作业:将数据进行分层抽样,再画图
计划:
1.统计降雨量数据,从而决定如何分层
2.由降雨量进行分层,然后再随机抽取
3.画散点图:x轴为降雨量分层,y轴为风速
关于分层,参考:https://mp.weixin.qq.com/s?__biz=MjM5ODE1NDYyMA==&mid=2653394973&idx=2&sn=5adbe3defa63902059ed5bdcf7365c12&chksm=bd1c200e8a6ba9183d303f58754f4b4b697b783d2d10d3f66ad8c25cfe5568afbb83ffc06516&scene=0&xtrack=1#rd
遇到的问题:
统计降雨量数据阶段:
1.统计最大降雨量的时候无法转换为int型
原因:
ValueError: invalid literal for int() with base 10:
有时候需要用int()函数转换字符串为整型,但是切记int()只能转化由纯数字组成的字符串
解决:只是换成之前的方法了,其实也没有解决。。。。。。
2.统计各降雨量的数据的时候,与我想象的结果不一样
原因:啊!python里的与运算符是and而不是&&
对样本进行抽样阶段:
3.样本数量过大,无法使用分层抽样的方法
使用: each_sample_data = random.sample(sample_list, each_sample_count) # 对每层数据都随机抽样
报错:ValueError: Sample larger than population or is negative
原因:暂时没有特别理解为什么错,但是应该是样本数量太大了,因为样本差不多有28万。
解决方法:改成先分层,然后再等距抽样了。
4.分层只会进行一次,之后的层数无法读取数据
原因:reader指针移到了最后没有重新回到起点
解决方法:重置指针(csvfile为当前文件名)
csvfile.seek(0) #重置reader实现多次迭代
参考:http://www.it1352.com/585326.html http://www.it1352.com/584175.html
画图阶段
5.如何在pycharm中断点调试:
参考:https://www.jb51.net/article/164647.htm
6.有关df[]
df一般是DataFrame的缩写,关于df[],df[[]]等,参考:https://blog.csdn.net/GR346305172/article/details/100169422
7.有关数据类型:OrderedDict
实际上就是改进的字典,即有序的字典。
参考:https://www.cnblogs.com/notzy/p/9312049.html
8.图片无法显示文字
报错:RuntimeWarning: Glyph 38477 missing from current font. font.set_text(s, 0.0, flags=fla。。。。。。
原因:没有配置字体
解决:导入win10自带字体,对matplotlib进行配置
参考:https://blog.csdn.net/lvshu_yuan/article/details/80413005 https://blog.csdn.net/FontThrone/article/details/75042659
9.画图按照列表中数据的顺序来绘制,而非按照大小顺序来绘制
初始,x,y轴均无序,将x,y的列表中的数据都改为float型的时候,变得有序!
参考:https://blog.csdn.net/weixin_44090816/article/details/91392368
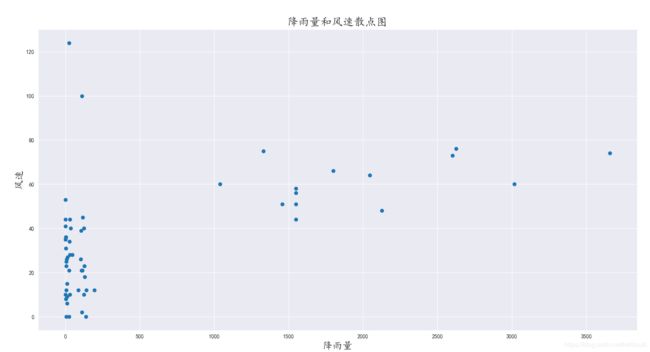
结果:
(1)对数据进行清洗,获取有效数据并将其存入新的csv文件中
见之前写的:https://mp.csdn.net/postedit/101151156 https://mp.csdn.net/postedit/102918827
(2)统计降雨量为个位数,十位数,百位数,千位数的数量,从而决定分层抽样中每层抽取的数量
(3)以降雨量的位数进行分层,然后对每层进行等距抽样(本来打算分层抽样,但是样本数量几十万超界了,妥协选择了等距 抽样。但是仍然没有找到解决分层抽样数量超负荷的方法。)
(4)抽样的数据封装至DataFrame结构中,绘制散点图。
图片如下: