*x^2")
plt.grid()
y_rec = [func(torch.tensor(i)).item() for i in x_rec]
plt.subplot(122).plot(x_rec, y_rec, '-ro')
plt.legend()
plt.show()

从上面可以看出,左边是loss迭代图,从运行结果可知,在0-4次迭代过程中,loss值越来越大;
上面我们采用梯度下降法去更新参数值,然而y并没有减小,反而逐渐增大。
这是因为这里减去的梯度尺度太大了,一般我们会在其![]() 前乘以一个系数,来缩小其尺度:
前乘以一个系数,来缩小其尺度:
![]() , 其中
, 其中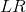 为学习率
为学习率
学习率:learning rate 控制更新的步伐
当我们把学习率设置为0.5时,得到如下结果:

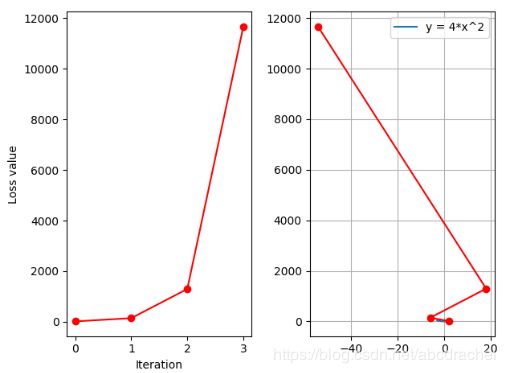
我们发现这个loss值仍然是增大趋势,然而其增加量明显有缩小。
接着我们将学习率设为0.2,得到如下结果:

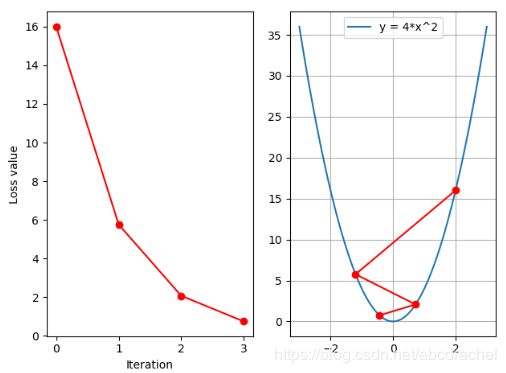
现在可以发现loss是一个下降的趋势,若我们增加迭代次数,观测loss是否继续下降:
设置迭代次数为20,得到如下结果:
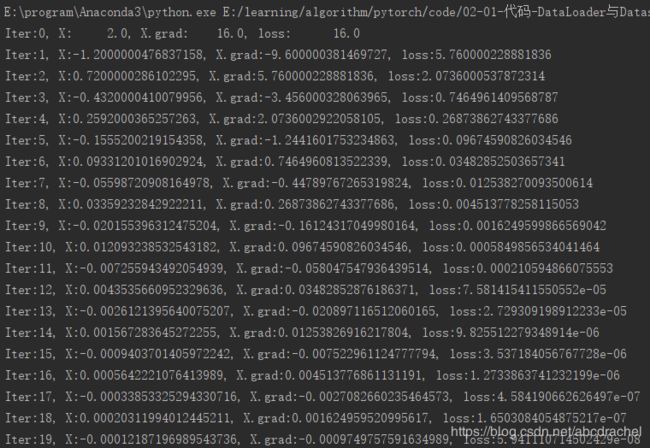
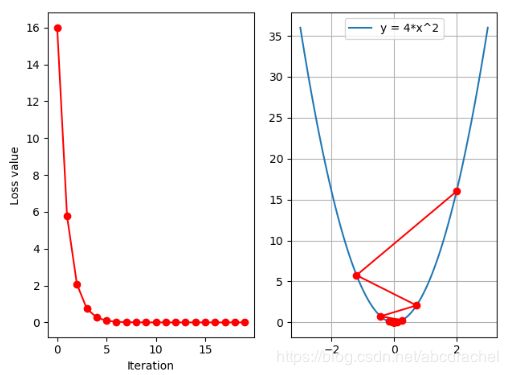
从上可以看出,当迭代次数到达7次左右时,loss几乎趋于直线形式,呈收敛状况,同时loss值也是逐渐下降的。这就是设置一个良好的学习率,可以使得loss值逐渐减小。那应该选什么学习率比较合适呢?下面我们设置多个学习率观测:在0.1-0.5之间,线性设置10个学习率:
# ------------------------------ multi learning rate ------------------------------
# flag = 0
flag = 1
if flag:
iteration = 100
num_lr = 10
lr_min, lr_max = 0.01, 0.5 # .5 .3 .2
lr_list = np.linspace(lr_min, lr_max, num=num_lr).tolist()
loss_rec = [[] for l in range(len(lr_list))]
iter_rec = list()
for i, lr in enumerate(lr_list):
x = torch.tensor([2.], requires_grad=True)
for iter in range(iteration):
y = func(x)
y.backward()
x.data.sub_(lr * x.grad) # x.data -= x.grad
x.grad.zero_()
loss_rec[i].append(y.item())
for i, loss_r in enumerate(loss_rec):
plt.plot(range(len(loss_r)), loss_r, label="LR: {}".format(lr_list[i]))
plt.legend()
plt.xlabel('Iterations')
plt.ylabel('Loss value')
plt.show()
上面得到了10个不同的学习率情况下10种不同的loss曲线,横轴是迭代次数,纵轴是loss值,我们发现第一条蓝色的学习率为0.5,在迭代到接近40次时loss值出现了激增情况,同时我们也发现loss值出现激增的都是学习率较大的曲线。下面我们参数修改学习率的最大值,修改为0.3:

可以看出学习率为0.3仍出现loss激增,但loss值整体所有下降,因此我们再减小学习率最大值为0.2:
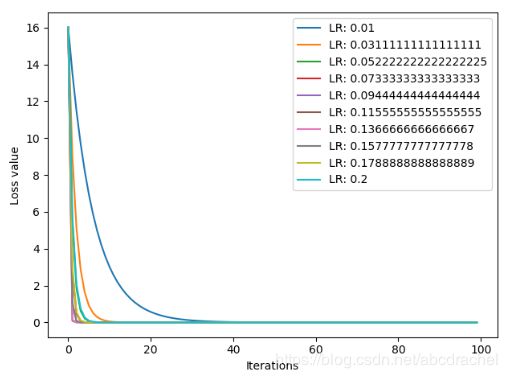
我们可以看出这十条曲线都是呈下降趋势,是我们所想要的情况。
通过代码的演示,我们知道通过设置学习率可以使loss值逐渐减小,直到收敛。学习率主要用来控制更新的步伐,不能太大,也不能太小。在优化器中除了学习率还有一个很重要的概念:Momentum(动力,冲量)
Momentum:结合当前梯度与上一次更新信息,用于当前更新
指数加权平均:![]() ,是在时间序列中常用的用于求解平均值的方法,其思想为:我们求取当前时刻的平均值,距离当前时刻越近的参数值的参考性越大,所占的权重越大,这个权重随着时间间隔的的增大呈指数下降趋势。
,是在时间序列中常用的用于求解平均值的方法,其思想为:我们求取当前时刻的平均值,距离当前时刻越近的参数值的参考性越大,所占的权重越大,这个权重随着时间间隔的的增大呈指数下降趋势。
![]()
![]()
![]()
![]()
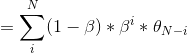
import torch
import numpy as np
import torch.optim as optim
import matplotlib.pyplot as plt
torch.manual_seed(1)
def exp_w_func(beta, time_list):#构建权重计算公式
return [(1 - beta) * np.power(beta, exp) for exp in time_list]
beta = 0.9
num_point = 100
time_list = np.arange(num_point).tolist()
# ------------------------------ exponential weight ------------------------------
# flag = 0
flag = 1
if flag:
weights = exp_w_func(beta, time_list)
plt.plot(time_list, weights, '-ro', label="Beta: {}\ny = B^t * (1-B)".format(beta))
plt.xlabel("time")
plt.ylabel("weight")
plt.legend()
plt.title("exponentially weighted average")
plt.show()
print(np.sum(weights))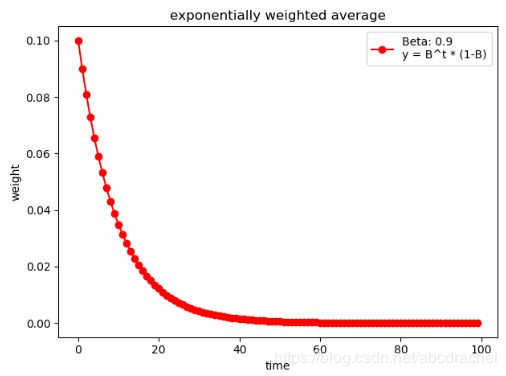
我们可以发现权重呈一个下降趋势,在近50次左右,权重趋于稳定。距离当前时刻越近,影响越大,权重越大,距离当前时刻越远,影响越小。下面设置不同的beta,观测权重变换曲线:
# ------------------------------ multi weights ------------------------------
# flag = 0
flag = 1
if flag:
beta_list = [0.98, 0.95, 0.9, 0.8]
w_list = [exp_w_func(beta, time_list) for beta in beta_list]
for i, w in enumerate(w_list):
plt.plot(time_list, w, label="Beta: {}".format(beta_list[i]))
plt.xlabel("time")
plt.ylabel("weight")
plt.legend()
plt.show()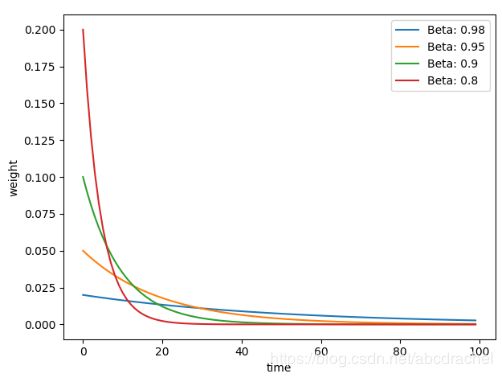
我们发现最上面红色beta为0.8,这也是最小的beta,往下beta逐渐增大,权重逐渐趋向平缓,因此我们可以将beta值理解为记忆周期的概念,beta值越小,记忆周期越短。红色曲线在time为20时,记忆就逐渐消失了;而对于最大的蓝色曲线,它的记忆周期就比较长,八十天的记忆值基本一样。由此可以看出贝塔是用来控制记忆周期,值越大,记忆越久,值越小,记忆越短。通常beta值会设置为0.9,因为该值会更关注当前10天左右的数据。1/(1-beta)
pytorch 中加上momentum后的更新公式:
![]()
![]()
其中 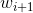 为第 i+1次更新的参数,lr为学习率,
为第 i+1次更新的参数,lr为学习率, 为更新量,m为momentum系数,
为更新量,m为momentum系数,![]() 为
为 的梯度
的梯度
![]()
![]()
![]()
![]()
下面我们采用两个学习率,一个小的学习率加上momentum,一个较大的学习率不加momentum两种情况下的loss曲线:
首先我们来观测两个学习率都不加momentum的情况:
# ------------------------------ SGD momentum ------------------------------
flag = 0
# flag = 1
if flag:
def func(x):
return torch.pow(2*x, 2) # y = (2x)^2 = 4*x^2 dy/dx = 8x
iteration = 100
m = 0 # .9 .63
lr_list = [0.01, 0.03]
momentum_list = list()
loss_rec = [[] for l in range(len(lr_list))]
iter_rec = list()
for i, lr in enumerate(lr_list):
x = torch.tensor([2.], requires_grad=True)
momentum = 0. if lr == 0.03 else m
momentum_list.append(momentum)
optimizer = optim.SGD([x], lr=lr, momentum=momentum)
for iter in range(iteration):
y = func(x)
y.backward()
optimizer.step()
optimizer.zero_grad()
loss_rec[i].append(y.item())
for i, loss_r in enumerate(loss_rec):
plt.plot(range(len(loss_r)), loss_r, label="LR: {} M:{}".format(lr_list[i], momentum_list[i]))
plt.legend()
plt.xlabel('Iterations')
plt.ylabel('Loss value')
plt.show()

从上面结果可知蓝色曲线是学习率为0.01,Momentum为0,橙色的是学习率为0.03,Momentum为0,我们看到此时0.03收敛更快,由于其学习率比较大,收敛比较快。下面我们将小的学习率加一个momentum为0.9,观测是收敛速度是否会超过大的学习率,得到如下结果:
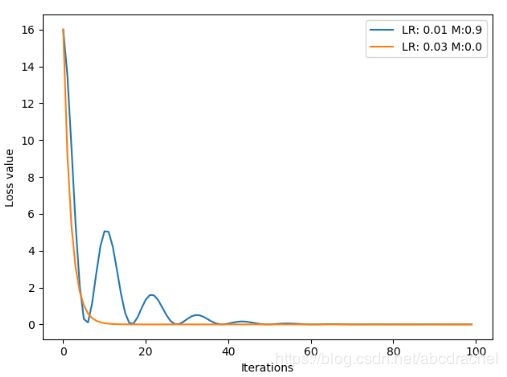
我们发现此时的收敛曲线会波浪型震荡曲线,逐渐收敛。同时我们可观测到蓝色曲线比橙色曲线在更快地达到了最小的点,只不过蓝色曲线达到最小值后又反弹回去了。这是由于momentum太大了,导致已经接近极小值时,但其更新的梯度很大,因此虽然已达到极小值,但受到前一些时候梯度的影响,一下就反弹回去了。下面我们将momentum设置为0.63,然后观测曲线:
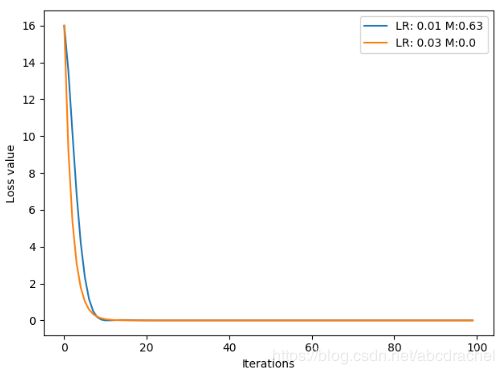
我们发现设置为0.63的时候是一个比较合适的momentum,它会比0.03更快的收敛。
下面我们来学习pytorch提供的最常用,也是最实用的优化器SGD
1. Optim.SGD(params,lr =
主要参数:
- param:管理的参数组
- lr:初始学习率
- momentum:动量系数,贝塔
- weight_decay:L2正则化系数
- nesterov:是否采用NAG
NAG参考文献:《On the importance of initialization and momentum in deep learning》
pytorch提供的其他优化器
1. optim.SGD:随机梯度下降法
2. optim.Adagrad:自适应学习率梯度下降法
3. optim.RMSprop:Adagrad的改进
4. optim.Adadelta:Adagrad的改进
5. optim.Adam:RMSprop结合Momentum
6. optim.Adamax:Adam增加学习率上限
7. optim.SparseAdam:稀疏版的Adam
8. optim.ASGD:随机平均梯度下降
9. optim.Rprop:弹性反向传播
10. optim.LBFGS:BFGS的改进